一、多表查询
原文件是:
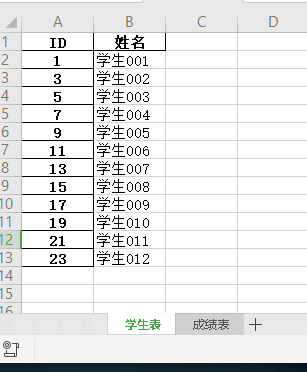
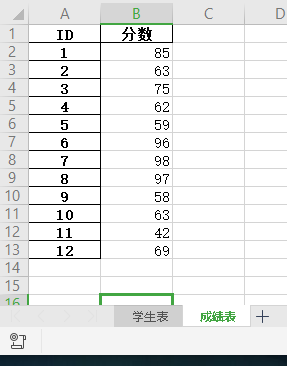
1.联合查询:查询学生表对应的成绩表的学生成绩。
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd students = pd.read_excel('多表查询.xlsx',sheet_name='学生表') scores = pd.read_excel('多表查询.xlsx',sheet_name='成绩表') exl = students.merge(scores,on='ID') print(exl)
效果:查出结果是保留了公有的数据
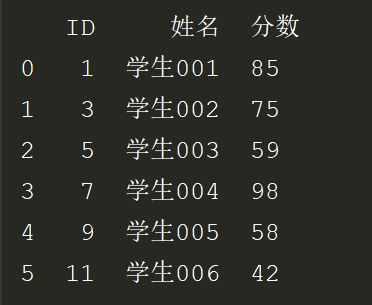
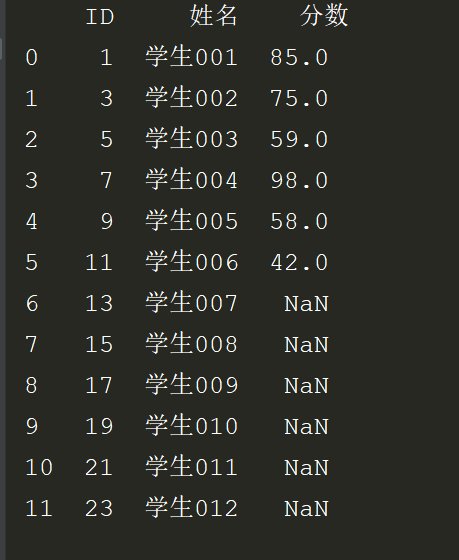
2.联合查询:查询学生表对应的成绩表的学生成绩。保留学生表数据
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd students = pd.read_excel('多表查询.xlsx',sheet_name='学生表') scores = pd.read_excel('多表查询.xlsx',sheet_name='成绩表') exl = students.merge(scores,how='left',on='ID') print(exl)
效果:
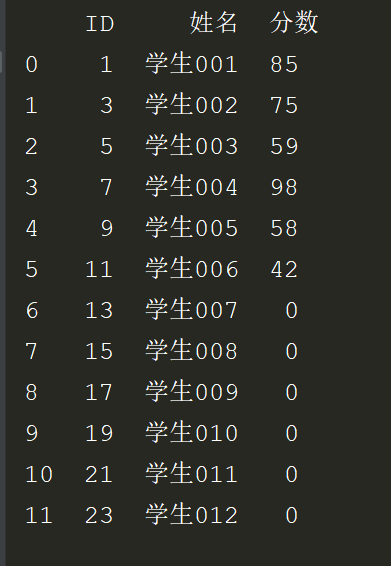
3.联合查询:查询学生表对应的成绩表的学生成绩。保留学生表数据-->分数保留整数,没有匹配到显示0,on参数是两个表都有这个列名就可以是用,如果不一样就使用left_on=,right_on=
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd students = pd.read_excel('多表查询.xlsx',sheet_name='学生表') scores = pd.read_excel('多表查询.xlsx',sheet_name='成绩表') exl = students.merge(scores,how='left',left_on='ID',right_on='ID').fillna(0) exl['分数'] = exl.分数.astype(int) print(exl)
效果:
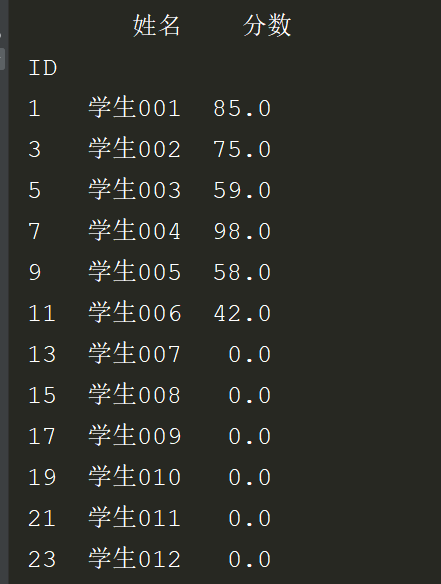
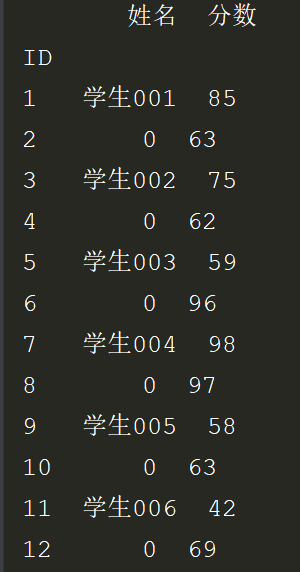
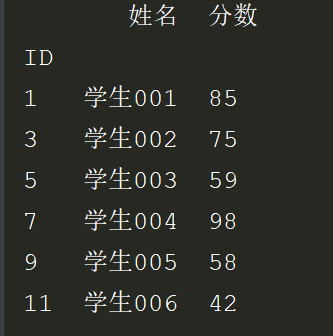
