学号 20162309《程序设计与数据结构》第七周学习总结
教材学习内容总结
关于树:数并不是一个线性结构,其元素组织为一个层次结构。树状图是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个节点有零个或多个子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树;树(tree)是包含n(n>0)个结点的有穷集,其中:
(1)每个元素称为结点(node);
(2)有一个特定的结点被称为根结点或树根(root)。
(3)除根结点之外的其余数据元素被分为m(m≥0)个互不相交的集合T1,T2,……Tm-1,其中每一个集合Ti(1<=i<=m)本身也是一棵树,被称作原树的子树(subtree)。
树也可以这样定义:树是由根结点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的结点,所定义的关系称为父子关系。父子关系在树的结点之间建立了一个层次结构。在这种层次结构中有一个结点具有特殊的地位,这个结点称为该树的根结点,或称为树根。
我们可以形式地给出树的递归定义如下:
单个结点是一棵树,树根就是该结点本身。
设T1,T2,..,Tk是树,它们的根结点分别为n1,n2,..,nk。用一个新结点n作为n1,n2,..,nk的父亲,则得到一棵新树,结点n就是新树的根。我们称n1,n2,..,nk为一组兄弟结点,它们都是结点n的子结点。我们还称T1,T2,..,Tk为结点n的子树。
空集合也是树,称为空树。空树中没有结点。
(1)无序树:树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树;
(2)有序树:树中任意节点的子结点之间有顺序关系,这种树称为有序树;
(3)二叉树:每个节点最多含有两个子树的树称为二叉树;
(4)完全二叉树
(5)满二叉树
(6)霍夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
树的遍历(遍历二叉树的几种方法):

二叉树概念图及分类情况:
1 满二叉树和完全二叉树
上图就是典型的二叉树,其中左边的图还叫做满二叉树,右边是完全二叉树。然后我们可以得出结论,满二叉树一定是完全二叉树,但是反过来就不一定。满二叉树的定义是除了叶子结点,其它结点左右孩子都有,深度为k的满二叉树,结点数就是2的k次方减1。完全二叉树是每个结点都与深度为k的满二叉树中编号从1到n一一对应。
2 树的深度
树的最大层次就是深度,比如上图,深度是4。很容易得出,深度为k的树,拥有的最大结点数是2的k次方减1。
如何判断树是否平衡?
有关平衡树的定义:平衡二叉树(Balanced Binary Tree)具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
平衡二叉树的常用算法:红黑树、AVL、Treap、伸展树、SBT
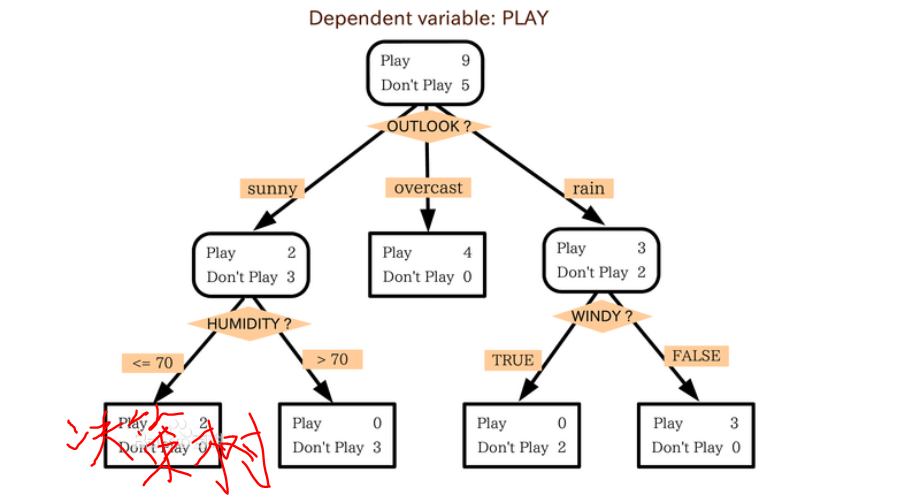
决策树
定义:决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
组成:
(1)决策点,是对几种可能方案的选择,即最后选择的最佳方案。如果决策属于多级决策,则决策树的中间可以有多个决策点,以决策树根部的决策点为最终决策方案。
(2)状态节点,代表备选方案的经济效果(期望值),通过各状态节点的经济效果的对比,按照一定的决策标准就可以选出最佳方案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出现的自然状态数目每个分枝上要注明该状态出现的概率。
(3)结果节点,将每个方案在各种自然状态下取得的损益值标注于结果节点的右端。
基本画法:
教材学习中的问题和解决过程
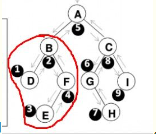
- 问题1:后序、中序遍历二叉树,如何由一个已知遍历结果得出二叉树的原本结构?
- 问题1解决方案:辨析遍历结果,结合几种遍历方法进行逆推,如中序遍历, 原则:访问左子树。【先访问左子树中的左子树,再访问左子树中的右子树。】直到访问到叶子结点后输出。
输出根。
访问右子树。【先访问右子树中的左子树,再访问右子树中的右子树。】直到访问到叶子结点后输出。


