前言
递归,是一个非常重要的概念,也是面试中非常喜欢考的。因为它不但能考察一个程序员的算法功底,还能很好的考察对时间空间复杂度的理解和分析。
本文只讲一题,也是几乎所有算法书讲递归的第一题,但力争讲出花来,在这里分享四点不一样的角度,让你有不同的收获。
- 时空复杂度的详细分析
- 识别并简化递归过程中的重复运算
- 披上羊皮的狼
- 适当炫技助我拿到第一份工作
算法思路
大家都知道,一个方法自己调用自己就是递归,没错,但这只是理解递归的最表层的理解。
那么递归的实质是什么?
答:递归的实质是能够把一个大问题分解成比它小点的问题,然后我们拿到了小问题的解,就可以用小问题的解去构造大问题的解。
那小问题的解是如何得到的?
答:用再小一号的问题的解构造出来的,小到不能再小的时候就是到了零号问题的时候,也就是 base case 了。
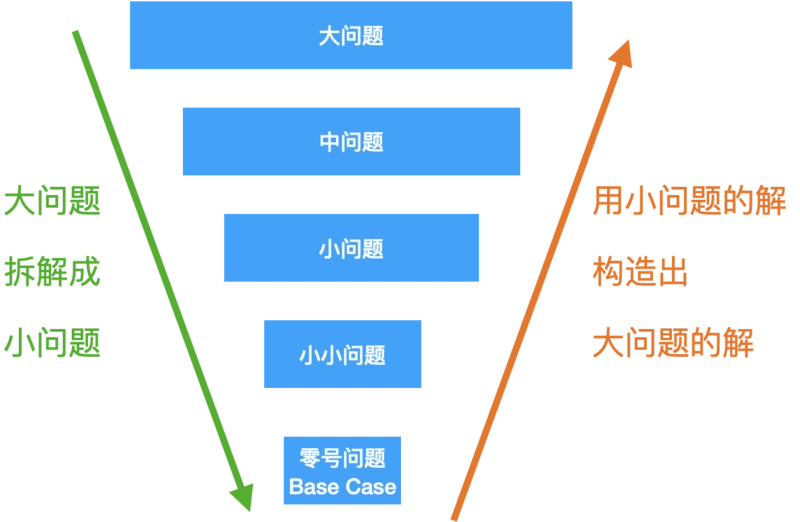
那么总结一下递归的三个步骤:
Base case:就是递归的零号问题,也是递归的终点,走到最小的那个问题,能够直接给出结果,不必再往下走了,否则,就会成死循环;
拆解:每一层的问题都要比上一层的小,不断缩小问题的 size,才能从大到小到 base case;
组合:得到了小问题的解,还要知道如何才能构造出大问题的解。
所以每道递归题,我们按照这三个步骤来分析,把这三个问题搞清楚,代码就很容易写了。
斐波那契数列
这题虽是老生常谈了,但相信我这里分享的一定会让你有其他收获。
题目描述
斐波那契数列是一位意大利的数学家,他闲着没事去研究兔子繁殖的过程,研究着就发现,可以写成这么一个序列:1,1,2,3,5,8,13,21…也就是每个数等于它前两个数之和。那么给你第 n 个数,问 F(n) 是多少。
解析
用数学公式表示很简单:
f(n) = f(n-1) + f(n-2)
代码也很简单,用我们刚总结的三步:
- base case: f(0) = 0, f(1) = 1.
- 分解:f(n-1), f(n-2)
- 组合:f(n) = f(n-1) + f(n-2)
那么写出来就是:
class Solution {
public int fib(int N) {
if (N == 0) {
return 0;
} else if (N == 1) {
return 1;
}
return fib(N-1) + fib(N-2);
}
}
但是这种解法 Leetcode 给出的速度经验只比 15% 的答案快,因为,它的时间复杂度实在是太高了!

