理论依据
假设我们得到了一个点云, 我们想要找到并分割。 假设我们使用Kd-tree结构来查找最近的邻居,算法步骤是:

代码
算法的关键在于设置合理提取的阈值 ,如果取很小的值,它可能把一个对象可以看作是多个群集。 反之,如果将值设置得太高,则可能会发生多个对象被视为一个集群。
pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
ec.setClusterTolerance(2); // 2cm
ec.setMinClusterSize(100);
ec.setMaxClusterSize(25000);
ec.setSearchMethod(tree);
ec.setInputCloud(cloud_filtered);
ec.extract(cluster_indices);
#include <iostream> //标准输入输出流
#include <pcl/io/pcd_io.h> //PCL的PCD格式文件的输入输出头文件
#include <pcl/point_types.h> //PCL对各种格式的点的支持头文件
#include <pcl/visualization/cloud_viewer.h>//点云查看窗口头文件
#include <pcl/surface/convex_hull.h>
#include<pcl/io/pcd_io.h>
#include<pcl/point_types.h>
#include "opencv2/opencv.hpp"
#include <pcl/visualization/pcl_visualizer.h>
#include <boost/thread/thread.hpp>
#include <pcl/ModelCoefficients.h>
#include <pcl/point_types.h>
#include <pcl/io/pcd_io.h>
#include <pcl/filters/extract_indices.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/features/normal_3d.h>
#include <pcl/kdtree/kdtree.h>
#include <pcl/sample_consensus/method_types.h>
#include <pcl/sample_consensus/model_types.h>
#include <pcl/segmentation/sac_segmentation.h>
#include <pcl/segmentation/extract_clusters.h>
int main(int argc, char** argv)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>), cloud_f(new pcl::PointCloud<pcl::PointXYZ>);;
pcl::io::loadPCDFile<pcl::PointXYZ>("reproject_pcd.pcd", *cloud);
//visualization(cloud);
// Create the filtering object: downsample the dataset using a leaf size of 1cm
pcl::VoxelGrid<pcl::PointXYZ> vg;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_filtered(new pcl::PointCloud<pcl::PointXYZ>);
vg.setInputCloud(cloud);
vg.setLeafSize(0.01f, 0.01f, 0.01f);
vg.filter(*cloud_filtered);
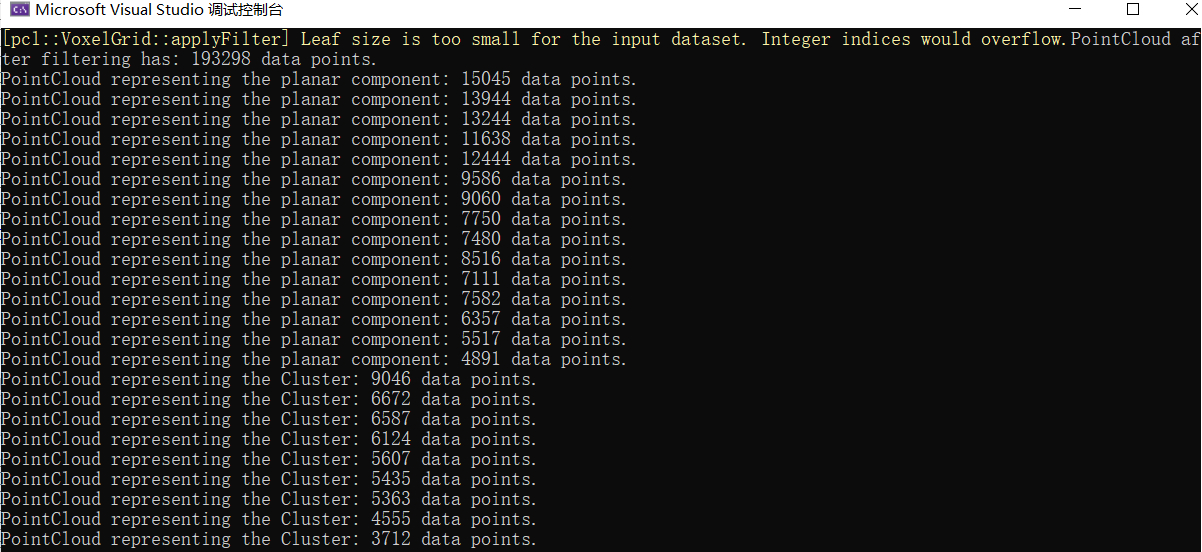
std::cout << "PointCloud after filtering has: " << cloud_filtered->size() << " data points." << std::endl; //*
// Create the segmentation object for the planar model and set all the parameters
pcl::SACSegmentation<pcl::PointXYZ> seg;
pcl::PointIndices::Ptr inliers(new pcl::PointIndices);
pcl::ModelCoefficients::Ptr coefficients(new pcl::ModelCoefficients);
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_plane(new pcl::PointCloud<pcl::PointXYZ>());
pcl::PCDWriter writer;
seg.setOptimizeCoefficients(true);
seg.setModelType(pcl::SACMODEL_PLANE);
seg.setMethodType(pcl::SAC_RANSAC);
seg.setMaxIterations(100);
seg.setDistanceThreshold(0.2);
int i = 0, nr_points = (int)cloud_filtered->size();
while (cloud_filtered->size() > 0.3 * nr_points)
{
// Segment the largest planar component from the remaining cloud
seg.setInputCloud(cloud_filtered);
seg.segment(*inliers, *coefficients);
if (inliers->indices.size() == 0)
{
std::cout << "Could not estimate a planar model for the given dataset." << std::endl;
break;
}
// Extract the planar inliers from the input cloud
pcl::ExtractIndices<pcl::PointXYZ> extract;
extract.setInputCloud(cloud_filtered);
extract.setIndices(inliers);
extract.setNegative(false);
// Get the points associated with the planar surface
extract.filter(*cloud_plane);
std::cout << "PointCloud representing the planar component: " << cloud_plane->size() << " data points." << std::endl;
// Remove the planar inliers, extract the rest
extract.setNegative(true);
extract.filter(*cloud_f);
*cloud_filtered = *cloud_f;
}
// Creating the KdTree object for the search method of the extraction
pcl::search::KdTree<pcl::PointXYZ>::Ptr tree(new pcl::search::KdTree<pcl::PointXYZ>);
tree->setInputCloud(cloud_filtered);
std::vector<pcl::PointIndices> cluster_indices;
pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
ec.setClusterTolerance(2); // 2cm
ec.setMinClusterSize(100);
ec.setMaxClusterSize(25000);
ec.setSearchMethod(tree);
ec.setInputCloud(cloud_filtered);
ec.extract(cluster_indices);
int j = 0;
for (std::vector<pcl::PointIndices>::const_iterator it = cluster_indices.begin(); it != cluster_indices.end(); ++it)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_cluster(new pcl::PointCloud<pcl::PointXYZ>);
for (std::vector<int>::const_iterator pit = it->indices.begin(); pit != it->indices.end(); ++pit)
cloud_cluster->push_back((*cloud_filtered)[*pit]); //*
cloud_cluster->width = cloud_cluster->size();
cloud_cluster->height = 1;
cloud_cluster->is_dense = true;
std::cout << "PointCloud representing the Cluster: " << cloud_cluster->size() << " data points." << std::endl;
std::stringstream ss;
ss << "cloud_cluster_pcl" << j << ".pcd";
writer.write<pcl::PointXYZ>(ss.str(), *cloud_cluster, false); //*
j++;
}
return (0);
}
分割结果