第二次作业
| 这个作业属于哪个课程 | 2019学年02学期单红老师软件工程实践 |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2)链接 |
| 这个作业的目标 | 1. 掌握GitHub的使用 2. 制定代码规范 3. 提高需求分析 4. 学习单元测试的基础理论和相应技术 |
| 作业正文 | 本博客 |
| 其他参考文献 | 1. Git教程|菜鸟教程 2. 现代软件工程讲义 2 开发技术 - 单元测试 & 回归测试 3. Collator和Comparator 接口实现中文字符串排序 |
一、GitHub仓库地址
https://github.com/MingLL/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间 | 540 | 715 |
| Development | 开发 | 350 | 560 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 40 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 20 | 20 |
| Coding | 具体编码 | 200 | 300 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 60 | 90 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 540 | 715 |
三、解题思路描述
1.对用户输入的指令进行分析
首先分析参数,由于都是键值对形式。我想到用HashMap的形式存放数据。每一个参数和对应的值用一个HashMap的形式存放。存放方式如下
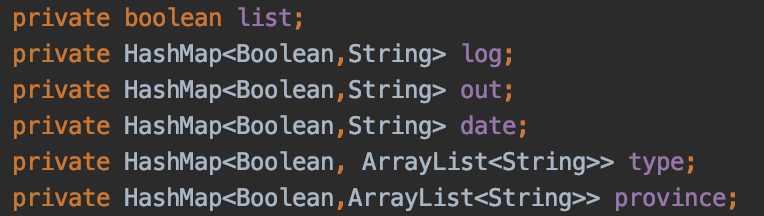
由于只有一个list命令,所以只用一个boolean值判断用户是否输入list命令从而判断命令是否输入正确。其他参数都是以键值对的形成存放并且判断用户是否输入。对于输入的命令就执行。