过程分析
那这就是我想分享的第一点,如何去分析递归的过程。
首先我们把这颗 Recursion Tree 画出来,比如我们把 F(5) 的递归树画出来:
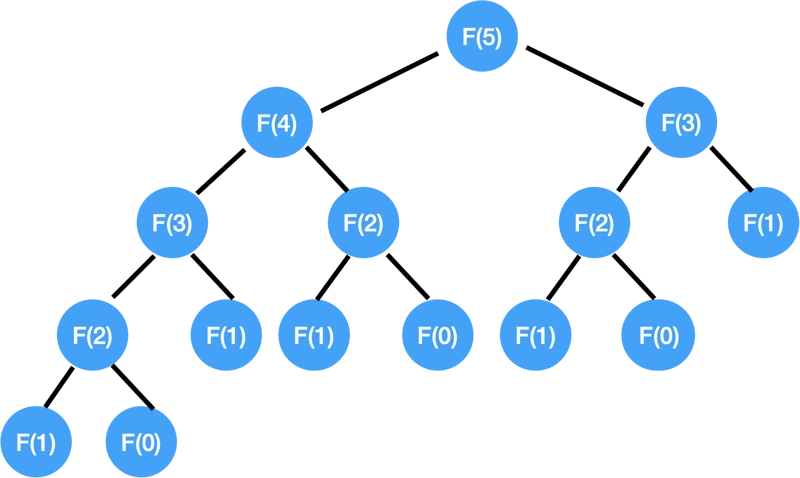
那实际的执行路线是怎样的?
首先是沿着最左边这条线一路到底:F(5) → F(4) → F(3) → F(2) → F(1),好了终于有个 base case 可以返回 F(1) = 1 了,然后返回到 F(2) 这一层,再往下走,就是 F(0),又触底反弹,回到 F(2),得到 F(2) = 1+0 =1 的结果,把这个结果返回给 F(3),然后再到 F(1),拿到结果后再返回 F(3) 得到 F(3) = 左 + 右 = 2,再把这个结果返上去...
这种方式本质上是由我们计算机的冯诺伊曼体系造就的,目前一个 CPU 一个核在某一时间只能执行一条指令,所以不能 F(3) 和 F(4) 一起进行了,一定是先执行了 F(4) (本代码把 fib(N-1) 放在前面),再去执行 F(3).
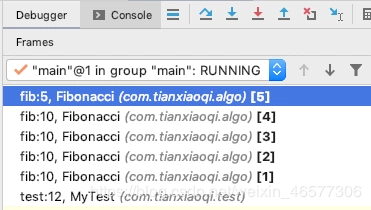
我们在 IDE 里 debug 就可以看到栈里面的情况:这里确实是先走的最左边这条线路,一共有 5 层,然后再一层层往上返回。
时间复杂度分析
如何评价一个算法的好坏?
很多问题都有多种解法,毕竟条条大路通罗马。但如何评价每种方法的优劣,我们一般是用大 O 表达式来衡量时间和空间复杂度。
时间复杂度:随着自变量的增长,所需时间的增长情况。
这里大 O 表示的是一个算法在 worst case 的表现情况,这就是我们最关心的,不然春运抢车票的时候系统 hold 不住了,你跟我说这个算法很优秀?
当然还有其他衡量时间和空间的方式,比如
Theta: 描述的是 tight bound Omega(n):
这个描述的是 best case,最好的情况,没啥意义
这也给我们了些许启发,不要说你平时表现有多好,没有意义;面试衡量的是你在 worst case 的水平;不要说面试没有发挥出你的真实水平,扎心的是那就是我们的真实水平。
那对于这个题来说,时间复杂度是多少呢?
