CNN学习笔记:正则化缓解过拟合
过拟合现象
在下图中,虽然绿线完美的匹配训练数据,但太过依赖,并且与黑线相比,对于新的测试数据上会具有更高的错误率。虽然这个模型在训练数据集上的正确率很高,但这个模型却很难对从未见过的数据做出正确响应,认为该模型存在过拟合现象。
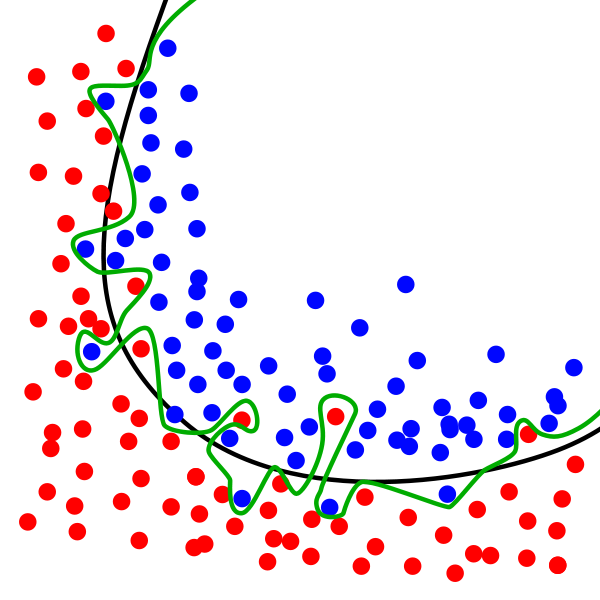
绿线代表过拟合模型,黑线代表正则化模型。故我们使用正则化来解决过拟合问题。
正则化模型
正则化是机器学习中通过显示控制模型复杂度来避免模型过拟合、确保泛化能力的一种有效方式。正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化了训练数据中的噪声。
L2正则化
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和。假设待正则的网络层参数为w,l2正则化形式为:
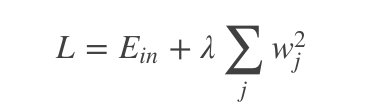
其中,Ein 是未包含正则化项的训练样本误差,λ控制正则项大小,较大的λ取值将较大程度约束模型复杂度;反之亦然。实际使用时,一般将正则项加入目标函数(损失函数),通过整体目标函数的误差反向传播,从而达到正则项影响和指导网络训练的目的。
L2正则化在深度学习中有一个常用的叫法是“权重衰减”,另外L2正则化在机器学习中还被称为“岭回归”或Tikhonov正则化。
L1正则化
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值。假设待正则的网络层参数为w,L1正则化为:
![]()
L1正则化除了同L2正则化一样能约束参数量级外,L1正则化还可以使得参数更稀疏,使得优化后的参数的一部分为0,另一部分为非0实值。
Tensorflow实现
tf.contrib.layers.l1_regularizer() tf.contrib.layers.l2_regularizer()
Keras实现
from keras.regularizers import l2 model.add(Dense(units=200,input_dim=784,activation='tanh',kernel_regularizer=l2(0.01)))
Dropout随机失活
随机失活是目前几乎所有配备全连接层的深度卷积神经网络都在使用的网络正则化方法。随机失活在约束网络复杂度的同时,还是一种针对深度模型的高效集成学习方法。
传统神经网络中,由于神经元件的互联,对于某单个神经元来说,其反向传导来的梯度信息同时也受到其他神经元的影响,可谓“牵一发而动全身”。这就是所谓的“复杂协同适应”效应。随机失活的提出正是一定程度上缓解了神经元之间复杂的协同适应,降低了神经元间依赖,避免了网络过拟合的发生。
原理非常简单,对于某层的每个神经元,在训练阶段以概率P随机将该神经元权重重置为0,测试阶段所有神经元均呈激活状态,但其权重需乘(1-p)以保证训练和测试阶段各种权重拥有相同的期望,输入层和隐藏层都能应用dropout。
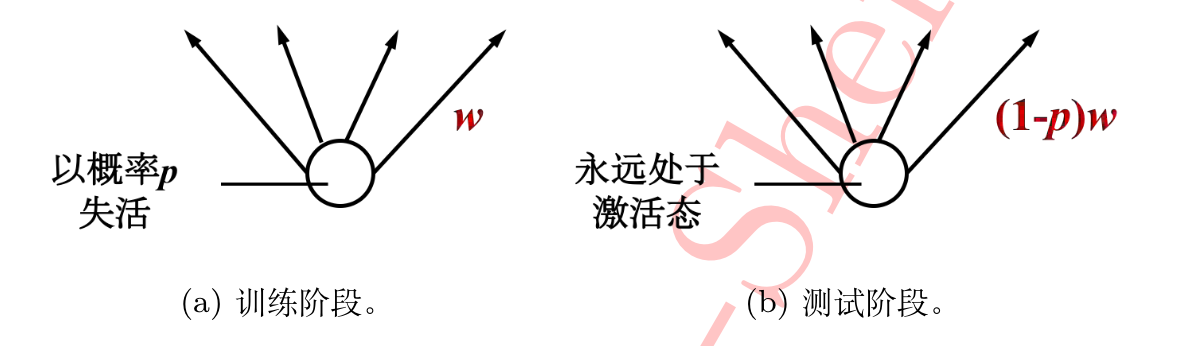
在Keras中示例
from keras.layers.core import Dropout model = Sequential([ Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'), Dropout(0.25), Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'), ])