一、获取到网络上的网页
from bs4 import BeautifulSoup import requests url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html' web_data = requests.get(url) soup = BeautifulSoup(web_data.text,'lxml') print(soup)

二、获取想要的数据
from bs4 import BeautifulSoup import requests url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html' web_data = requests.get(url) soup = BeautifulSoup(web_data.text,'lxml') titles = soup.select('#taplc_attraction_coverpage_attraction_0 > div:nth-of-type(1) > div > div > div.shelf_item_container > div:nth-of-type(1) > div.poi > div > div.item.name > a') print(titles)
但不是所有的,使用下面的方式获取所有
from bs4 import BeautifulSoup import requests url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html' web_data = requests.get(url) soup = BeautifulSoup(web_data.text,'lxml') titles = soup.select('div.item.name') imgs = soup.select('img[width="200"]') cates = soup.select('div.poi > div > div:nth-of-type(3)') #taplc_attraction_coverpage_attraction_0 > div:nth-child(1) > div > div > div.shelf_item_container > div:nth-child(4) > div.poi > div > div:nth-child(3) # print(titles,imgs,cates,sep=' ----------- ') #验证下 # for title in titles: # print(title.get_text()) # for img in imgs: # print(img.get('src')) # for cate in cates: # print(cate.get_text()) for title,img,cate in zip(titles,imgs,cates): data={ 'title':title.get_text(), 'img':img.get('src'), 'cate':list(cate.stripped_strings), } print(data)
二、伪造登陆
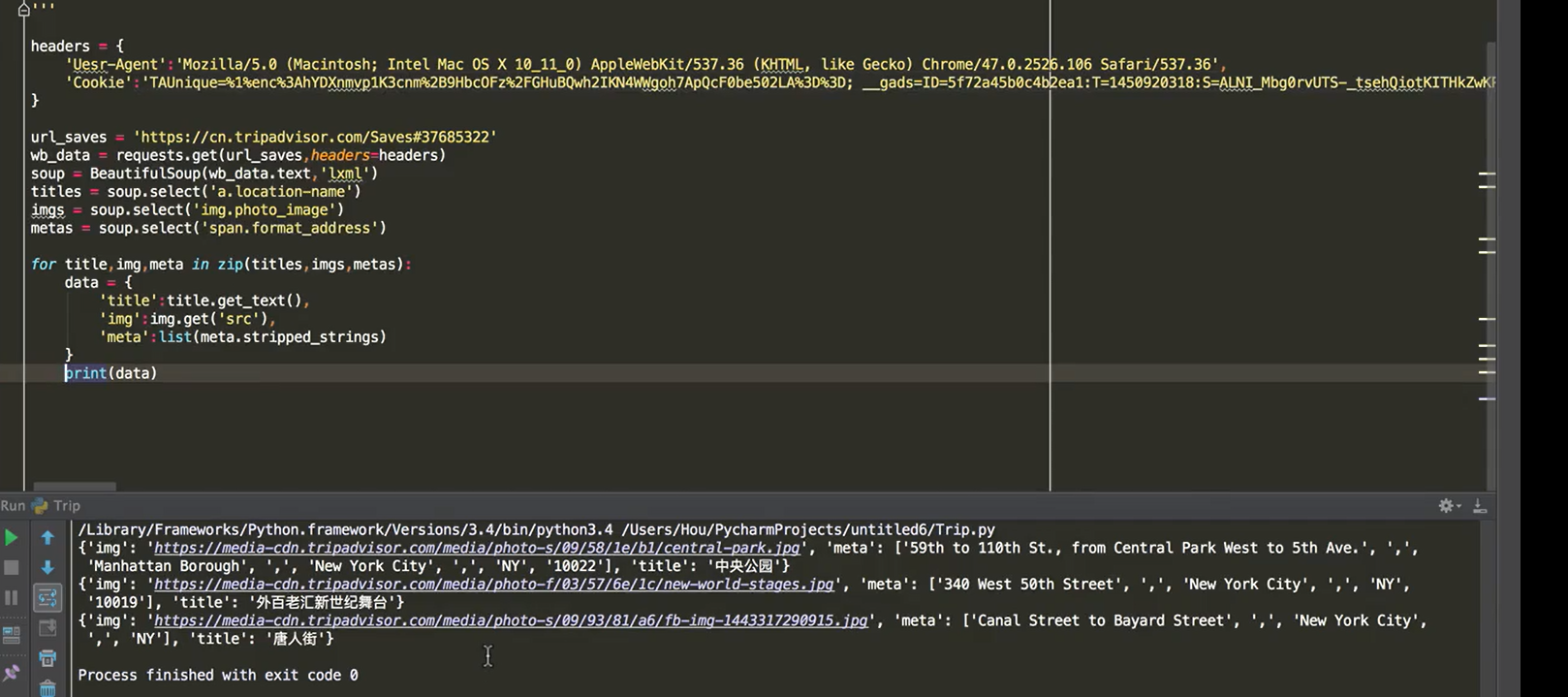
三、爬取多个网页



四、应对js-爬取手机端