一. 复制概述
mysql 从3.23版本开始提供复制功能,复制是指将主数据库的ddl和dml操作通过二进制日志传到复制服务器(也叫从服务器)上,然后在从服务器上对这些日志重新执行(也叫重做),从而使得从服务器和主服务器的数据保持同步。
mysql 支持一台主服务器同时向多台从服务器进行复制,从服务器同时也可以作为其他服务器的主服务器,实现链状的复制,默认情况下,复制是异步的,从库不需要永久连接以接收主库的更新,根据配置,可以复制数据库中的所有数据库,某些数据库,某些表。
mysql 复制的优点主要包括以下3个方面:
(1) 如果主服务器出现问题,可以快速切换到从服务器提供服务。
(2) 可以在从服务器上执行查询操作,降低主服务器的访问压力。
(3) 可以在从服务器上执行备份,以避免备份期间影响主服务器的服务。
注意:由于mysql实现的是异步复制,所以主从库之间存在一定的差距,在从库上查询操作需要考虑到这些数据的差异。一般只有更新不频繁的数据或者对实时性要求不高的数据可以通过从库查询,实时性要求高的仍然需要从主数据库获取。
二. 复制原理
(1) 首先mysql 主库在事务提交时会把数据变更作为事件events记录在二进制日志文件binlog中, mysql主库上的sync_binlog参数控制binlog日志刷新到磁盘。
(2) 主库推送二进制日志文件binlog中的事件到从库的中继日志relay log,之后从中继日志relay log 重做数据变更操作,通过逻辑复制以此来达到主库和从库的数据一致。
mysql 通过3个线程来完成主从库间的数据复制:其中binlog dump 线程跑在主库上,I/O线程和sql线程跑在从库上。当从库上启动复制(start slave)时,首先创建I/0线程连接主库,主库随后创建binlog dump线程读取数据库事件并发送给I/O线程,I/O线程获取事件数据后更新到从库的中继日志relay log中去,之后从库上的sql线程读取中继日志relay log中更新的数据库事件并应用。如下图所示:

三. 复制的选项
3.1 在mysql5.7 中支持不同的复制方法:
(1) 传统方法基于主机的二进制日志复制事件,并要求日志文件和它们的位置在主从之间同步。
(2) 新的方法是基于全局事务标识符(GTID)事务处理的,因此不需要处理这些文件中的日志文件或位置,这极大地简化了许多常见的复制任务。只要在主服务器上提交的所有事务应用于从服务器,使用GTID进行复制可确保主服务器和从服务器之间的一致性。
3.2 复制同步类型
MySQL中的复制支持不同类型的同步。(1)原始的同步是单向异步复制,(2)还支持半同步复制(在mysql 5.5 版本中开始)。
3.3 二进制日志文件binlog格式的三种方式
(1) Statement (SBR):基于SQL语句级的Binlog, 每条修改数据的SQL都会保存到Binlog里。
(2) Row(RBR): 基于行级别,记录每一行数据的变化,每行的数据的变化都记录到Binlog里面,记录非常详细,但并不记录原始SQL,记录的日志量比Statemnet 格式要大得多。
(3) Mixed(MBR):混合复制是混合Statement和Row,默认情况下采用Statement模式记录,某此情况下会切换到Row模式。
-- 查看具体使用的格式脚本如下(在5.7中默认使用Row格式)。: SHOW VARIABLES LIKE '%binlog_format'

