一. 概述
上次在介绍性能调优中讲到了I/O的开销查看及维护,这次介绍CPU的开销及维护, 在调优方面是可以从多个维度去发现问题如I/O,CPU, 内存,锁等,不管从哪个维度去解决,都能达到调优的效果,因为sql server系统作为一个整体性,它都是紧密相连的,例如:解决了sql语句中I/O开销较多的问题,那对应的CPU开销也会减少,反之解决了CPU开销最多的,那对应I/O开销也会减少。解决I/O开销后CPU耗时也减少,是因为CPU下的Worker线程需要扫描I/O页数就少了,出现的资源锁的阻塞也减少了,具体可参考cpu的原理。
下面sql语句的dmv:sys.dm_exec_query_stats和sys.dm_exec_sql_text 已经在上篇”sql server 性能调优 I/O开销分析“中有讲到。
--查询编译以来 cpu耗时总量最多的前50条(Total_woker_time) SELECT TOP 50 total_worker_time/1000 AS [总消耗CPU 时间(ms)], execution_count [运行次数], qs.total_worker_time/qs.execution_count/1000 AS [平均消耗CPU 时间(ms)], last_execution_time AS [最后一次执行时间], max_worker_time /1000 AS [最大执行时间(ms)], SUBSTRING(qt.text,qs.statement_start_offset/2+1, (CASE WHEN qs.statement_end_offset = -1 THEN DATALENGTH(qt.text) ELSE qs.statement_end_offset END -qs.statement_start_offset)/2 + 1) AS [使用CPU的语法], qt.text [完整语法], qt.dbid, dbname=db_name(qt.dbid), qt.objectid,object_name(qt.objectid,qt.dbid) ObjectName FROM sys.dm_exec_query_stats qs WITH(nolock) CROSS apply sys.dm_exec_sql_text(qs.sql_handle) AS qt WHERE execution_count>1 ORDER BY total_worker_time DESC
查询如下图所示,显示CPU耗时总量最多的前50条
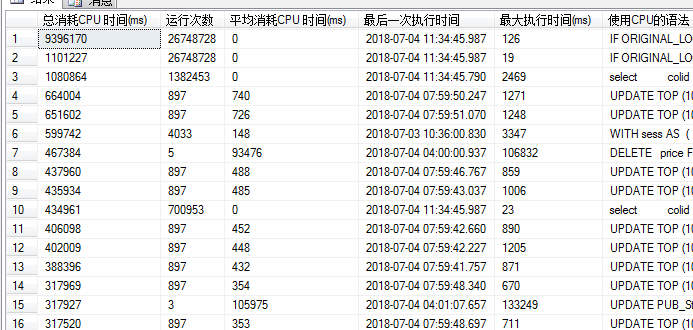
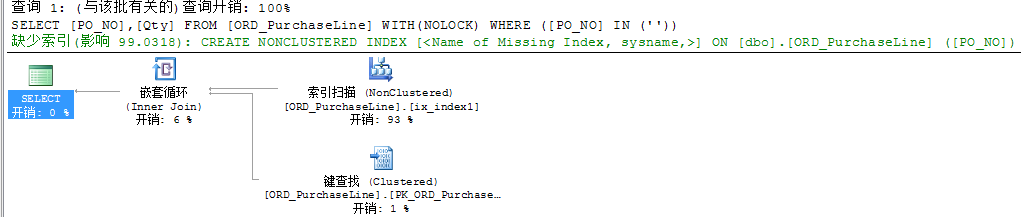
在排名第38条,拿出耗时的sql脚本来分析,发现未走索引。如下图

SELECT [PO_NO],[Qty] FROM [ORD_PurchaseLine] WITH(NOLOCK) WHERE ([PO_NO] IN (' '))
二. 维护注意点
1. 在生产数据库下,CPU耗时查询,并不限定只排查总耗时前50条,可以是前100~200条。具体看sql脚本没有没优化的需要,并不是每个表的查询都必须走索引。如:有的表不走索引时并不会感觉很耗时平均I/0次数少,表中已建的索引已有多个,增删改也频繁,还有索引占用空间,这时需要权衡。
-- 快速查看索引数量 sp_help [RFQ_PurDemandDetail]

2. 不要在工作时间维护大表索引
当我们排查到有的大表缺失索引,数据在100w以上,如果在工作时间来维护索引,不管是创建索引还是重建索引都会造成表的阻塞, 这里表的响应会变慢或者直接卡死,前端应用程序直接请求超时。这里需要注意的。来看下新建一个索引的脚本会发现 开启了行锁与页锁(ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)。
CREATE NONCLUSTERED INDEX [ix_createtime] ON [dbo].[PUB_Search_Log] ( [CreateTime] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO