1.将序列分解为单独的变量
1.1问题
包含n个元素的元组或列表、字符串、文件、迭代器、生成器,将它分解为n个变量
1.2方案
直接通过赋值操作
要求:变量个数要等于元素个数

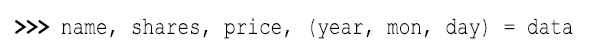

当执行分解操作时,有时需要丢弃某些特定的值,通常选一个用不到的变量来赋值就可以了
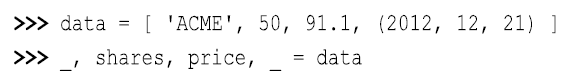
其中_代表不用的变量
2.从任意长度的可迭代对象中分解元素
问题:需要从可迭代的对象中分解n个值,但可迭代对象可能超过n,这就会导致‘too many values to unpack’的异常
解决:*表达式

注意:*变量 输出的是列表
如果*变量 放在第一个位置,那么会将前len(n)-1个值赋给*变量,最后一个值赋给其他变量




2.保存最后n个元素
|
1
2
3
4
5
6
7
8
9
|
from collections import deque#保存有限的历史记录,保存最新的n个元素,#deque(maxlen=N)创建了一个固定长度的队列,当有新记录加入队列而队列已满,会自动移除最老的记录或元素q=deque(maxlen=3)q.append(1)q.append(2)q.append(3)<br>#队列已满q.append(4)q.append(5) |
print(q)
3.找到最大和最小的n个元素
3.1 n=1
max,min
3.2 n<<N #要找的元素个数n 远远小于 元素总数N
|
1
2
3
4
5
6
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]heapq.heapify(nums) #进行堆排序,并更新原列表print(nums)#堆最重要的特性是nums[0]永远是最小的那个元素print(heapq.heappop(nums)) #弹出最小的nums[0],并以第二小的元素取而代之 |
3.3 n<N #要找的元素个数n 相对小于 元素总数N
|
1
2
3
4
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]print(heapq.nlargest(3,nums))print(heapq.nsmallest(3,nums)) |
3.4 n<N #要找的元素个数n 几乎接近 元素总数N
|
1
2
3
4
5
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]nums1= sorted(nums)[:7] #切出最小的7个元素nums2= sorted(nums)[-7:] #切出最大的7个元素print(nums1,nums2) |
4.根据列表中字典的key对列表进行筛选
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import heapqp=[{'name':'ibm','shares':100,'prices':91.11}, {'name':'apple','shares':50,'prices':543.31}, {'name':'t','shares':150,'prices':21.51}, {'name':'mi','shares':30,'prices':441.16}, {'name':'360','shares':10,'prices':61.81}, {'name':'car','shares':80,'prices':221.51}]#s:要排序的元素#s['prices']以元素的key=['prices']进行排序cheap=heapq.nsmallest(3,p,key=lambda s:s['prices'])expensive=heapq.nlargest(3,p,key=lambda s:s['prices'])print(cheap,'
',expensive) |
5.在两个字典中寻找相同点(集合的应用)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
a={ 'x':1, 'y':2, 'z':3}b={ 'w':10, 'x':11, 'y':2}#find keys in commonc=a.keys()& b.keys()print(c)#find keys in a that are not in bd=a.keys() - b.keys()print(d)#find keys,values in commone=a.items()& b.items()print(e) |
6.不排序且不改变原列表,实现列表有序5种方法

方法一:
思路:使用集合,对原集合和新产生的最小值集合取差集,每次取差集的最小值,插入新集合的首位。
代码实现:
|
1
2
3
4
5
6
7
|
l1=[99,999,-5,-66,-25,663,3]l2=[] #存每次找到的最小值for i in range(len(l1)): a=set(l1)-(set(l1)&set(l2)) l2.insert(0,min(a))l2=list(l2)print(l2) |
方法二:
思路:1.最小值寻找思路:首先找出最大值,并赋值给最小值变量,循环列表的每个元素,当有元素小于当前最小变量,则把该元素重新赋值给最小变量,这样就得到了一个列表的最小值。
2.整体思路:将最小值插入到新列表,重复1,在循环中加判断,如果元素不是已经找过的最小值(已添加到新列表中),则执行找最小值的循环
代码实现:
|
1
2
3
4
5
6
7
8
9
10
|
li1=[1,3,66,5,4,-1,-100,54]li2=[]for j in range(len(li1)): m=max(li1) for i in li1: if i not in li2: if i <m: m=i li2.insert(0,m)print(li2) |
方法三:
思路:1.寻找最小值,让最小值变量等于列表的第一个元素(且不是已经找到的最小值,即不属于列表l2,如果属于列表l2,则跳过该元素),循环整个列表,
如果有元素(该元素也不能是已找到的最小值,如果是,则跳过)小于当前最小值,则把该元素赋值给最小值。
2.本程序是根据列表元素的索引判断是否是已经找到的最小值
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def tiaoguo(s): #跳过已找过的索引 if s in l3: return 'y'l1=[99,999,-5,-66,-25,663,3]l2=[] #存每次找到的最小值l3=[] #存已使用的索引c=l1[0] #for j in range(len(l1)): for i in range(len(l1)-j): if len(l2)==len(l1): break if tiaoguo(i)=='y': #遇到已经找过的最小值,进行跳过处理 continue if c>l1[i]: c=l1[i] l2.insert(0,c) l3.append(l1.index(c)) #把最小值的索引存在l3中 for k in range(len(l1)): #更新最小值 if tiaoguo(k)=='y': continue else: c=l1[k]print(l2) |
方法四:
思路:方法四和方法三整体思路一致,是方法三的改进版。
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def list_sort(l1): l2=[] the_num = [] while (len(l1)>len(the_num)): temp = max(l1) #避免了方法三中首次给最小值变量赋值可能出现该值是已经找到的最小值的情况,因为max(l1)只有最后一次才会出现在l2中 for i in range(len(l1)): if i in the_num: # 如果是已经找到的最小值的索引,则continue continue if l1[i] <= temp: temp = l1[i] num = i the_num.append(num) l2.insert(0,temp) return l2if __name__ == '__main__': l1 = [1, 3, 66, 5, 4, -1, -100, 54] result = list_sort(l1) print(result) |
方法五:
思路:本程序是根据下一次寻找的最小值是大于上一次寻找的最小值(列表lis2[0]),且是所有大于lis2[0]的元素中的最小值。
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def sour(lis1, lis2): xia = lis2[0] for i in range(len(lis1)): if lis2[0] < lis1[i]: xia = lis1[i] # 所有大于list[0]的数 for j in range(len(lis1)): if lis1[j] > lis2[0] and lis1[j] < xia: # 找到大于lis2[0]最小的数 xia = lis1[j] return xia<br>lis1 = [3, 44, 55, 2, 45, 98, 99, -1, -4, 0, -98, -65]lis2 = []lis2.append(min(lis1))for i in range(len(lis1)-1): lis2.insert(0, sour(lis1, lis2))print(lis2) |