2.对统计文件的分析
每一个统计文件都是形如
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
所以想到用正则表达式对数据进行解析及对文件中每一行进行解读并获取数据。并将所读取到的数据存入下面对数据结构中

key的值为省份,value的值为数据内容--用键值对存储的数据信息
3.对输出内容的分析
每个输出内容都是形
1、全国 感染患者n人 疑似患者n人 治愈n人 死亡n人
2、<省份> 感染患者n人 疑似患者n人 治愈n人 死亡n人
并且省份按照首字母进行排序。所以我对我用来存储的data数据类型中key的值进行排序并且按照格式输出到文件中。
四、设计实现过程
由于只用一个类实现所有功能,写内部类会出现看代码的时候乱七八糟。所以我用函数调用的方式完成了此次作业。(ps:如果更好的维护代码,提高代码质量,应该类的方式完成上述功能)
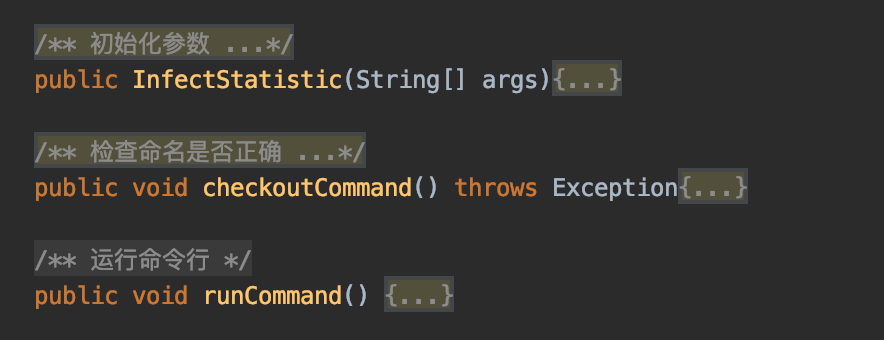
- 用户指令的分析和命令执行
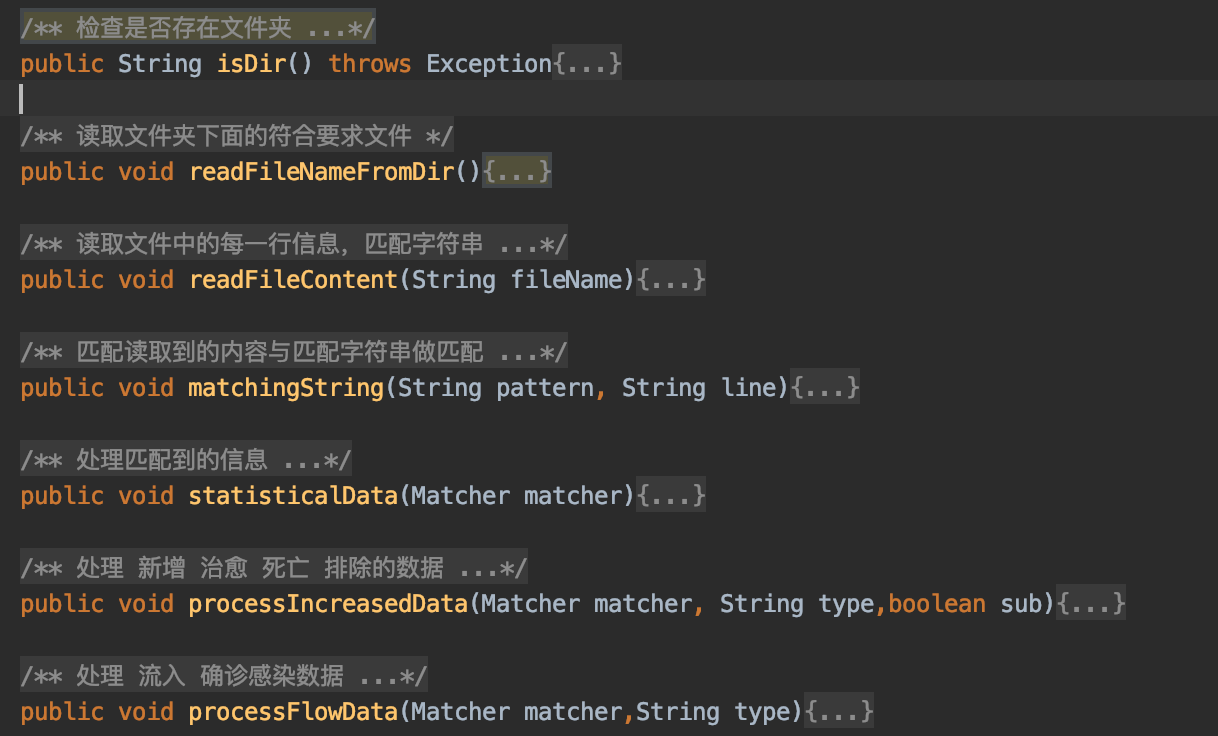
- 文件统计的实现
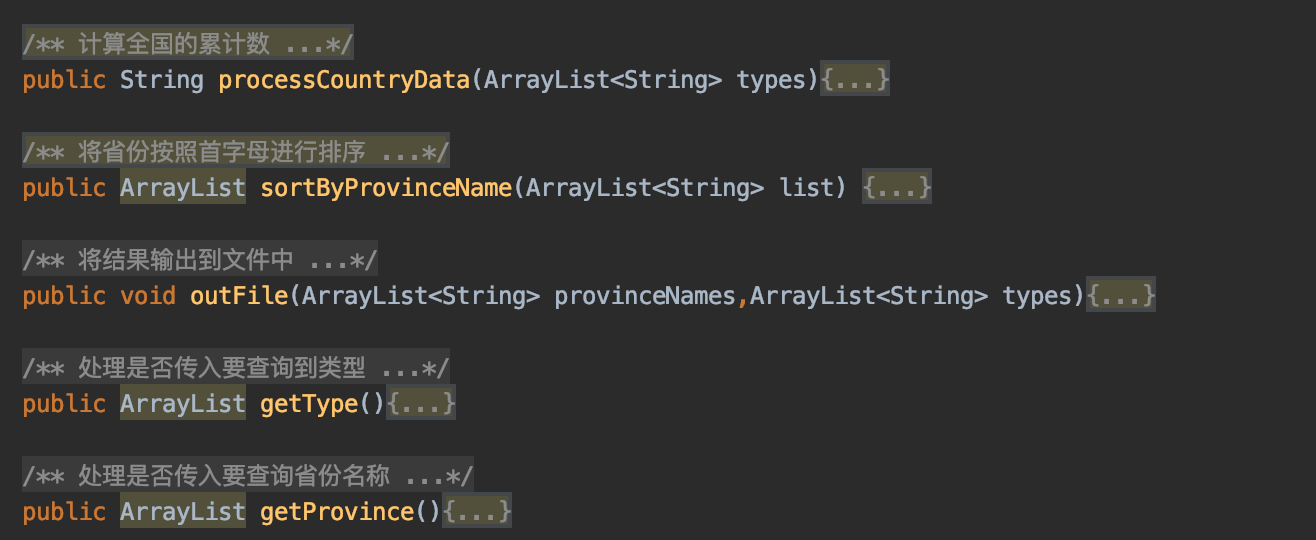
- 输出文件的实现
程序流程图
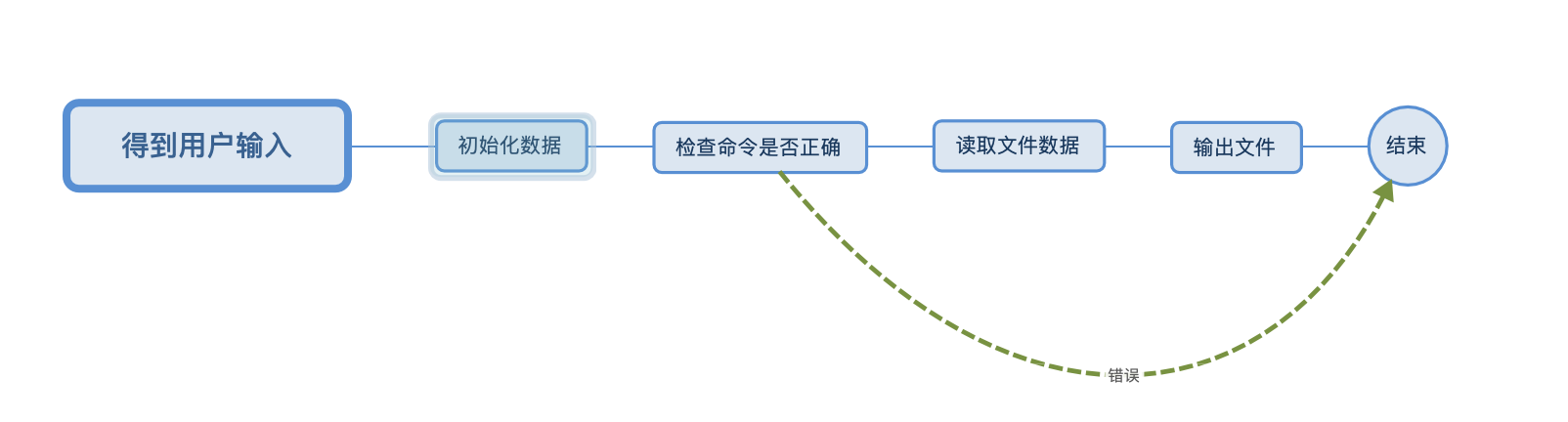
五、代码说明
1.初始化参数说明
public InfectStatistic(String[] args){
log = new HashMap<>();
out = new HashMap<>();
date = new HashMap<>();
type = new HashMap<>();
province = new HashMap<>();
data = new HashMap<>();
for(int i = 0; i<args.length;i++){
command += args[i] + " ";
