ONE
1.PSP表格:

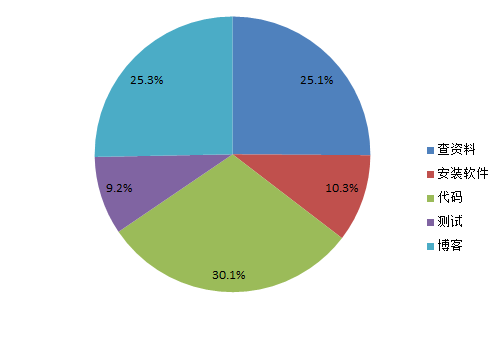
2.PSP饼状图:
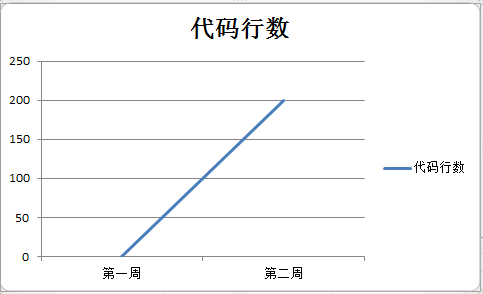
3.代码行数折线图:
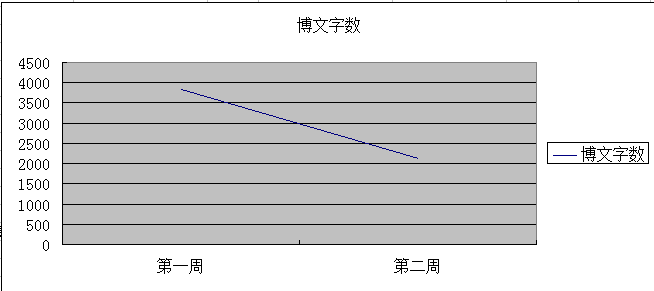
4.博文字数折线图:
5.进度条:

注:该进度条中代码行数200行,是我学习和调试学姐的代码,但是我读会了。
TWO
一.功能需求分析 :
1.小文件输入, 为表明程序能跑。
2.支持命令行输入英文作品的文件名,亲自录入。
3.支持命令行输入存储有英文作品文件的目录名,批量统计。
4.从控制台读入英文单篇作品。提供更适合嵌入脚本中的作品,重定向。
二.代码设计实现:
首先我在网上查阅关于C#语言的资料,也在图书馆借阅了C#的教程书,但是时间紧迫,加上我本身非常薄的编程基础,我根本用C#写不出来这些代码,也实现不了这四个功能。以我现在的编程基础只能去读懂一些C语言的程序代码,我自己独立去实现一个功能是比较困难的,我也希望在杨老师这门课上能够提高自己的编程能力,希望老师多多指点,我一定会努力夯实自己编程基础,慢慢的写出属于自己的代码。
我先安装VC++6.0编程软件,真的是我之前欠下的知识太多,只安装软件就用了一个半多将近两个小时,百度和请教同学以后发现该功能我自己还是实现不了,我的代码我是学习和调试的学姐的代码。该代码由两个函数组成,一个是quick()函数,另一个是main()主函数。
1.创建了一个结构体,num是用来统计出现次数,char a[]是存储字符。
struct f_word { int num; char a[18]; };
2.这是定义了quick()函数,是一个快速排序算法。读取数据到struct f_word 所指向的内存空间中,再对这些数据进行快速排序。
void quick(struct f_word *f, int i, int j) { int m, n,temp,k; char b[18]; m = i; n = j; k = f[(i + j) / 2].num; //选取的参照 do { while (f[m].num>k&&m<j) m++; // 从左到右找比k小的元素 while (f[n].num<k&&n>i) n--; // 从右到左找比k大的元素 if (m <= n) { //若找到且满足条件,则交换 temp = f[m].num; strcpy(b, f[m].a); f[m].num = f[n].num; strcpy(f[m].a, f[n].a); f[n].num = temp; strcpy(f[n].a, b); m++; n--; } } while (m <= n); if (m<j) quick(f, m, j); //运用递归 if (n>i) quick(f, i, n); }
3.定义了main()主函数。quick(structf_word *f,int i,int j);i是初始位置,j是结束位置。main()函数中是为W申请内存,然后读取文件内容到w中,它是结构体指针,相当于数组,其中的char数组存放单词,num用来统计该单词出现的次数。flag作为是否是单词的判断标志。先是w[0],开始时只要遇到字母就存到它的char数组中,若上一个是字母,下一个是非字母时就认为一个单词结束。就用w[1]在重新计算下一个单词,一直统计着。统计次数是从第一个w[0]到当前的w[i],看这个过程中,有那个w[a]和w[i]相等,相等次数就加1,a的范围是0到i-1。
