



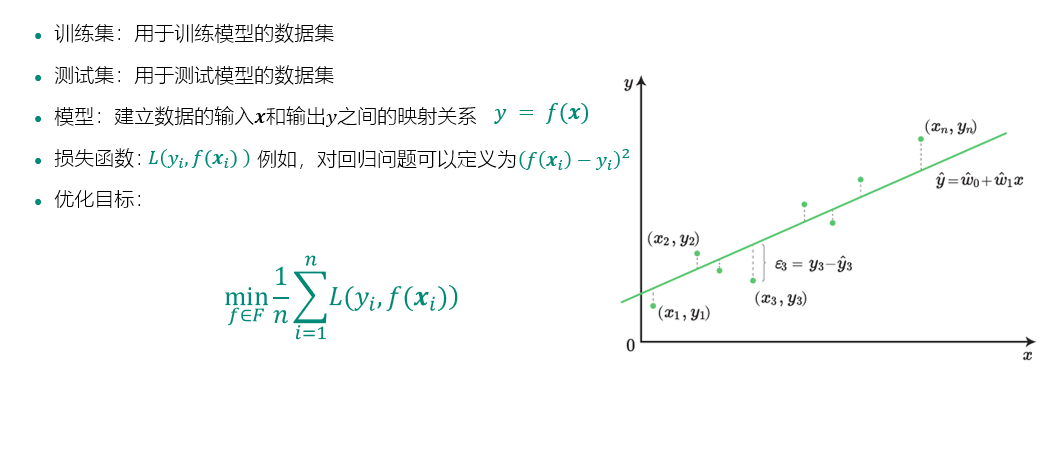
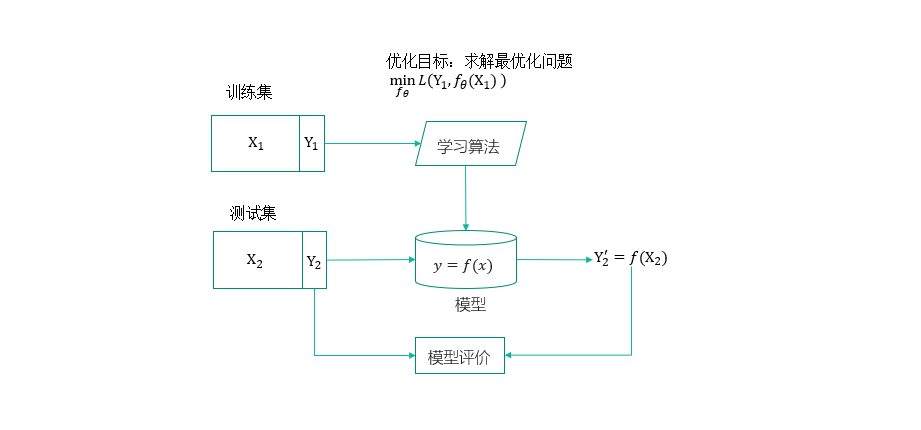
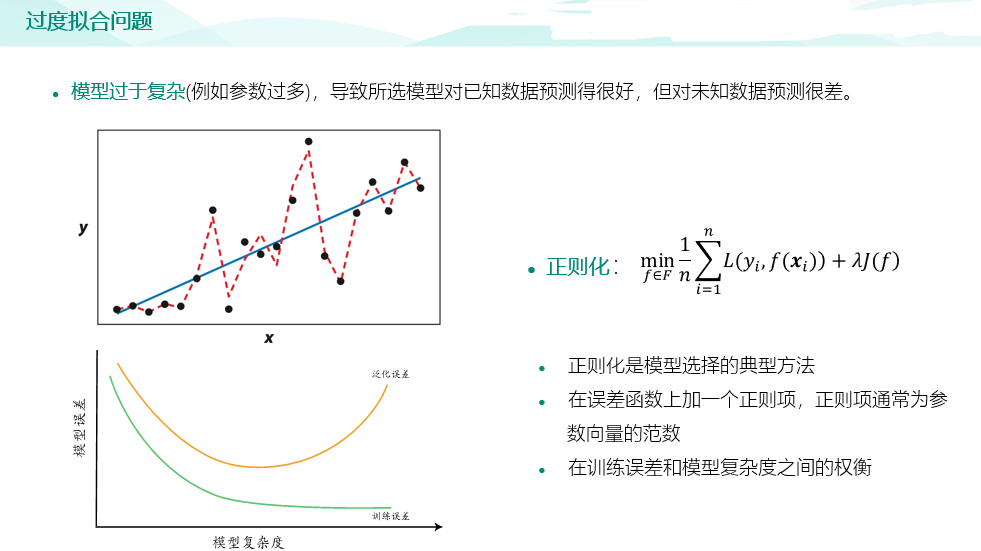


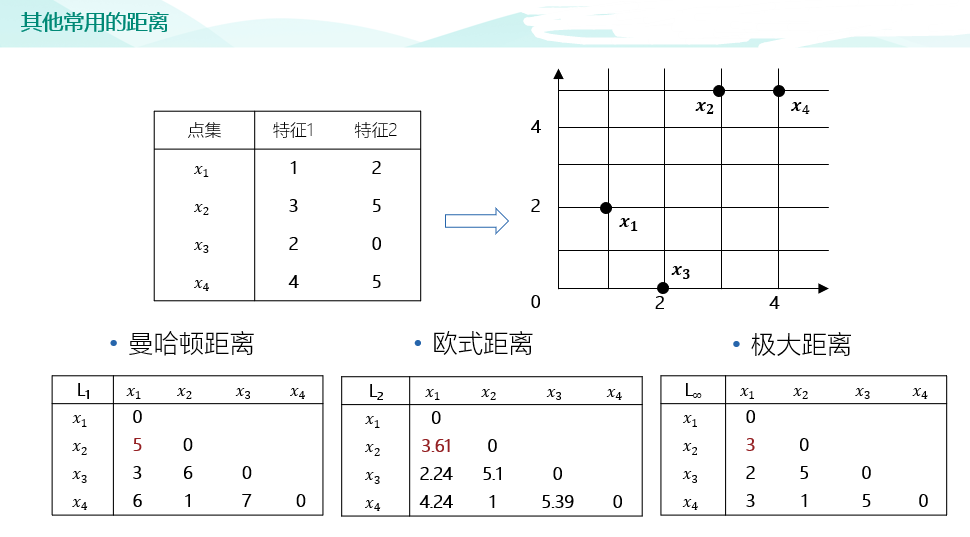
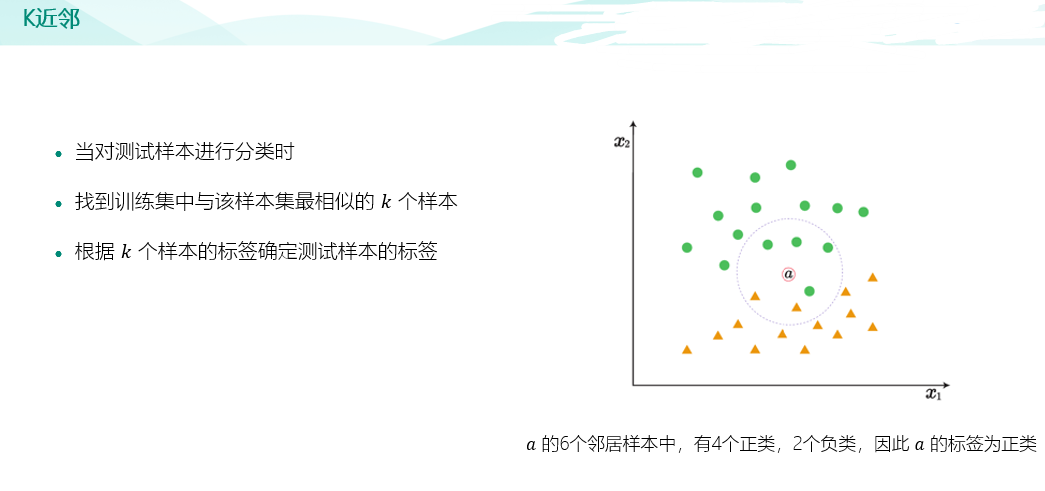
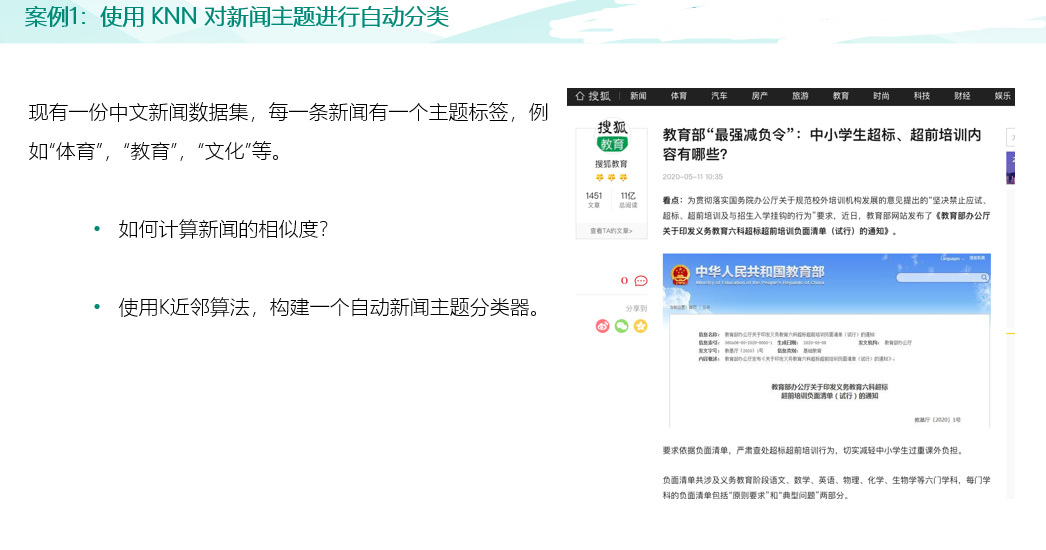
import pandas as pd #绘图中文字体 import matplotlib as mpl mpl.rcParams['font.sans-serif']=['SimHei'] # #指定默认字体 SimHei为黑体 mpl.rcParams['axes.unicode_minus']=False # #用来正常显示负号 raw_train = pd.read_csv("input/train_sample_utf8.csv",encoding="utf8") raw_test = pd.read_csv("input/test_sample_utf8.csv",encoding="utf8") #print(raw_train.loc[0,'文章']) import matplotlib.pyplot as plt # plt.figure(figsize=(15, 8)) # plt.subplot(1, 2, 1) # raw_train["分类"].value_counts().sort_index().plot(kind="barh",title='训练集新闻主题分布') # plt.subplot(1, 2, 2) # raw_test["分类"].value_counts().sort_index().plot(kind="barh",title='测试集新闻主题分布') # plt.show() #对新闻内容进行分词 import jieba def news_cut(text): return " ".join(list(jieba.cut(text))) raw_train["分词文章"] = raw_train["文章"].map(news_cut) raw_test["分词文章"] = raw_test["文章"].map(news_cut) print(raw_train.columns) #加载停用词 # 第一种解决方法,增加encoding=‘UTF-8’: # FILE_OBJECT= open( 'train.txt','r', encoding='UTF-8' ) # 第二种方法,二进制读取: # FILE_OBJECT= open( 'train.txt', 'rb' ) stop_words = [] file = open("input/stopwords.txt",encoding='UTF-8') for line in file: stop_words.append(line.strip()) file.close() print(stop_words) #文本特征提取 from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(stop_words=stop_words) X_train = vectorizer.fit_transform(raw_train["分词文章"]) X_test = vectorizer.transform(raw_test["分词文章"]) #构建 KNN 分类器 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() # 加入网格搜索与交叉验证 from sklearn.model_selection import GridSearchCV param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]} knn = GridSearchCV(knn, param_grid=param_dict, cv=10) knn.fit(X_train, raw_train["分类"]) #测试集新闻主题预测 Y_test = knn.predict(X_test) # 5)模型评估 # 方法1:直接比对真实值和预测值 print("直接比对真实值和预测值: ", raw_test["分类"] == Y_test) # 方法2:计算准确率 score = knn.score(X_test, raw_test["分类"]) print("准确率为: ", score) # 最佳参数:best_params_ print("最佳参数: ", knn.best_params_) # 最佳结果:best_score_ print("最佳结果: ", knn.best_score_) # 最佳估计器:best_estimator_ print("最佳估计器: ", knn.best_estimator_) # 交叉验证结果:cv_results_ print("交叉验证结果: ", knn.cv_results_)