四. 复制架构
复制有常见的三种架构:一主多从复制架构,多级复制架构,双主复制架构。
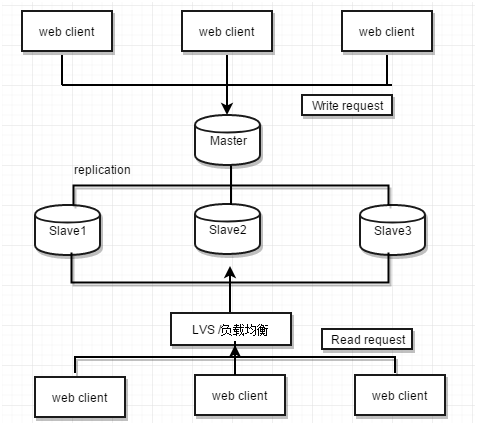
4.1 一主多从复制架构
在主库读取请求压力非常大的场景下,可以通过配置一主多从复制架构实现读写分离,把大量对实时性要求不高的读请求通过负载均衡分布到多个从库上,降低主库的读取压力,在主库出现异常down机后,可以把一个从库切换为主库继续提供服务。架构如下:
4.2 多级复制架构
一主多从的复制架构考虑到mysql的复制是主库"推送" binlog 日志到从库,从库的I/O压力和网络压力会随着从库的增加而增长(每个从库会在主库上有一个独立的binlog dump线程来发送事件),而多级复制架构解决了一主多从场景下,主库额外的I/O压力和网络压力,架构如下:
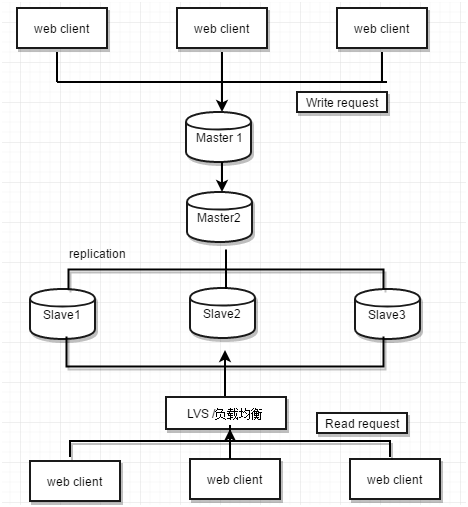
对比一主多从的架构图,多级复制仅是在主库Master1复制到从库Slave1, Slave2, Slave3 的中间增加了一个二级主库Master2。这样主库Master1只需要给一个从库Master2推送binlog日志皆可。二级主库Master2再推送binlog 日志给从库Slave1, Slave2, Slave3。
多级复制解决了一主多从场景下,主库的I/O压力和网络压力,缺点是mysql复制是异步,多级复制场景下主库的数据是要经历两次复制才到从库上。解决方法可以通过二级主库Master2上选择表引擎为 Blackhole 来降低多级复制的延时。Blackhole引擎的表数据并不会写回到磁盘上,Blackhole表永远都是一个空表(例如插入表数据,查询表也是没有的),insert,update,delete操作仅仅在binlog中记录事件。
Blackhole引擎非常 适合二级主库的场景, Master2并不承担读写请求,仅仅负责将binlog日志尽快传送给从库。
4.3 双主复制/Dual Master架构
双主复制特别适用于DBA做维护等需要主从切换场景,通过双主架构避免了重复搭建从库的麻烦,双主的架构如下:
Master1和Master2 互为主从,所有web client 客户端的写请求都访问主库Master1,而读可以选择Master1或Master2。 假如 DBA要做日常维护操作,为了避免影响服务,可以做如下步骤:
(1) 在Master1库上停止Slave线程(stop slave), 避免后续对Master2做维护操作时,实时复制到Master1库上,对Master1服务造成影响。
(2) 在Master2 库上停止Slave线程(stop slave), 开始日常维护操作,例如创建索引。
(3) 然后在Master2库上完成维护操作后,打开Master2 库上的Slave线程(start slave),让Master1库数据同步到Master2库,同步后,把应用的读写操作切换到Master2库上。
(4) 最后,确认Master1库无应用访问后,打开Master1库的Slave线程(start slave)。此时读写主库就在Master2库上了。
通过双主复制/Dual Master架构能架大大减轻一主多从架构下,对主库进行维护带来的额外搭建从库的工作。