答:因为我们每个节点都走了一遍,所以是把所有节点的时间加起来就是总的时间。
在这里,我们在每个节点上做的事情就是相加求和,是 O(1) 的操作,且每个节点的时间都是一样的,所以:
总时间 = 节点个数 * 每个节点的时间
那就变成了求节点个数的数学题:
在 N = 5 时,
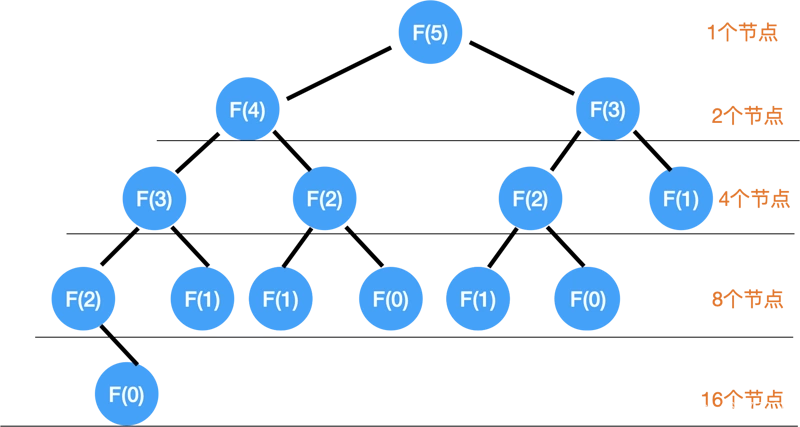
最上面一层有1个节点,
第二层 2 个,
第三层 4 个,
第四层 8 个,
第五层 16 个,如果填满的话,想象成一颗很大的树:)
这里就不要在意这个没填满的地方了,肯定是会有差这么几个 node,但是大 O 表达的时间复杂度我们刚说过了,求的是 worst case.
那么总的节点数就是:
1 + 2 + 4 + 8 + 16
这就是一个等比数列求和了,当然你可以用数学公式来算,但还有个小技巧可以帮助你快速计算:
其实前面每一层的节点相加起来的个数都不会超过最后一层的节点的个数,总的节点数最多也就是最后一层节点数 * 2,然后在大 O 的时间复杂度里面常数项也是无所谓的,所以这个总的时间复杂度就是:
最后一层节点的个数:2^n
空间复杂度分析
一般书上写的空间复杂度是指:
算法运行期间所需占用的所有内存空间
但是在公司里大家常用的,也是面试时问的指的是
Auxiliary space complexity:
运行算法时所需占用的额外空间。
举例说明区别:比如结果让你输出一个长度为 n 的数组,那么这 O(n) 的空间是不算在算法的空间复杂度里的,因为这个空间是跑不掉的,不是取决于你的算法的。
那空间复杂度怎么分析呢?
我们刚刚说到了冯诺伊曼体系,从图中也很容易看出来,是最左边这条路线占用 stack 的空间最多,一直不断的压栈,也就是从 5 到 4 到 3 到 2 一直压到 1,才到 base case 返回,每个节点占用的空间复杂度是 O(1),所以加起来总的空间复杂度就是 O(n).
优化算法
那我们就想了,为什么这么一个简简单单的运算竟然要指数级的时间复杂度?到底是为什么让时间如此之大。
那也不难看出来,在这棵 Recursion Tree 里,有太多的重复计算了。
比如一个 F(2) 在这里都被计算了 3 次,F(3) 被计算了 2 次,每次还都要再重新算,这不就是狗熊掰棒子吗,真的是一把辛酸泪。
那找到了原因之后,为了解决这种重复计算,计算机采用的方法其实和我们人类是一样的:记笔记。
对很多职业来说,比如医生、律师、以及我们工程师,为什么越老经验值钱?因为我们见得多积累的多,下次再遇到类似的问题时,能够很快的给出解决方案,哪怕一时解决不了,也避免了一些盲目的试错,我们会站在过去的高度不断进步,而不是每次都从零开始。
回到优化算法上来,那计算机如何记笔记呢?
我们要想求 F(n),无非也就是要
记录 F(0) ~ F(n-1) 的值,
那选取一个合适的数据结构来存储就好了。
那这里很明显了,用一个数组来存:
| Index | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| F(n) | 0 | 1 | 1 | 2 | 3 | 5 |
那有了这个 cheat sheet,我们就可以从前到后得到结果了,这样每一个点就只算了一遍,用一个 for loop 就可以写出来,代码也非常简单。
class Solution {
public int fib(int N) {
if (N == 0) {
return 0;
}
if (N== 1) {
return 1;
}
int[] notes = new int[N+1];
notes[0] = 0;
notes[1] = 1;
for(int i = 2; i <= N; i++) {
notes[i] = notes[i-1] + notes[i-2];
}
return notes[N];
}
}
这个速度就是 100% 了~
但是我们可以看到,空间应该还有优化的余地。
那仔细想想,其实我们记笔记的时候需要记录这么多吗?需要从幼儿园到小学到初中到高中的笔记都留着吗?
那其实每项的计算只取决于它前面的两项,所以只用保留这两个就好了。
那我们可以用一个长度为 2 的数组来计算,或者就用 2 个变量。
更新代码:
class Solution {
public int fib(int N) {
int a = 0;
int b = 1;
if(N == 0) {
return a;
}
if(N == 1) {
return b;
}
for(int i = 2; i <= N; i++) {
int tmp = a + b;
a = b;
b = tmp;
}
return b;
}
}
这样我们就把空间复杂度优化到了 O(1),时间复杂度和用数组记录一样都是 O(n).
这种方法其实就是动态规划 Dynamic Programming,写出来的代码非常简单。
那我们比较一下 Recursion 和 DP:
Recursion 是从大到小,层层分解,直到 base case 分解不了了再组合返回上去;
DP 是从小到大,记好笔记,不断进步。
也就是 Recursion + Cache = DP
如何记录这个笔记,如何高效的记笔记,这是 DP 的难点。
有人说 DP 是拿空间换时间,但我不这么认为,这道题就是一个很好的例证。
在用递归解题时,我们可以看到,空间是 O(n) 在栈上的,但是用 DP 我们可以把空间优化到 O(1),DP 可以做到时间空间的双重优化。
其实呢,斐波那契数列在现实生活中也有很多应用。
比如在我司以及很多大公司里,每个任务要给分值,1分表示大概需要花1天时间完成,然后分值只有>1,2,3,5,8这5种,(如果有大于8分的任务,就需要把它 break down 成8分以内的,以便大家在>两周内能完成。)
因为任务是永远做不完的而每个人的时间是有限的,所以每次小组会开会,挑出最重要的任务让大家来>做,然后每个人根据自己的 available 的天数去 pick up 相应的任务。
那有同学可能会想,这题这么简单,这都 2020 年了,面试还会考么?
答:真的会。
只是不能以这么直白的方式给你了。
比如很有名的爬楼梯问题:
一个 N 阶的楼梯,每次能走一层或者两层,问一共有多少种走法。
这个题这么想:
站在当前位置,只能是从前一层,或者前两层上来的,所以 f(n) = f(n-1) + f(n-2).
这题是我当年面试时真实被问的,那时我还在写 python,为了炫技,还用了lambda function:
f = lambda n: 1 if n in (1, 2) else f(n-1) + f(n-2)
递归的写法时间复杂度太高,所以又写了一个 for loop 的版本
def fib(n)
a, b = 1, 1
for i in range(n-1):
a, b = b, a+b
return a
然后还写了个 caching 的方法:
def cache(f):
memo = {}
def helper(x):
if x not in memo:
memo[x] = f(x)
return memo[x]
return helper
@cache
def fibR(n):
if n==1 or n==2: return 1
return fibR(n-1) + fibR(n-2)
还顺便和面试官聊了下 tail recursion:
tail recursion 尾递归:就是递归的这句话是整个方法的最后一句话。
那这个有什么特别之处呢?
尾递归的特点就是我们可以很容易的把它转成 iterative 的写法,当然有些智能的编译器会自动帮我们做了(不是说显性的转化,而是在运行时按照 iterative 的方式去运行,实际消耗的空间是O(1))
那为什么呢?
因为回来的时候不需要 backtrack,递归这里就是最后一步了,不需要再往上一层返值。
def fib(n, a=0, b=1):
if n==0: return a
if n==1: return b
return fib(n-1, b, a+b)
最终,拿出了我的杀手锏:lambda and reduce
fibRe = lambda n: reduce(lambda x, n: [x[1], x[0]+x[1]], range(n), [0, 1])
看到面试官满意的表情后,就开始继续深入的聊了...
所以说,不要以为它简单,同一道题可以用七八种方法来解,分析好每个方法的优缺点,引申到你可以引申的地方,展示自己扎实的基本功,这场面试其实就是你 show off 的机会,这样才能骗过面试官啊~lol
这就是本文的所有内容了,不知道大家看完感受如何?留言告诉我你的感受吧~
点击在看,鼓励下我啊!
瞎写评论,显得我很红啊!
转发转发转发,爱她,就送给她!
还想跟我看更多数据结构和算法题的小伙伴们,记得关注我,我是程序零世界,算法就这么回事。
作者:小齐本齐