- ...
代码调试中的问题和解决过程
- 问题1:课上代码练习,关于Caesar密码的变化Key,运行课本Codes代码,在运行过程中,改变了deque变量方法后,调整为add和remove运行失败。
- 问题1解决方案:当队列中的第一个元素为空时,使用remove方法会抛出异常。

- ...
代码托管
https://gitee.com/pdds2017/xty20162309-JavaFoundations2nd
(statistics.sh脚本的运行结果截图)
上周考试错题总结
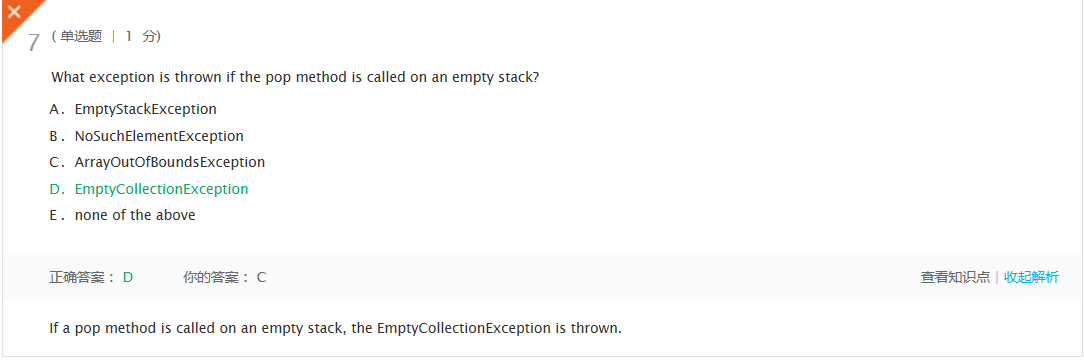
- 错题1及原因,理解情况
:
-错题2及原因
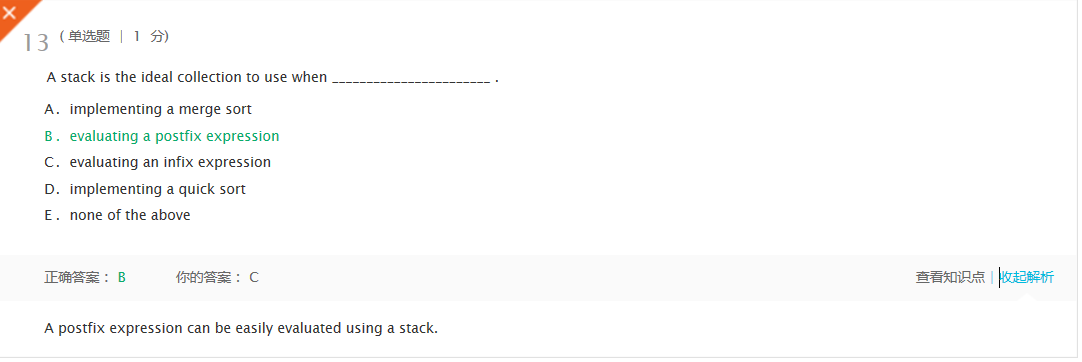
- ...
结对及互评
本周与20162313苑洪铭同学共同学习了队列的实现和树的相关知识,同时跟进了团队博客的进程。
本周结对学习情况
- [结对同学学号1](博客链接)
- 结对照片
- 结对学习内容
- 队列的使用,树的理解,二叉树的相关性质及遍历方法。
- ...
其他(感悟、思考等,可选)
综合这两周的学习,学习了有关栈、队列、以及树的相关知识,分析这几者之间的联系和区别,进行总结:
栈是一端受限,一段允许进行操作的线性表。我自己理解时,会将它理解成一个装书的盒子。放书,取书,就是进行的操作。这个的特点就是,你放了一踏书,现在你想取书,你只能先把上面的书一个个取出来,即:先放的后取,后放的先取。放在栈上说,就是先进后出。
逻辑结构:线性表。它是线性的。
存储结构:最常采用的是顺序存储和链式存储。
队列:是一种限定性的线性表,抽象到队列上说,有队头,队尾,要想加入(入队),只能从队尾加,想走(出队),只能从队头走。即:先进先出。
和栈一样,它常见的两种存储是顺序存储和链式存储。
用顺序存储时,会遇到这样的情况,数组并没有满,却入不了队(假溢出),原因在于队头没有在数组的0下标处。一般情况下,因为队列会存在假溢出的情况,所以采用循环队列。
在测试类的编写上,使用链表和数组都可以实现栈和队列,在编译上也有相似的地方。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第六周 | 456/456 | 2/2 | 20/20 | |
| 第七周 | 323/323 | 3/3 | 18/38 | |
| 第八周 | 500/1000 | 3/7 | 22/60 | |
| 第九周 | 300/1300 | 2/9 | 30/90 |
-
计划学习时间:14小时
-
实际学习时间:14小时
-
...