朴素贝叶斯算法
朴素贝叶斯算法:朴素 + 贝叶斯
朴素:假设特征与特征之间是相互独立
贝叶斯公式

公式应用在文章分类中,公式可以理解为
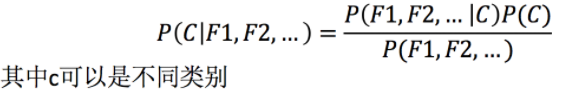
公式分为三个部分:
- P(C):每个文档类别的概率(某文档类别数/总文档数量)
- P(W│C):给定类别下特征(被预测文档中出现的词)的概率
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- Ni为该F1词在C类别所有文档中出现的次数
- N为所属类别C下的文档所有词出现的次数和
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- P(F1,F2,…) 预测文档中每个词的概率
拉普拉斯平滑系数
目的:防止计算出的分类概率为0

API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
案例:新闻分类
代码
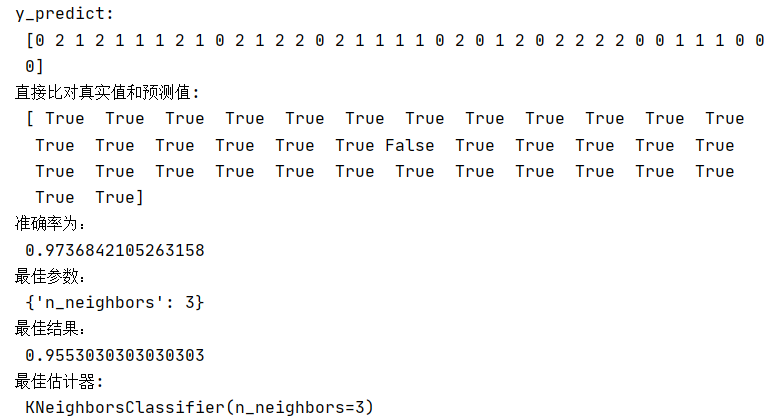
def nb_news(): """ 用朴素贝叶斯算法对新闻进行分类 :return: """ # 1)获取数据 news = fetch_20newsgroups(subset="all") # 2)划分数据集 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target) # 3)特征工程:文本特征抽取-tfidf transfer = TfidfVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4)朴素贝叶斯算法预估器流程 estimator = MultinomialNB() estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict: ", y_predict) print("直接比对真实值和预测值: ", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为: ", score) return None
总结
- 优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
- 缺点:
- 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好