机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
关键字:k-均值、kMeans、聚类、非监督学习
作者:米仓山下
时间:2018-11-3
机器学习实战(Machine Learning in Action,@author: Peter Harrington)
源码下载地址:https://www.manning.com/books/machine-learning-in-action
git@github.com:pbharrin/machinelearninginaction.git
*************************************************************
一、k-均值聚类算法(kMeans)原理
聚类是一种无监督学习,它将相似的对象归到同一个簇中。K-均值聚类算法以k个随机质心开始。算法会计算每个点到质心的距离。每个点会被分到距其最近的簇质心,然后紧接着基于新分配到簇的点更新质心。以上过程重复数次,直到质心不再改变。这个简单地算法非常有效但是容易受到初始质心的影响。
为了获得更好的的聚类结果,可以使用另一种称为二分K-均值的聚类方法。二分K-均值首先将所有点作为一个簇,然后使用K-均值聚类(k=2)对其划分。下一次迭时,选择有最大误差的簇进行划分。该过程直到k个簇创建成功为止。二分K-均值的聚类效果要好于K-均值聚类。
*************************************************************
二、k-均值聚类(kMeans)
算法:
输入:dataSet——待聚类的数据集;k——要聚类的簇的个数;distMeas——计算距离的函数,默认为欧式距离函数distEclud;createCent——创建质心的函数,默认为randCent;
输出:centroids——各个簇的质心;clusterAssment——存储最小距离平方和对应质心索引
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2))) #构造m×2矩阵,用来存储最小距离平方和对应质心索引
centroids = createCent(dataSet, k) #初始化质心
clusterChanged = True
while clusterChanged: #质心不再改变时结束
clusterChanged = False
for i in range(m): #遍历每个点
minDist = inf; minIndex = -1
for j in range(k): #计算该点到每个质心的距离
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist: #最小距离和对应质心索引
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True #所属类别变化
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k): #更新质心位置
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #提取标签为cent的数据
centroids[cent,:] = mean(ptsInClust, axis=0) #ptsInClust的列平均值,axis=0 列方向
return centroids, clusterAssment
其他函数:
loadDataSet(fileName)——构造数据,读取文件中的数据矩阵
distEclud(vecA, vecB)——计算两个向量的欧式距离
randCent(dataSet, k)——根据给定的数据,在其取值边界内随机构造k个质心
-------------------------------------------------
测试:
>>> import kMeans
>>> data=kMeans.loadDataSet('testSet.txt')
>>> from numpy import *
>>> centpoint,cluster=kMeans.kMeans(mat(data),4)
[[ 2.70503374 -1.42834359]
[-2.09874174 0.13175831]
[ 4.36781866 1.23667688]
[-1.57667561 -3.89341615]]
[[ 3.03713839 -2.62802833]
[-2.605345 2.35623864]
[ 2.6265299 3.10868015]
[-2.9085278 -3.11811235]]
[[ 2.80293085 -2.7315146 ]
[-2.46154315 2.78737555]
[ 2.6265299 3.10868015]
[-3.38237045 -2.9473363 ]]
>>>
*************************************************************
三、二分K-均值聚类(biKmeans)
一种用来度量聚类效果的指标SSE(误差平方和),SSE值越小表示数据点越接近他们的质心,聚类效果也越好。因为对误差取了平方,因此更加注重远离中心的点。通过增加簇的个数来降低SSE值。
克服K-均值算法收敛于局部最小值的问题,出现了二分K-均值聚类算法。首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续划分,选择哪一个簇进行划分取决于对其划分知否可以最大程度降低SSE的值。对上述过程不断重复,直到达到指定的簇数目为止。
算法:
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] #创建一个初始簇
for j in range(m): #每个点到质心的距离
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k): #簇个数不满足给定数目
lowestSSE = inf #寄存较小的SSE值
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #取出i簇的数据
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) #将该簇分为两簇0和1
sseSplit = sum(splitClustAss[:,1]) #比较前后的SSE值
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE: #该种分法SSE降低了
bestCentToSplit = i #记录下切分的簇
bestNewCents = centroidMat #簇质心,两个
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit #寄存较小的SSE值
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #更新簇分配结果,centList增加一簇
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #更新簇分配结果
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #更新簇质心
centList.append(bestNewCents[1,:].tolist()[0]) #更新簇质心
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss #更新clusterAssment
return mat(centList), clusterAssment
测试:
>>> reload(kMeans)
<module 'kMeans' from 'kMeans.py'>
>>> data=kMeans.loadDataSet('testSet2.txt')
>>> centList,mycluster=kMeans.biKmeans(mat(data),3)
sseSplit, and notSplit: 453.0334895807502 0.0
the bestCentToSplit is: 0
the len of bestClustAss is: 60
sseSplit, and notSplit: 77.59224931775066 29.15724944412535
sseSplit, and notSplit: 12.753263136887313 423.8762401366249
the bestCentToSplit is: 0
the len of bestClustAss is: 40
>>> centList
matrix([[-2.94737575, 3.3263781 ],
[-0.45965615, -2.7782156 ],
[ 2.93386365, 3.12782785]])
>>>
*************************************************************
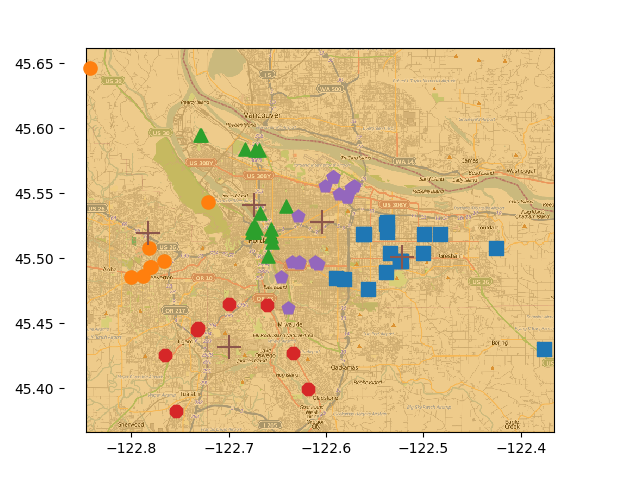
四、示例:在地图上的点聚类
places.txt文件中有70行数据,每行数据包括了地址、坐标等信息,其中第四、第五列是坐标信息
将这些点按照坐标远近分为5簇
其中距离的计算用到了地球表面球面距离
最后将其绘制按照不同颜色绘制出来
>>> kMeans.clusterClubs()
sseSplit, and notSplit: 3431.621150997616 0.0
the bestCentToSplit is: 0
the len of bestClustAss is: 69
sseSplit, and notSplit: 1230.242092830394 1062.0271973840918
sseSplit, and notSplit: 515.6100923704457 2369.5939536135247
the bestCentToSplit is: 0
the len of bestClustAss is: 53
sseSplit, and notSplit: 318.6390236086656 1892.3442135982214
sseSplit, and notSplit: 515.6100923704457 1230.242092830394
sseSplit, and notSplit: 471.8115196045904 1461.9522740003558
the bestCentToSplit is: 1
the len of bestClustAss is: 16
sseSplit, and notSplit: 197.38636407063862 1345.9271085845755
sseSplit, and notSplit: 53.299046126034725 1437.9528665515088
sseSplit, and notSplit: 549.8565865332125 915.5351689867098
sseSplit, and notSplit: 109.50254173619503 1538.1414114797253
the bestCentToSplit is: 2
the len of bestClustAss is: 35
*************************************************************