一.概述
sql server在快速查询值时只有索引还不够,还需要知道操作要处理的数据量有多少,从而估算出复杂度,选择一个代价小的执行计划,这样sql server就知道了数据的分布情况。索引的统计值信息,还内置策略用来在没有索引的属性列上创建统计值。在有索引和没有索引的属性列上统计值信息会被自动维护。大部分场景下不需要手动去维护统计信息。
作用是 sqlserver 查询优化器使用统计信息来创建可提高查询性能的查询计划。 对于大多数查询,查询优化器已为高质量查询计划生成必要的统计信息。每个索引都会自动建立统计信息, 统计信息的准确性直接影响指令的速度,执行计划的选择是依据统计信息。
1.1 属性列统计值
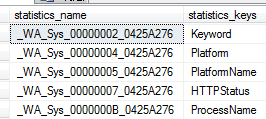
默认情况下,每当在一个查询的where子句中使用非索引属性列时,sqlserver会自动地创建统计值,统计名称以_WA_Sys开头。
-- 查看表中非索引的统计信息 sp_helpstats PUB_Search_Log
如下所示:
1.2 自动更新统计信息的阀值
在自动更新统计信息选项 AUTO_UPDATE_STATISTICS 为 ON 时,查询优化器将确定统计信息何时可能过期。查询优化器通过计算自最后统计信息更新后数据修改的次数并且将这一修改次数与某一阈值进行比较,确定统计信息何时可能过期。
(1)如果在评估时间统计信息时表基数为 500 或更低,则每达到 500 次修改时更新一次。
(2)如果在评估时间统计信息时表基数大于 500,则改变每达到 500 + 20%的行数更新一次(大表特别要注意更新时间)。
二. 统计信息分析
--查询统计信息 DBCC SHOW_STATISTICS(tablename,'indexname')
下面是一个复杂的统计信息,上一次更新统计信息时间是2018年5月8日,距离现在有二个多月没更新了,也就是说更新条件没有达到(改变达到500次 + 20%的行数变动)。
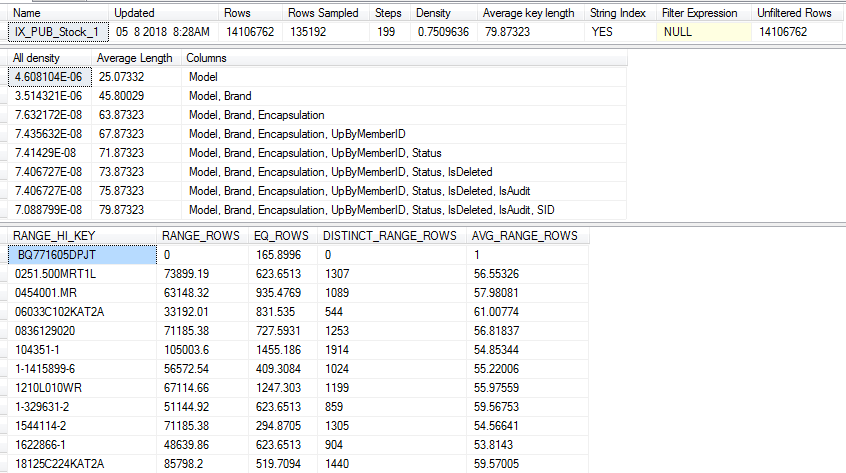
2.1 统计信息三部分:头信息,字段选择性,直方图。
(1) 头信息
name:统计信息名称,也是索引的名字。
updated:上一次统计信息更新时间(重要)。
rows:上一次统计表中的行数,反映了表里的数据量。
rows Sampled: 用于统计信息计算的抽样总行数。当表格数据比较大,为了降低消耗,只会取一小部分数据做抽样。 rows sampled<rows时候统计信息可能不是最精确的。
steps:把数据分成几组。最多200个组,每个直方图梯级都包含一个列值范围,后跟上限列值。
density:索引第一列前缀的选择性。查询优化器不使用此 Density, 值此值的目的是为了与 SQL Server 2008 之前的版本实现向后兼容。
average key length:索引列平均字节数。
string index: YES 代表字符串索引。
(2)数据字段选择性
all density: 反映了索引列的选择度。它反映了数据集里重复的数据量多少,如果数据很少有重复,那么它选择性就比较高。 密度为 1/非重复值。值越小选择性就越高。如果值小于了0.1,那索引的选择性就非常高了(这一点通过查看自增ID主键索引列,非常明显小于了0.1的值)。
average length: 索引列平均字节长度 例如model 列值平均长度是25个字节。
columns:索引列名称
(3)直方图(对应steps 组)
直方图度量数据集中每个非重复值的出现频率。 查询优化器根据统计信息对象第一个键列中的列值来计算直方图,它选择列值的方法是以统计方式对行进行抽样或对表或视图中的所有行执行完全扫描。
range_hi_key: 列值也称为键值。直方图里每一组(step)数据最大值 。上图值是model字符串类型
range_rows:每组数据区间估算数目。
eq_rows:表中值与直方图每组数据库上限相等的数目
distinct_range_rows:每组中非重复数目, 如果没有重复则range_rows等于distinct_range_rows值。
avg_range_rows:每组数据区间重复值平均数目, (range_rows)
三. 人工维护的几种情况
1.查询执行时间很长
如果查询响应时间很长或不可预知,则在执行其他故障排除步骤前,确保查询具有最新的统计信息。
2.在升序或降序键列上发生插入操作。
与查询优化器执行的统计信息更新相比,升序或降序键列(例如 IDENTITY 或实时时间戳列)上的统计信息可能要求更频繁地更新。插入操作将新值追加到升序或降序键列上
3.在维护操作后。
考虑在执行维护过程(例如截断表或对很大百分比的行执行大容量插入)后更新统计信息。 这可以避免在将来查询等待自动统计信息更新时在查询处理中出现延迟。
-- 更新统计信息 UPDATE STATISTICS tablename(indexname)
更新统计信息可确保查询使用最新的统计信息进行编译。 不过,更新统计信息会导致查询重新编译。 我们建议不要太频繁地更新统计信息,因为需要在改进查询计划和重新编译查询所用时间之间权衡性能。