4.以上1,2,3,是用的merge方法,现在看看用join: 首先join要指定index_col。之后用how=参数控制是左连接how=‘left’还有右连接how=‘right’,还是取交集how='inner'
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd students = pd.read_excel('多表查询.xlsx',sheet_name='学生表',index_col="ID") scores = pd.read_excel('多表查询.xlsx',sheet_name='成绩表',index_col="ID") exl_left = students.join(scores,how='left').fillna(0) exl_right = students.join(scores,how='right').fillna(0) exl_inner = students.join(scores,how='inner').fillna(0) # exl['分数'] = exl.分数.astype(int) print(exl_left) print(exl_right) print(exl_inner)
效果:
5.pandas对Excel数据校验:满分是100分的试卷
原文件:
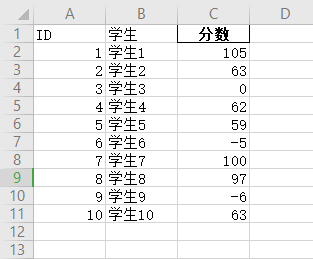
1.把不是0-100的分数打印出来,axis参数:0是按照列来,1 是按照行来。如果显示不齐,把print(f'{row.ID} exl{row.学生} 数据校验0-100 {row.分数}')空格换成 制表符就OK了
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据校验.xlsx') def fen_jiaoyao(row): try: assert 0<=row.分数<=100 except: print(f'{row.ID} exl{row.学生} 数据校验0-100 {row.分数}') exl.apply(fen_jiaoyao,axis=1)
效果:

2.拆分数据:按照一定的条件把学生和分数分别拆分出来
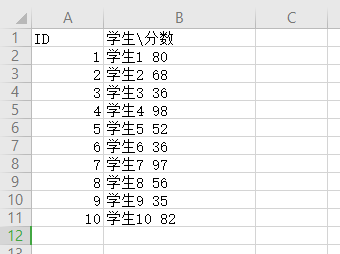
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据拆分.xlsx',index_col='ID') df = exl['学生分数'].str.split(' ',n=2,expand=True) exl["学生"] = df[0] exl["分数"] = df[1] exl = exl.drop(['学生分数'],axis=1) #删除列 print(exl)
效果:
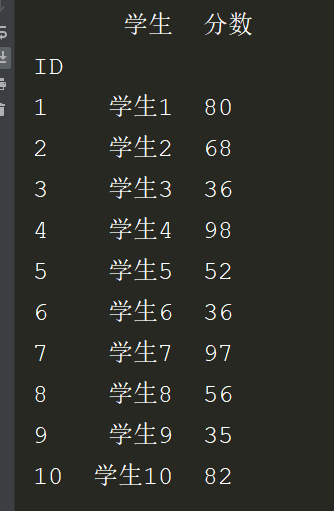
3.删除行和列操作:
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据拆分.xlsx',index_col='ID') df = exl['学生分数'].str.split(' ',n=2,expand=True) exl["学生"] = df[0] exl["分数"] = df[1] exl = exl.drop(['学生分数'],axis=1) #删除列 exl = exl.drop([2,3]) print(exl)
效果:
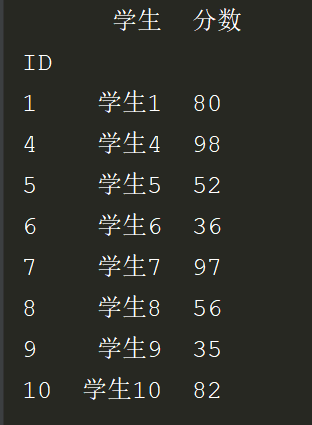
二、数据统计:原数据
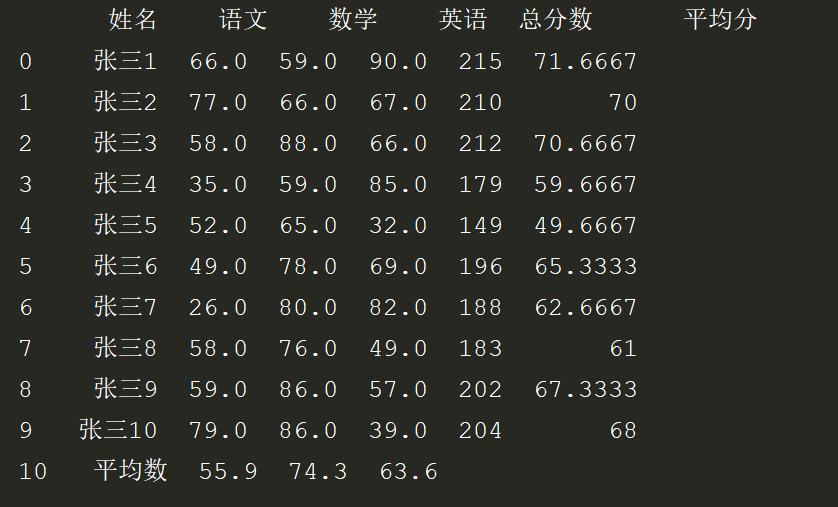
1.求 加两列每个同学的总分数和平均分数,加一行求每个科目的平均分数
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据统计.xlsx',index_col='ID') #拿到三次考试的成绩进行数据统计 shuju = exl[['语文','数学','英语']] #按行求和、求平均值 hang_sum = shuju.sum(axis=1) hang_mean = shuju.mean(axis=1) exl['总分数'] = hang_sum exl['平均分'] = hang_mean #按列求和、求平均值 # lie_sum = shuju.sum() lie_mean = shuju.mean() lie_mean["姓名"] = "平均数" lie_mean["总分数"] = "" lie_mean["平均分"] = "" exl=exl.append(lie_mean,ignore_index=True) print(exl)
效果:
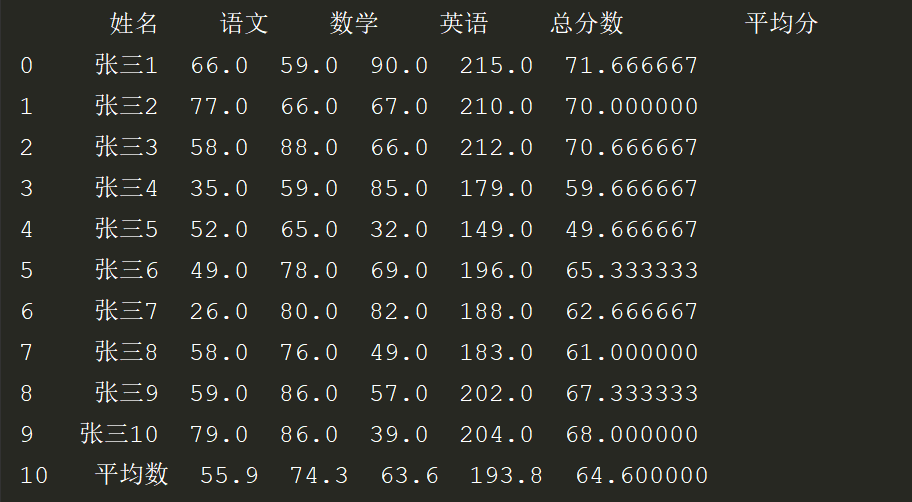
2. 在1的基础上,如果想求总分数的平均值和平均值的平均值
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据统计.xlsx',index_col='ID') #拿到三次考试的成绩进行数据统计 shuju = exl[['语文','数学','英语']] #按行求和、求平均值 hang_sum = shuju.sum(axis=1) hang_mean = shuju.mean(axis=1) exl['总分数'] = hang_sum exl['平均分'] = hang_mean #按列求和、求平均值 # lie_sum = shuju.sum() # lie_mean = shuju.mean() lie_mean = exl[['语文','数学','英语','总分数','平均分']].mean() lie_mean["姓名"] = "平均数" # lie_mean["总分数"] = "" # lie_mean["平均分"] = "" exl=exl.append(lie_mean,ignore_index=True) print(exl)
效果:
3.pandas对Excel数据去重
原数据
1.去重数据,drop_duplicates函数,参数subset=用来指定按照那一列或者那几列去重。多列传list。参数keep= 用来指定保留前面还是后面的数据。keep=‘first ’默认的保留前面的数据,keep='last' 保留后面的数据
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据去重.xlsx') exl = exl.drop_duplicates(subset='姓名',keep='last') print(exl)
效果:
2.找出重复数据:
1.找出重复数据的索引
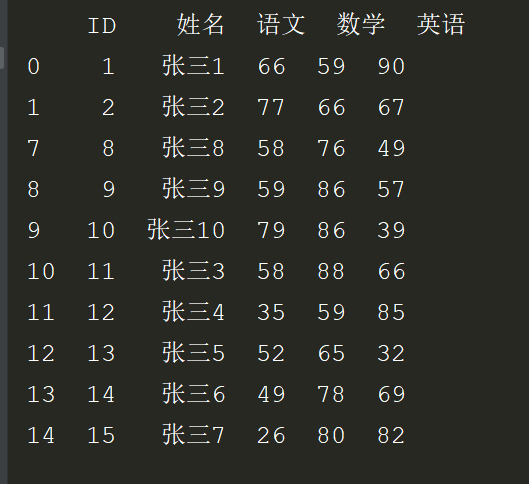
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据去重.xlsx') dupe = exl.duplicated(subset='姓名') #找出重复数据 dupe = dupe[dupe==True]#简写是dupe = dupe[dupe] print(dupe) # 有重复数据显示True # print(dupe.any())
效果是:
2.通过拿到这个索引来定位重复数据
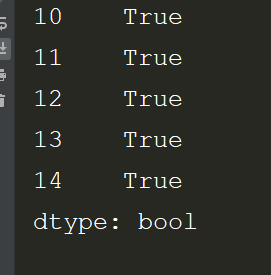
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('数据去重.xlsx') dupe = exl.duplicated(subset='姓名') #找出重复数据 dupe = dupe[dupe==True]#简写是dupe = dupe[dupe] exl_chong = exl.iloc[dupe.index] print(exl_chong)
效果:
3.pandas对Excel行列互换
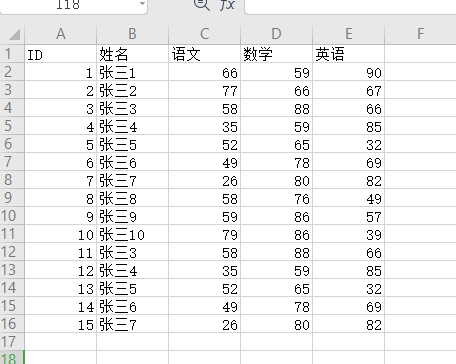
# *_*coding:utf-8 *_* # @Author : zyb import pandas as pd exl = pd.read_excel('行列互换.xlsx',index_col='姓名') exl = exl.transpose() print(exl)
效果:
