划分的量
要保证数据来自一个分布
偏差方差分析
如果存在high bias
如果存在high variance
正则化
正则化减少过拟合的intuition
Dropout
dropout分析
其它正则化方法
数据增加(data augmentation)
early stopping
ensemble
归一化输入
归一化可以加速训练
归一化的步骤
归一化应该应用于:训练、验证、测试
梯度消失/爆炸
权重初始化
通过数值近似计算梯度
优化算法
mini-batch
momentum
RMSprop
Adam
调参
顺序
批规范化Batch Normalization
Reference
训练、验证、测试
划分的量
- If size of the dataset is 100 to 1000000 ==> 60/20/20
- If size of the dataset is 1000000 to INF ==> 98/1/1 or 99.5/0.25/0.25
要保证数据来自一个分布
偏差方差分析
如果存在high bias
- 尝试用更大的网络
- 尝试换一个网络模型
- 跑更长的时间
- 换不同的优化算法
如果存在high variance
- 收集更多的数据
- 尝试正则化方法
- 尝试一个不同的模型
如果存在high bias
- 尝试用更大的网络
- 尝试换一个网络模型
- 跑更长的时间
- 换不同的优化算法
如果存在high variance
- 收集更多的数据
- 尝试正则化方法
- 尝试一个不同的模型
一般来说更大的网络更好
正则化
正则化减少过拟合的intuition
太大会导致其为0
Dropout
- 原始的dropout
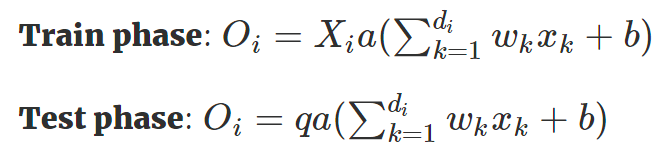
- Inverted Dropout
我们稍微将 Dropout 方法改进一下,使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。这个改进的 Dropout 方法就被称之为 Inverted Dropout 。比例因子将修改为是保留概率的倒数,即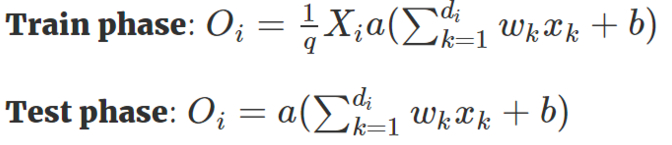
dropout分析
- 因为我们不能够过分依赖一个特征,dropout可以一定程度将权重分出去
- 我们可以在不同的层设置不同的dropout
- 输入层的dropout应该接近1,因为我们需要从中学习信息
- CNN中dropout广泛应用
- dropout带来的问题是调试困难,通常我们需要关掉dropout调试,确认无误再继续用dropout
其它正则化方法
数据增加(data augmentation)
我们稍微将 Dropout 方法改进一下,使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。这个改进的 Dropout 方法就被称之为 Inverted Dropout 。比例因子将修改为是保留概率的倒数,即
数据增加(data augmentation)
就是通过一些变换得到新的图片(这种其实是在图像领域最为广泛应用,但是思想可以推广)
early stopping
就是在迭代中选择验证错误不再降低的点
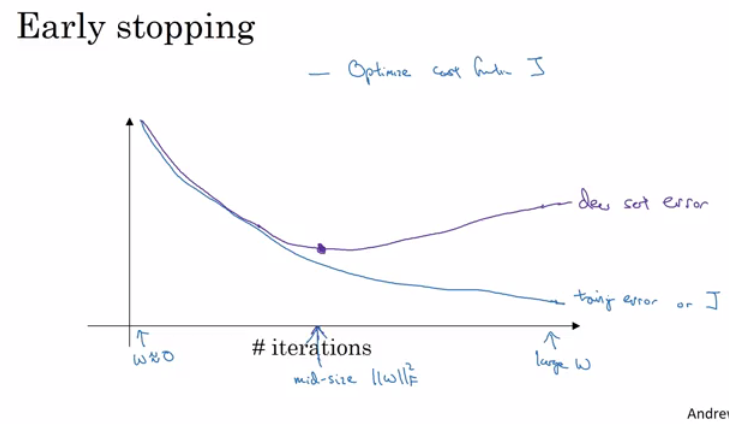
好处是不用调超参,坏处是it makes us think about something else more than optimize W's and b's.
