本人python 小菜比 一枚。拜读业界典范~~
阅读sqlmap 的版本是1.1.6,目前应该是最新版。
sqlmap.py 脚本中 72~83
def modulePath(): """ This will get us the program's directory, even if we are frozen using py2exe """ try: _ = sys.executable if weAreFrozen() else __file__ except NameError: _ = inspect.getsourcefile(modulePath) return getUnicode(os.path.dirname(os.path.realpath(_)), encoding=sys.getfilesystemencoding() or UNICODE_ENCODING)
modulePath 按照名字来看,应该是和路径相关的。
sys.executable 获取当前python 解释器路径。
__file__ 相对路径下执行获得相对路径,绝对路径下执行获得绝对路径。
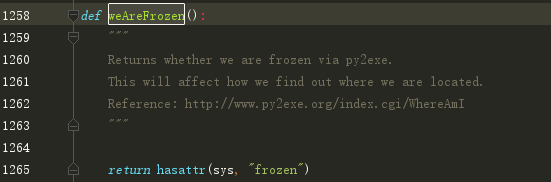
weAreFrozen() 这个函数在这里,hasattr 获取sys 中是否存在这个frozen属性,返回一个布尔值。
文件在这里:lib/core/common.py 代码如下:
小技巧:Python获得自己的绝对路径
Python中有个魔术变量可以得到脚本自身的名称,但转换成exe后该变量失效,这时得改用sys.executable获得可执行程序的名称,可用hasattr(sys, "frozen")判断自己是否已被打包,下面是一个方便取绝对路径的。
为了搞明白,然后做了测试。

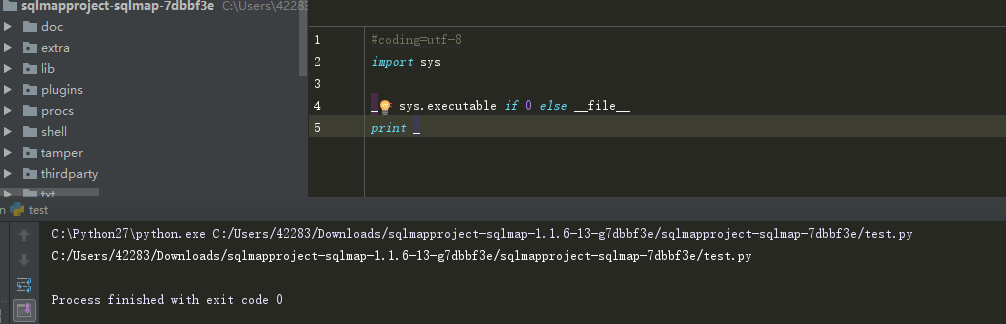
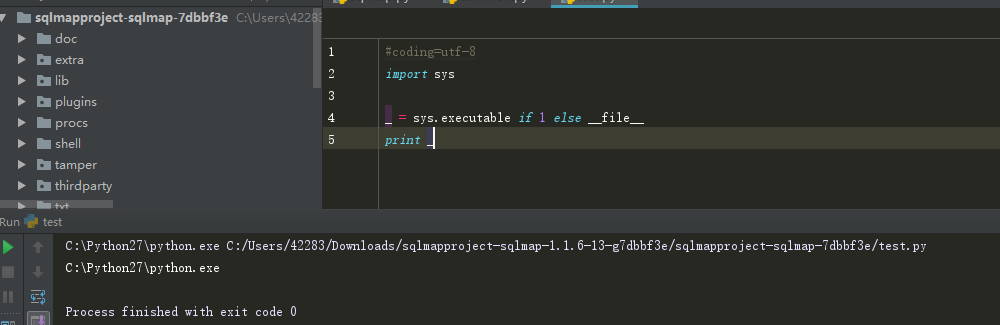
继续更新了,周末更新好,结果手一抖关了。真糗。
翻页看的太累了。代码如下:
def modulePath(): """ This will get us the program's directory, even if we are frozen using py2exe """ try: _ = sys.executable if weAreFrozen() else __file__ except NameError: _ = inspect.getsourcefile(modulePath) return getUnicode(os.path.dirname(os.path.realpath(_)), encoding=sys.getfilesystemencoding() or UNICODE_ENCODING)
inspect.getsourcefile(modulePath) 查找modulePath的导入路径。
return getUnicode(os.path.dirname(os.path.realpath(_)), encoding=sys.getfilesystemencoding() or UNICODE_ENCODING)
os.path.dirname(os.path.realpath(_)) 返回绝对路径
sys.getfilesystemencoding() 本地编码
UNICODE_ENCODING 这个需要找到 lib/core/settings.py 中的

getUnicode:
文件在这里:lib/core/common.py 代码如下:
def getUnicode(value, encoding=None, noneToNull=False): """ Return the unicode representation of the supplied value: >>> getUnicode(u'test') u'test' >>> getUnicode('test') u'test' >>> getUnicode(1) u'1' """ if noneToNull and value is None: return NULL if isinstance(value, unicode): return value elif isinstance(value, basestring): while True: try: return unicode(value, encoding or (kb.get("pageEncoding") if kb.get("originalPage") else None) or UNICODE_ENCODING) except UnicodeDecodeError, ex: try: return unicode(value, UNICODE_ENCODING) except: value = value[:ex.start] + "".join(INVALID_UNICODE_CHAR_FORMAT % ord(_) for _ in value[ex.start:ex.end]) + value[ex.end:] elif isListLike(value): value = list(getUnicode(_, encoding, noneToNull) for _ in value) return value else: try: return unicode(value) except UnicodeDecodeError: return unicode(str(value), errors="ignore") # encoding ignored for non-basestring instances
看到亲切的注释,返回以unicode转换后的结果。
if noneToNull and value is None: return NULL
开始判断noneToNull和value 是否为空。
if isinstance(value, unicode): return value
然后isinstance python中内置方法,判断unicode类型。
elif isinstance(value, basestring): while True: try: return unicode(value, encoding or (kb.get("pageEncoding") if kb.get("originalPage") else None) or UNICODE_ENCODING) except UnicodeDecodeError, ex: try: return unicode(value, UNICODE_ENCODING) except: value = value[:ex.start] + "".join(INVALID_UNICODE_CHAR_FORMAT % ord(_) for _ in value[ex.start:ex.end]) + value[ex.end:]
其次basestring检查unicode对象。
红色标记是没看懂的。
encoding or (kb.get("pageEncoding") if kb.get("originalPage") else None) or UNICODE_ENCODIN
value = value[:ex.start] + "".join(INVALID_UNICODE_CHAR_FORMAT % ord(_) for _ in value[ex.start:ex.end]) + value[ex.end:]
elif isListLike(value): value = list(getUnicode(_, encoding, noneToNull) for _ in value) return value
再次遍历列表,通过递归getUnicode批量转换编码。
else: try: return unicode(value) except UnicodeDecodeError: return unicode(str(value), errors="ignore") # encoding ignored for non-basestring instances
最后unicode转码返回,并且忽略错误。
将不懂部分搞明白,再继续。