int main(int argc, char *argv[]) { struct _finddata_t fa; long fHandle; FILE *fp; void quick(struct f_word *f, int i, int j); int i, j = 0, m, n, flag, p = 1; int mode,count=0; //mode为不同功能,为1时输入单个文件 char filename[20], b[18], ch; struct f_word *w; w = (struct f_word *)malloc(500* p * sizeof(struct f_word));//给结构体分配初始内存 printf("1为单个文件处理;2为批量文件处理 选择输入模式:"); scanf("%d", &mode); if (mode == 1) { /****************读取文本文件****************************/ printf("输入读入文件的名字:"); scanf("%s", filename); //输入需要统计词频的文件名 if ((fp = fopen(filename, "r")) == NULL) { printf("无法打开文件 "); exit(0); } /****************将单词出现次数设置为1****************************/ for (i = 0; i < 500; i++) { (w + i)->num = 1; } /****************单词匹配****************************************/ i = 0; while (!feof(fp))//文件尚未读取完毕 { ch = fgetc(fp); (w + i)->a[j] = '�'; if (ch >= 65 && ch <= 90 || ch >= 97 && ch <= 122) //ch若为字母则存入 { (w + i)->a[j] = ch; j++; flag = 0; //设标志位判断是否存在连续标点或者空格 } else if (!(ch >= 65 && ch <= 90 || ch >= 97 && ch <= 122) && flag == 0) //ch若不是字母且上一个字符为字母 { i++; j = 0; flag = 1; for (m = 0; m < i - 1; m++) //匹配单词,若已存在则num+1 { if (stricmp((w + m)->a, (w + i - 1)->a) == 0) { (w + m)->num++; i--; } } } /****************动态分配内存****************************************/ if (i == (p * 500)) //用i判断当前内存已满 { p++; w = (struct f_word*)realloc(w, 500 * p*(sizeof(struct f_word))); for (n = i; n <= 500 * p; n++) //给新分配内存的结构体赋初值 (w + n)->num = 1; } } i = i - 2; quick(w, 0, i); printf("不重复的单词数:"); printf("%d ", i); for (n = 0; n <= i; n++) { printf("文档中出现的单词:"); printf("%-18s", (w + n)->a); printf("其出现次数为:"); printf("%d ", (w + n)->num); } fclose(fp); return 0; free(w); } if (mode == 2) { printf("输入读入文件夹的名字:"); scanf("%s", &fa); if ((fHandle = _findfirst("*.txt", &fa)) == -1L)//这里可以改成需要的目录 { printf("当前目录下没有txt文件 "); return 0; } else do { fp = fopen(fa.name, "r"); for (i = 0; i < 500; i++) { (w + i)->num = 