switch (args[i]){
case "list":
list = true;
break;
case "-log":
log.put(true,args[i+1]);
break;
case "-out":
out.put(true,args[i+1]);
break;
case "-date":
if (i + 1 < args.length) {
if (this.checkTime(args[i + 1])){
date.put(true, args[i + 1]);
} else {
date.put(true,null);
}
}else {
date.put(true,null);
}
break;
case "-type":
i++;
ArrayList<String> tmp = new ArrayList<>();
while (i<args.length&&!(args[i].substring(0,1).equals("-"))){
tmp.add(args[i]);
i++;
}
type.put(true,tmp);
i--;
break;
case "-province":
i++;
ArrayList<String> pri = new ArrayList<>();
while (i<args.length&&!(args[i].substring(0,1).equals("-"))){
pri.add(args[i]);
i++;
}
province.put(true,pri);
i--;
break;
case "-web":
web = true;
break;
}
}
}
- 对每一个数据进行初始化。
- 对用户输入的参数进行解析
2.处理读入数据
由于新增 治愈 死亡 排除的数据和流入 确诊感染的数据,对信息对处理不一样所以分开两个函数来写
/**
* 处理 新增 治愈 死亡 排除的数据
* @param matcher 匹配到的匹配器
* @param type 患者类型
* @param sub 数据加减判断
*/
public void processIncreasedData(Matcher matcher, String type,boolean sub){
String provinceName = matcher.group(1);
if (sub) {
if (data.containsKey(provinceName)) {
HashMap<String, Integer> temp = data.get(provinceName);
int num = temp.get(type);
num += Integer.parseInt(matcher.group(2));
temp.put(type, num);
} else {
HashMap<String, Integer> temp = new HashMap<>();
temp.put("感染患者",0);
temp.put("疑似患者",0);
temp.put("治愈",0);
temp.put("死亡",0);
int num = Integer.parseInt(matcher.group(2));
temp.put(type, num);
data.put(provinceName,temp);
}
}else {
if (type.equals("疑似患者")) {
HashMap<String, Integer> temp = data.get(provinceName);
int num = temp.get(type);
num -= Integer.parseInt(matcher.group(2));
temp.put(type, num);
}else {
HashMap<String, Integer> temp = data.get(provinceName);
int num = temp.get(type);
num += Integer.parseInt(matcher.group(2));
temp.put(type, num);