ensemble
训练多个模型,组合
可以带来2%左右的提升,减少泛化误差
归一化输入
归一化可以加速训练
归一化的步骤
- 计算均值
- 所有数据减去均值
- 计算方差
x/=variance
归一化应该应用于:训练、验证、测试
梯度消失/爆炸
x/=variance这是训练深度学习难的一个点
权重初始化
是解决梯度消失/爆炸的一个部分的解决方案
对于sigmoid和tanh
np.random.rand(shape)*np.sqrt(1/n[l-1]) 对于relu
np.random.rand(shape)*np.sqrt(2/n[l-1]) #n[l-1] In the multiple layers.一个方差是,另一个是
通过数值近似计算梯度
- 注意添加正则项的损失函数
优化算法
mini-batch
- 为了利用向量化,batch大小应该是2的指数
- 注意CPU/GPU内存大小
momentum
mini-batch
- 为了利用向量化,batch大小应该是2的指数
- 注意CPU/GPU内存大小
momentum
计算权重的指数加权平均
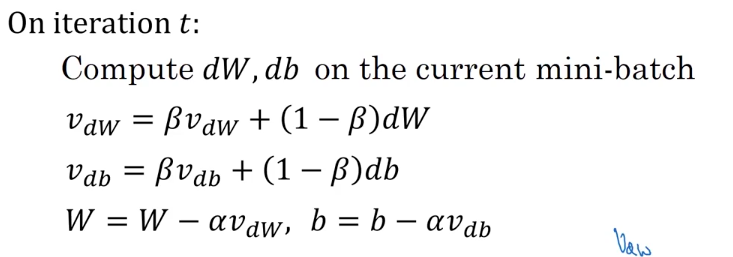
RMSprop
Root mean square prop

使用这个算法可以选择较大的学习率
Adam
Adaptive Momentum Estimation。其实就是把rmsprop和momentem放一起了,另加了一个纠正
其中推荐, ,
深度神经网络中的主要问题不是局部最小点,因为在高维空间中出现局部最优的可能性很小,但是很容易出现鞍点,鞍点会导致训练很慢,所以上面的几个方法会很有用
调参
顺序
Learning rate.
Mini-batch size.
No. of hidden units.
Momentum beta.
No. of layers.
Use learning rate decay?
Adam beta1 & beta2
regularization lambda
Activation functions
批规范化Batch Normalization
可以加速训练
和前面的对于输入数据的处理不一样,这里考虑的是对于隐层,我们能否对A[l]进行操作,使得训练加快。

这里和是参数
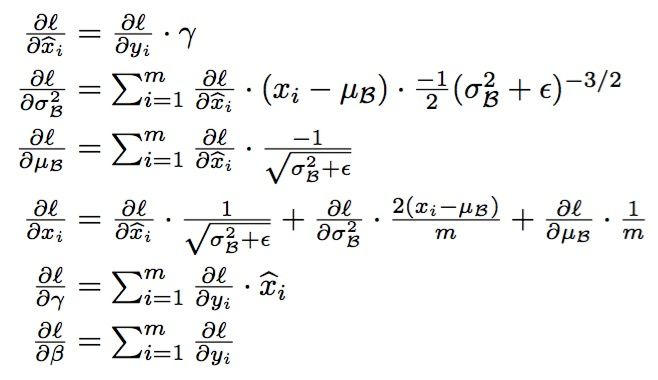
解决了梯度弥散的问题
批规范化其实做了一点正则化的工作,如果你希望减弱这种效果可以增大批大小。
测试用需要估计均值和方差
Reference
https://github.com/mbadry1/DeepLearning.ai-Summary