一,列表推导式
一行搞定,列表推导式:用列表推导式能够构建的任何列表,用别的都可以构建。
一行,简单,感觉高端。但是,不易排错。
列表推导式:一目了然,占内存。
生成器表达式:不易看出,节省内容。
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的
l = [i for i in range(10)]
print(l) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
l1 = ['选项%s'%i for i in range(10)]
print(l1)
推导式格式
variable = [out_exp_res for out_exp in input_list if out_exp == 2]
out_exp_res: 列表生成元素表达式,可以是有返回值的函数。
for out_exp in input_list: 迭代input_list将out_exp传入out_exp_res表达式中。
if out_exp == 2: 根据条件过滤哪些值可以。
列表推导式
例一:30以内所有能被3整除的数
multiples = [i for i in range(30) if i % 3 is 0]
print(multiples)
# Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
例二:30以内所有能被3整除的数的平方
def squared(x):
return x*x
multiples = [squared(i) for i in range(30) if i % 3 is 0]
print(multiples)
例三:找到嵌套列表中名字含有两个‘e’的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
# 注意遍历顺序,这是实现的关键
print([name for lst in names for name in lst if name.count('e') >= 2])
字典推导式
例一:将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
例二:合并大小写对应的value值,将k统一成小写
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
集合推导式
例:计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])
二、内置函数
***eval:执行字符串类型的代码,并返回最终结果 print(eval('3 +4')) #7 ret = eval('{"name":"老男孩"}') print(ret,type(ret)) #{'name': '老男孩'} <class 'dict'>
***exec:执行字符串类型的代码,流程语句。
ret1 = '''
li = [1,2,3]
for i in li:
print(i) #竖排1 2 3
'''
***print()
print(self, *args, sep=' ', end=' ', file=None)
print(333,end='')
print(666,)#333666
print(111,222,333,sep='|')#111|222|333
with open('log',encoding='utf-8',mode='a') as f1:
print('5555',file=f1)
***callable:函数用于检查一个对象是否是可调用的。
如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
def func1():
print(555)
a = 3
f = func1
print(callable(f)) #True
print(callable(a)) #False
***dir
print(dir(list))#所有方法
***sum:对可迭代对象进行求和计算(可设置初始值)。
print(sum([1,2,3])) #6
print(sum([1,2,3],100))#106
***max:返回可迭代对象的最大值(可加key,key为函数名,通过函数的规则,返回最大值)。
print(max([1,2,3])) #3
ret = max([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最大值
print(ret)#5
***min
ret = min([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最小值
print(ret)#1
***reversed:将一个序列翻转,并返回此翻转序列的迭代器。
ite = reversed(['a',2,3,'c',4,2])
print(ite)
for i in ite:
print(i) #24c32a
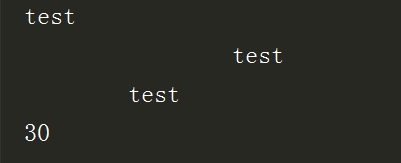
*** format 用于格式化输出很重要
s1 = format('test', '<30')
print(format('test', '<30'))
print(format('test', '>20'))
print(format('test', '^20'))
print(len(s1))
*** repr 原形毕露
print(repr('{"name":"alex"}')) #'{"name":"alex"}'
print('{"name":"alex"}') #{"name":"alex"}
*** sorted key
li = [1,-2,-7,8,5,-4,3]
print(sorted(li,reverse=True,key=abs)) #[8, -7, 5, -4, 3, -2, 1] abs:绝对值
*** enumerate:枚举,返回一个枚举对象。 (0, seq[0]), (1, seq[1]), (2, seq[2]),
li = ['老男孩', 'alex', 'wusir', '嫂子', 'taibai']
print(enumerate(li))
print('__iter__' in dir(enumerate(li)))#True enumerate是迭代器
print('__next__' in dir(enumerate(li)))#True
for k,v in enumerate(li):
print(k,v) #0 老男孩 1 alex 2 wusir 3 嫂子 4 taibai
for k,v in enumerate(li,1):
print(k,v) #1 老男孩 2 alex 3 wusir 4 嫂子 5 taibai
*** zip 拉链方法 形成元组的个数与最短的可迭代对象的长度一样,然后......
l1 = [1, 2, 3, 4]
l2 = ['a', 'b', 'c', 5]
l3 = ('*', '**', (1,2,3), 777)
l4= ('0', '99', (1,2,3), 777)
print('__iter__' in dir(zip(l1,l2,l3,l4))) #True zip是迭代器
print('__next__' in dir(zip(l1,l2,l3,l4))) #True
for i in zip(l1,l2,l3,l4):
print(i)
(1, 'a', '*', '0')
(2, 'b', '**', '99')
(3, 'c', (1, 2, 3), (1, 2, 3))
(4, 5, 777, 777)
***filter 过滤 通过你的函数,过滤一个可迭代对象,返回的是True
类似于[i for i in range(10) if i > 3]
def func(x):
return x % 2 == 0
ret = filter(func,[1,2,3,4,5,6,7])
print(ret)
for i in ret:
print(i) #246
***map:会根据提供的函数对指定序列做映射。
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
三、 匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数。
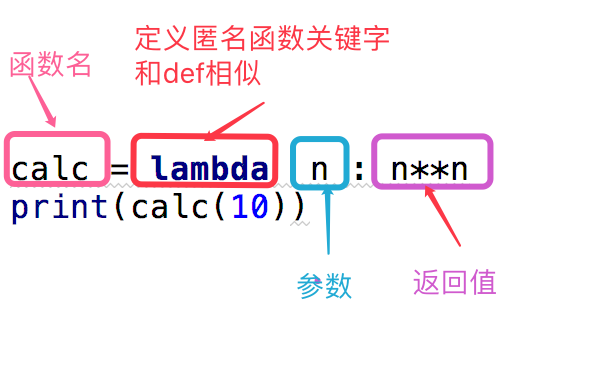
函数名 = lambda 参数 :返回值
#参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
lambda 函数与内置函数的结合。
sorted,map,fiter,max,min,reversed