int ipNum = temp.get("感染患者");
ipNum -= Integer.parseInt(matcher.group(2));
temp.put("感染患者",ipNum);
}
}
}
处理新增 治愈 死亡 排除的数据时候。根据传入参数sub判断是否加减。type判断是那个选项加减。
/**
* 处理 流入 确诊感染数据
* @param matcher 匹配到的匹配器
* @param type 患者类型
*/
public void processFlowData(Matcher matcher,String type){
if (matcher.groupCount()==2){
String provinceName = matcher.group(1);
HashMap<String,Integer> temp = data.get(provinceName);
int spNum = temp.get(type);
int num = Integer.parseInt(matcher.group(2));
spNum -= num;
temp.put(type,spNum);
int ipNum = temp.get("感染患者");
ipNum += num;
temp.put("感染患者",ipNum);
}else {
String provinceNameOut = matcher.group(1);
String provinceNameIn = matcher.group(2);
HashMap<String,Integer> out = data.get(provinceNameOut);
HashMap<String,Integer> in = data.get(provinceNameIn);
int outNum = out.get(type);
int inNum = in.get(type);
int num = Integer.parseInt(matcher.group(3));
outNum -= num;
inNum += num;
out.put(type,outNum);
in.put(type,inNum);
}
}
流入和疑似患者确诊的方法和上述方法不一样。需要对两个数据进行修改。并且流入和疑似患者处理的流程也不一样。对匹配器得到对参数进行判断。从而进行分析
3.处理输出文件
/**
* 将结果输出到文件中
* @param provinceNames 省份名称
* @param types 患者类型
*/
public void outFile(ArrayList<String> provinceNames,ArrayList<String> types){
String outFileName = out.get(true);
try {
FileOutputStream outputStream = new FileOutputStream(new File(outFileName));
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(outputStream,"utf8");
BufferedWriter writer = new BufferedWriter(outputStreamWriter);
if (provinceNames.contains("全国")) {
writer.write(processCountryData(types));
provinceNames.remove("全国");
}
Comparator<Object> com = Collator.getInstance(java.util.Locale.CHINA);
ArrayList<String> sortNames = this.sortByProvinceName(provinceNames);
for(String provinceName : sortNames){
if (provinceName.equals("冲庆")){
provinceName = "重庆";
}
String result = provinceName;
if(data.containsKey(provinceName)) {
HashMap<String, Integer> temp = data.get(provinceName);
for (String string : types) {
int num = temp.get(string);
result += " " + string + num + "人";
}
writer.write(result + "
");
} else {
for (String string : types) {
result += " " + string + 0 + "人";
}
writer.write(result);
}
}
writer.write("// 该文档并非真实数据,仅供测试使用
");
writer.write("// 命令 "+command);
writer.close();;
outputStreamWriter.close();
outputStream.close();
}catch (Exception e){
e.printStackTrace();
System.exit(-1);
}
}
在代码实现的过程中,对省份排序花费了一定的时间。在使用Collator排序时候发现重庆这个省份被排在了最后面,从网上查的结果后知道,重庆被认为成了重(zhong)庆,所以在排序时候,将重庆改为了冲庆,进行排序。才有了那段判断语句。排序方法的实现是建立了一个数组,对数组进行排序,在data中查找相应的省份输出。
六、单元测试截图和描述
- 测试错误参数
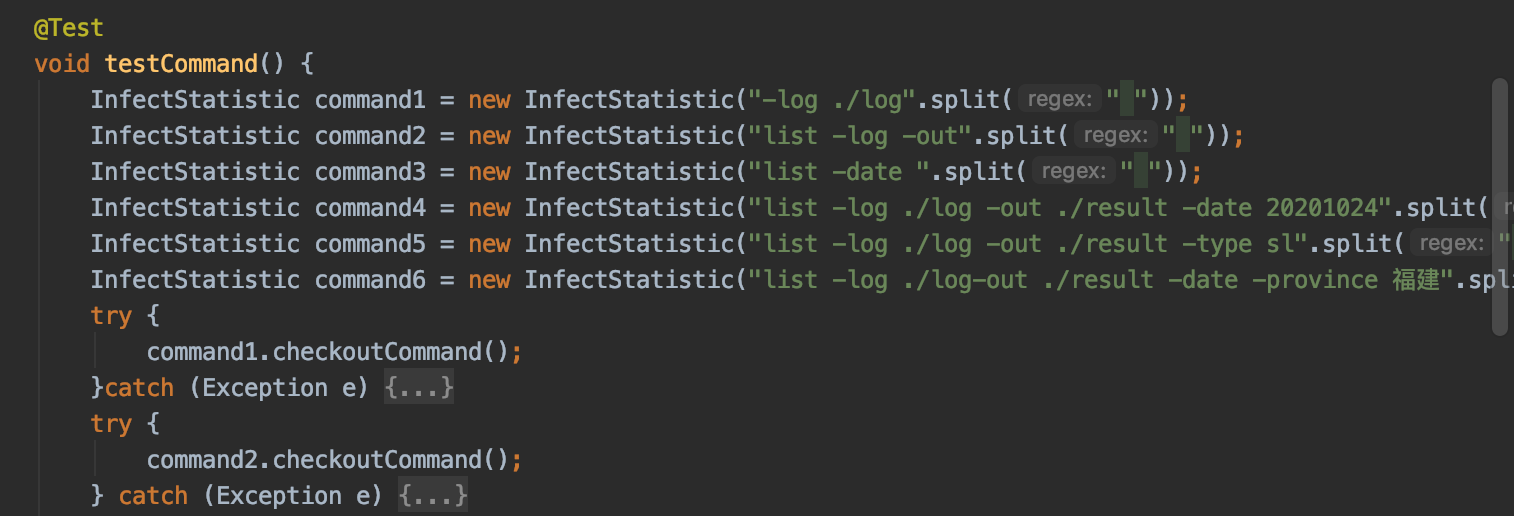
- 测试main函数
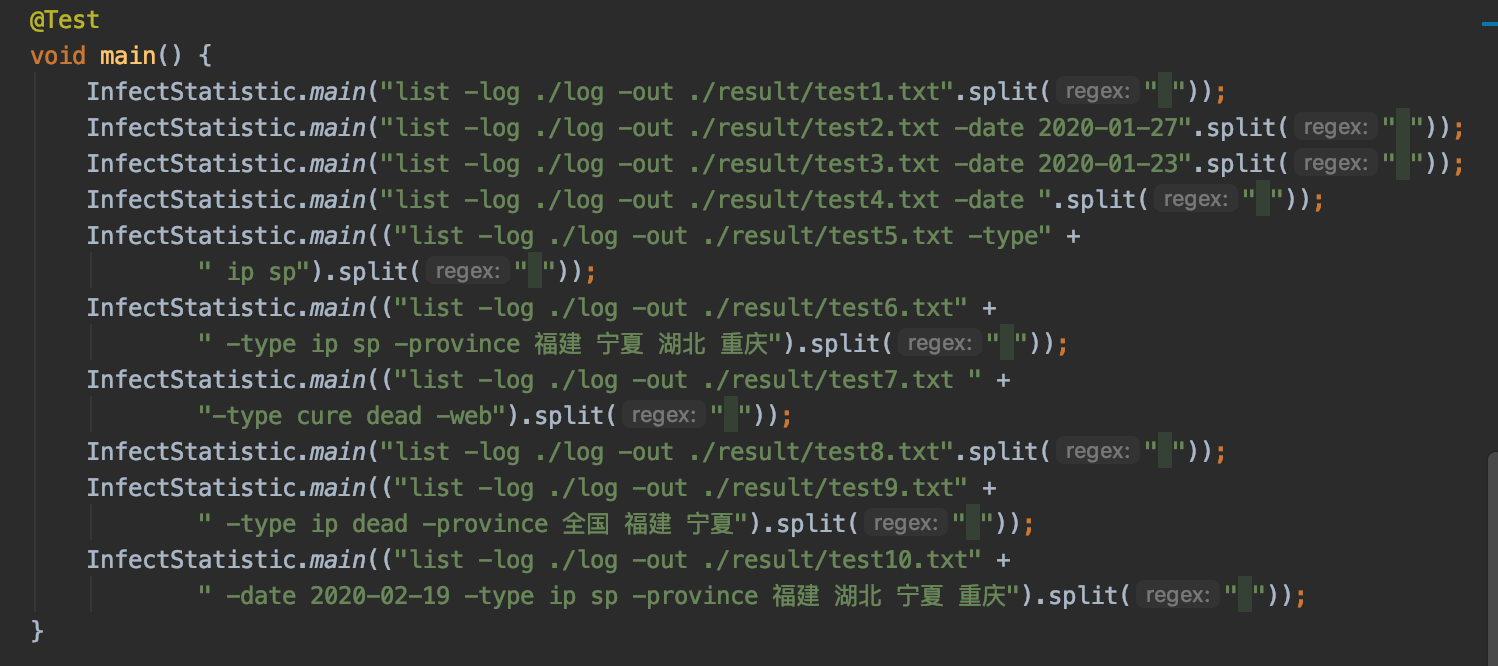
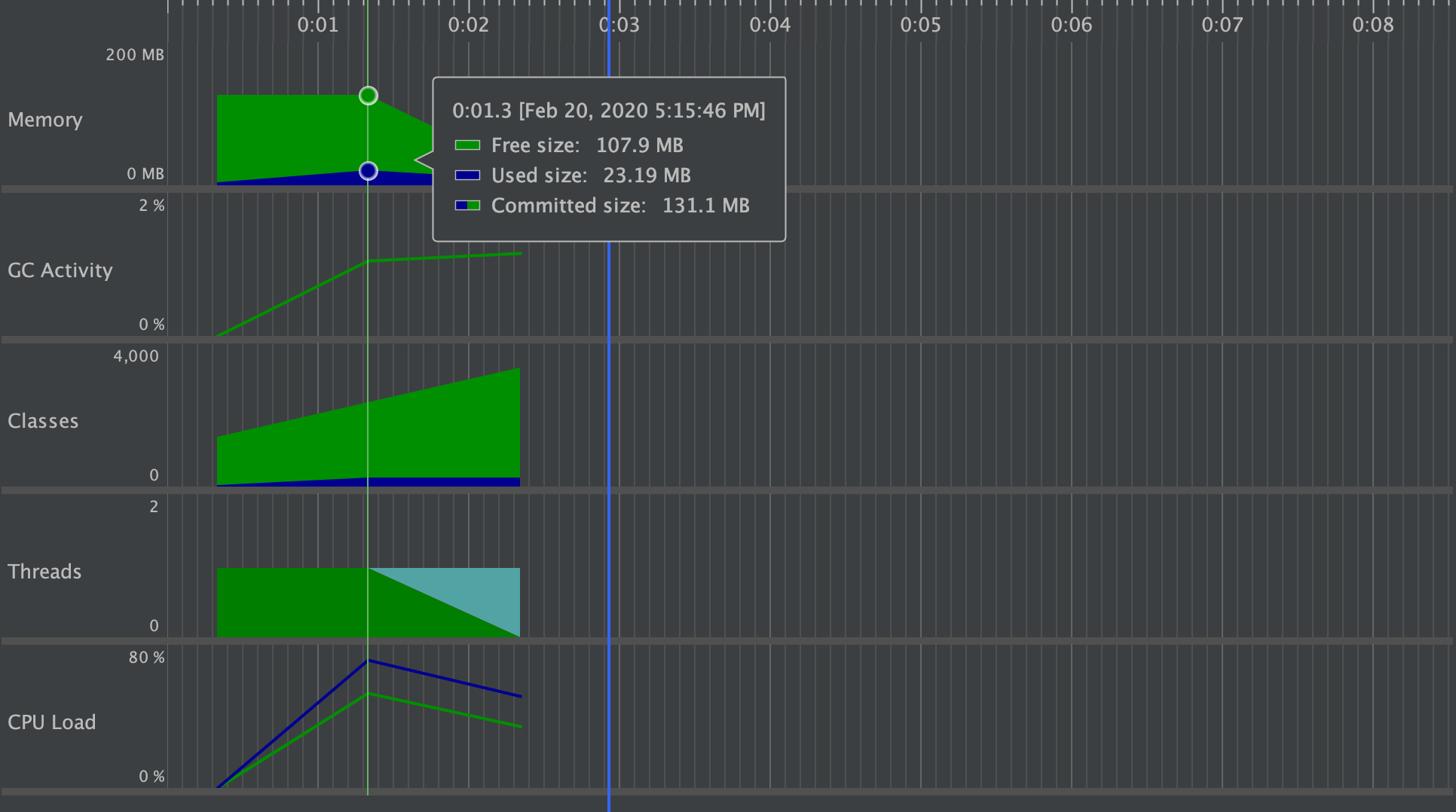
七、单元测试覆盖率优化和性能测试,性能优化截图和描述
- 代码覆盖率
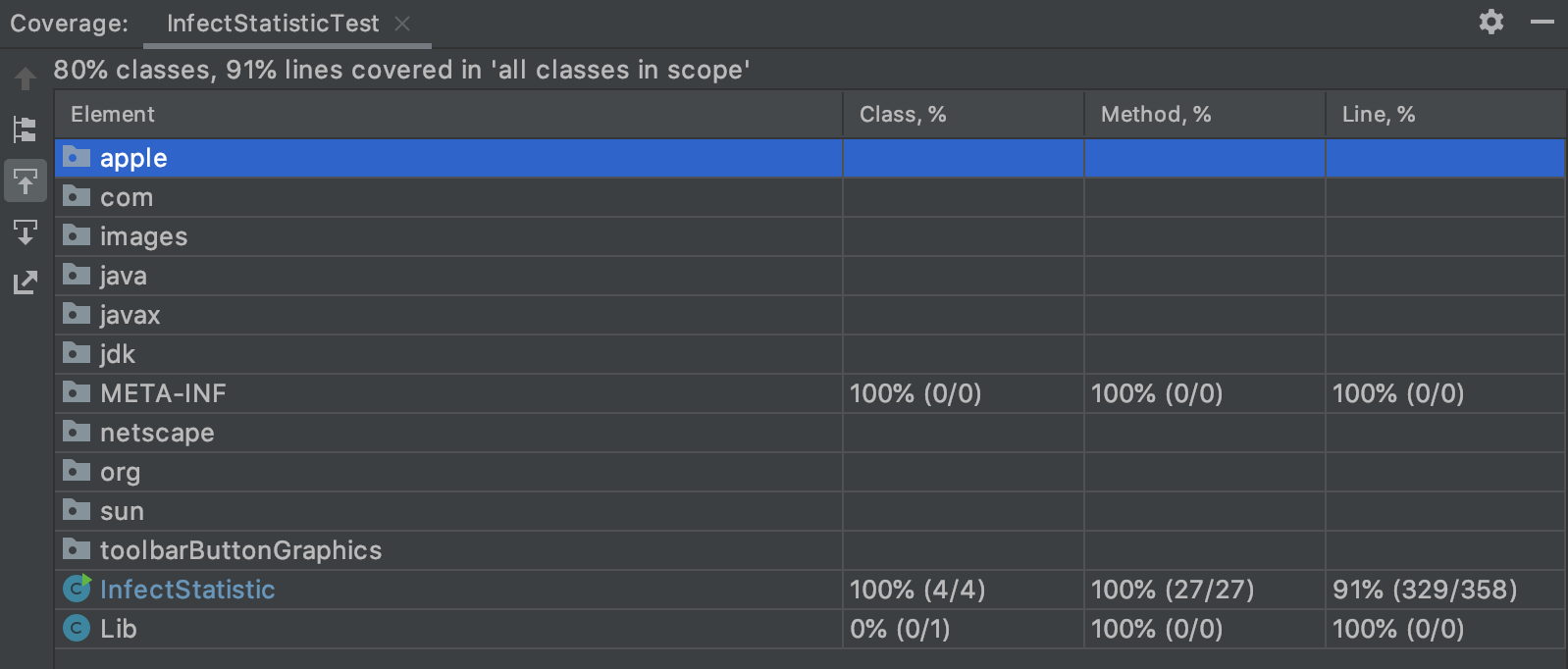
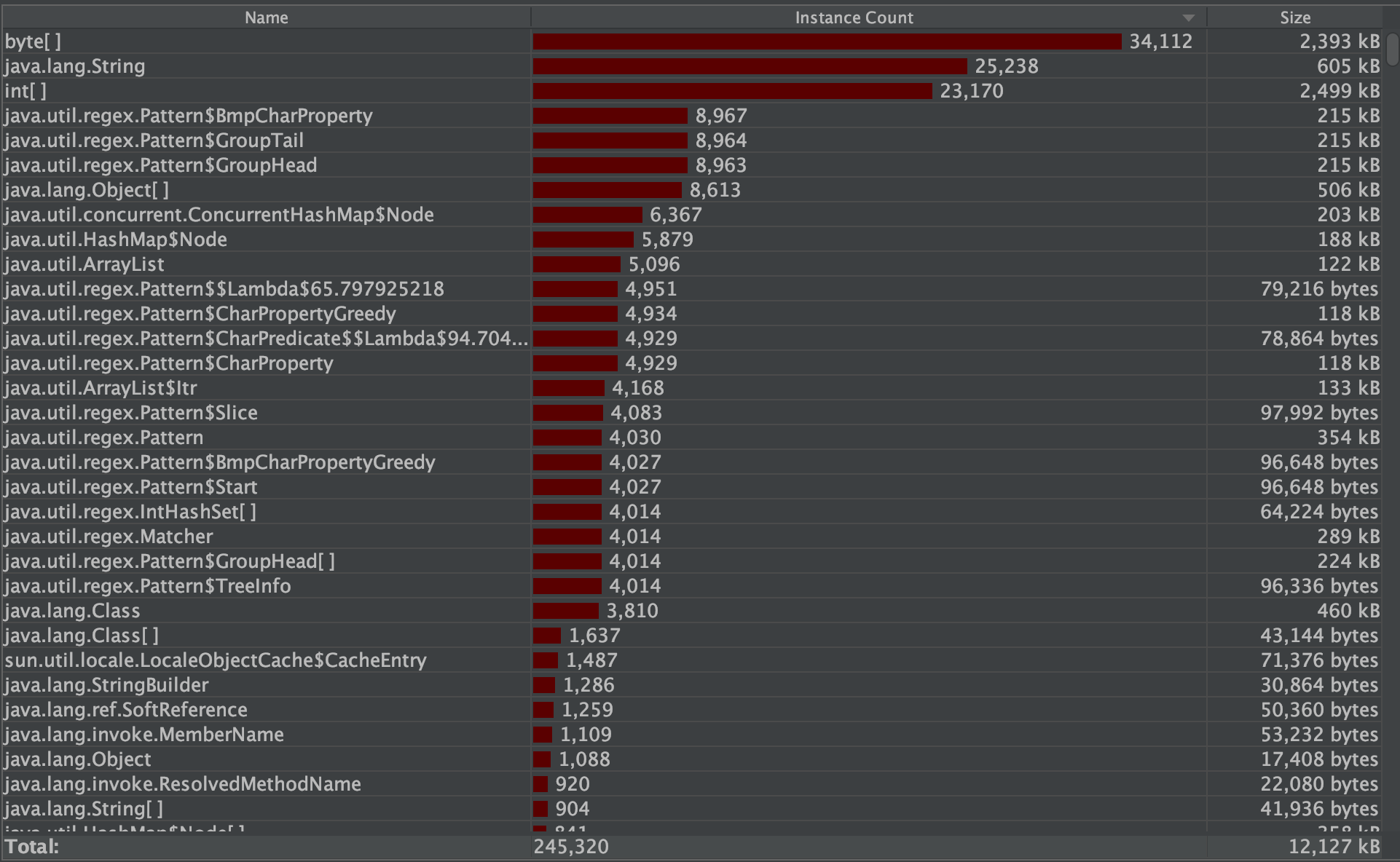
从上图可以看出,单元测试基本覆盖所有代码 - 性能测试
八、代码规范链接
https://github.com/MingLL/InfectStatistic-main/blob/master/051602129/codestyle.md
九、心路历程和收获
- 心路历程
看到本次作业这么长的说明的时候,内心有一点小小的紧张,沉下心来看的时候,内心中已经有了一下规划。开始一步一步的实现。在数据结构和算法的计划中,最开始想用数组来完成所有。但数组会增加代码量,有些使用也不是很方便。在分析结构的时候发现和字典很像,所以最后选用了HashMap。最后在测试但时候如果没有全国的数据,我觉得测试会有一些问题。所以实现了抓取网上的资源。由于不能使用第三方库读取JSON数据。在这个地方只是简单的抓去了自己想要的数据。
- 收获
- 学习到了git和github的基本使用方法。
- 一些简单的代码测试(ps:不知道其中的一些信息有什么用)
- 掌握了HashMap和Collator的使用
十、技术路线图相关的仓库
- JSONModel
链接:https://github.com/jsonmodel/jsonmodel
简介:读取JSON数据 - SnapKit
链接:https://github.com/SnapKit/SnapKit
简介:IOS自动布局框架 - RxSwift
链接:https://github.com/ReactiveX/RxSwift
简介:帮助我们简化异步编程的框架 - Pop
链接:https://github.com/facebook/pop
简介:Pop是iOS、tvOS和OS X的可扩展动画引擎 - SwiftTask
链接:https://github.com/ReactKit/SwiftTask
简介:有代表性的FRP框架,提供了异步顺序执行方案