1; } /****************单词匹配****************************************/ i = 0; while (!feof(fp))//文件尚未读取完毕 { ch = fgetc(fp); (w + i)->a[j] = '�'; if (ch >= 65 && ch <= 90 || ch >= 97 && ch <= 122) //ch若为字母则存入 { (w + i)->a[j] = ch; j++; flag = 0; //设标志位判断是否存在连续标点或者空格 } else if (!(ch >= 65 && ch <= 90 || ch >= 97 && ch <= 122) && flag == 0) //ch若不是字母且上一个字符为字母 { i++; j = 0; flag = 1; for (m = 0; m < i - 1; m++) //匹配单词,若已存在则num+1 { if (stricmp((w + m)->a, (w + i - 1)->a) == 0) { (w + m)->num++; i--; } } } /****************动态分配内存****************************************/ if (i == (p * 500)) //用i判断当前内存已满 { p++; w = (struct f_word*)realloc(w, 500 * p*(sizeof(struct f_word))); for (n = i; n <= 500 * p; n++) //给新分配内存的结构体赋初值 (w + n)->num = 1; } } i = i - 2; quick(w, 0, i); printf("文件%s词频统计如下 ", fa.name); printf("不重复的单词数:"); printf("%d ", i); for (n = 0; n <10; n++) { printf("文档中出现的单词:"); printf("%-18s", (w + n)->a); printf("其出现次数为:"); printf("%d ", (w + n)->num); } printf(" "); } while (_findnext(fHandle, &fa) == 0); _findclose(fHandle); fclose(fp); return 0; free(w); } }
三.功能实现与分析:
1.我认为功能1 是在控制台键入一个小文件,功能4是在控制台键入一个大文件。他俩的重点和难点是如何在控制台上键入大小文件以及进行词频统计。但功能1和功能4我都没有实现。
我认为功能2的重点就是如何在控制台输入文件名以后,可以根据文件路径来访问文件并对其进行词频统计。可以实现,如下:


我认为功能3的重点和难点都是如何根据路径搜索几个文件,对几个文件中的词频分别进行统计并按降序排列只显示前十个单词的出现次数。可以实现,如下图:
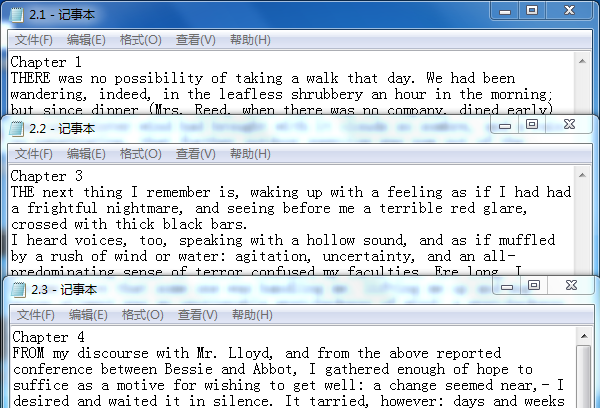
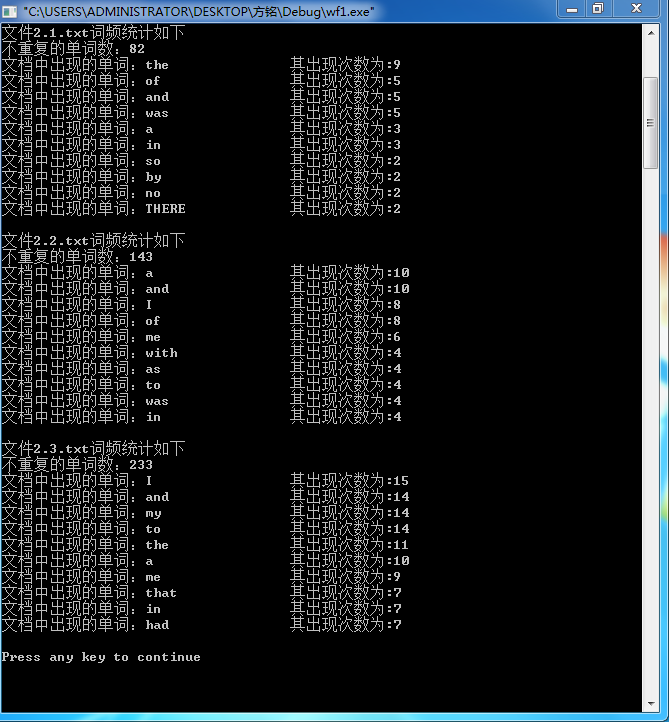
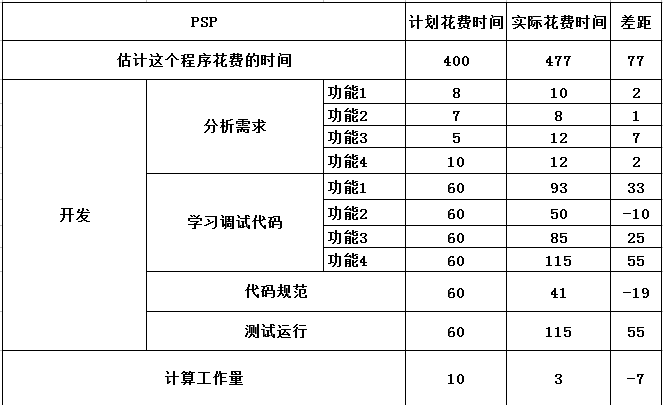
三.PSP2-1:
总结:
1.分析上表中出现差距的原因是我的基础太薄弱,造成读代码速递太慢,因此往下进行的速度变慢,以至于造成比预计时间晚了一个多小时并且还没有实现功能1和4.
2.我这次的代码虽然不是我自己写的,非常得意和突破的地方,我也没有。但是我也花了好长时间来完成这次的作业,从一开始的查资料到最后把这个程序调试出来,尽管我只实现了两个功能,只是感觉之前欠下的知识太多,我也不想骗杨老师我自己在网上百度或者去抄袭别人的说自己可以完成,我把这个代码读了,写上了我自己的理解。并完成了两个功能。
3.对于困难的地方,我不知道该如何实现直接在控制台上键入小文件,怎么来实现读取这个文件来进行词频统计。
THREE