什么是数据库
定义
数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息等等。除了文本类型的数据,图像、音乐、声音都是数据。数据一般存储在内存、硬盘。
发展现状
在数据库的发展历史上,数据库先后经历了层次数据库、网状数据库和关系数据库等各个阶段的发展,数据库技术在各个方面的快速的发展。特别是关系型数据库已经成为目前数据库产品中最重要的一员,80年代以来, 几乎所有的数据库厂商新出的数据库产品都支持关系型数据库,即使一些非关系数据库产品也几乎都有支持关系数据库的接口。这主要是传统的关系型数据库可以比较好的解决管理和存储关系型数据的问题。随着云计算的发展和大数据时代的到来,关系型数据库越来越无法满足需要,这主要是由于越来越多的半关系型和非关系型数据需要用数据库进行存储管理,以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求,于是越来越多的非关系型数据库就开始出现,这类数据库与传统的关系型数据库在设计和数据结构有了很大的不同, 它们更强调数据库数据的高并发读写和存储大数据,这类数据库一般被称为NoSQL(Not only SQL)数据库。 而传统的关系型数据库在一些传统领域依然保持了强大的生命力。
数据库基本概念
库:多表构建一个数据库(存放多张表),本质是一个文件夹
表:多条数据构建一张表(包含多条相同结构的记录),本质就是文件
记录:存放一条条数据(包含多个key-value键值对的一条数据),本质就是文件中一条条数据记录(二进制数据)
数据库分类
关系数据库
关系型数据库,存储的格式可以直观地反映实体间的关系。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。 常见的关系型数据库有Mysql,SqlServer等。在轻量或者小型的应用中,使用不同的关系型数据库对系统的性能影响不大,但是在构建大型应用时,则需要根据应用的业务需求和性能需求,选择合适的关系型数据库。
关系型数据库对于结构化数据的处理更合适,如学生成绩、地址等,这样的数据一般情况下需要使用结构化的查询,例如join,这样的情况下,关系型数据库就会比NoSQL数据库性能更优,而且精确度更高。由于结构化数据的规模不算太大,数据规模的增长通常也是可预期的,所以针对结构化数据使用关系型数据库更好。关系型数据库十分注意数据操作的事务性、一致性,如果对这方面的要求关系型数据库无疑可以很好的满足。
总结:关系型数据库由表的概念,是以表中一条条记录存储数据,对于结构化数据的处理更合适。
非关系型数据库(NoSQL)
随着近些年技术方向的不断拓展,大量的NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。
指的是分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。NoSQL数据库技术与CAP理论、一致性哈希算法有密切关系。所谓CAP理论,简单来说就是一个分布式系统不可能满足可用性、一致性与分区容错性这三个要求,一次性满足两种要求是该系统的上限。而一致性哈希算则指的是NoSQL数据库在应用过程中,为满足工作需求而在通常情况下产生的一种数据算法,该算法能有效解决工作方面的诸多问题但也存在弊端,即工作完成质量会随着节点的变化而产生波动,当节点过多时,相关工作结果就无法那么准确。这一问题使整个系统的工作效率受到影响,导致整个数据库系统的数据乱码与出错率大大提高,甚至会出现数据节点的内容迁移,产生错误的代码信息。但尽管如此,NoSQL数据库技术还是具有非常明显的应用优势,如数据库结构相对简单,在大数据量下的读写性能好;能满足随时存储自定义数据格式需求,非常适用于大数据处理工作。
NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。 [5] 对于非结构化数据的处理更合适,如文章、评论,这些数据如全文搜索、机器学习通常只用于模糊处理,并不需要像结构化数据一样,进行精确查询,而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的,而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。NoSQL数据库利用key-value可以大量的获取大量的非结构化数据,并且数据的获取效率很高,但用它查询结构化数据效果就比较差。
目前NoSQL数据库仍然没有一个统一的标准,它现在有四种大的分类:
(1)键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。 [3]
(2)列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。 [3]
(3)文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。 [3]
(4)图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
总结:非关系数据库没有表的概念,是以key-value键值对方式存储数据
数据库启动与连接
启动服务端
在安装完成后先将文件夹下的bin的地址配置到path环境变量中
先进行搜索:服务,检索mysql服务
如果有停止服务,并移除服务(启动管理员终端输入mysqld --remove)
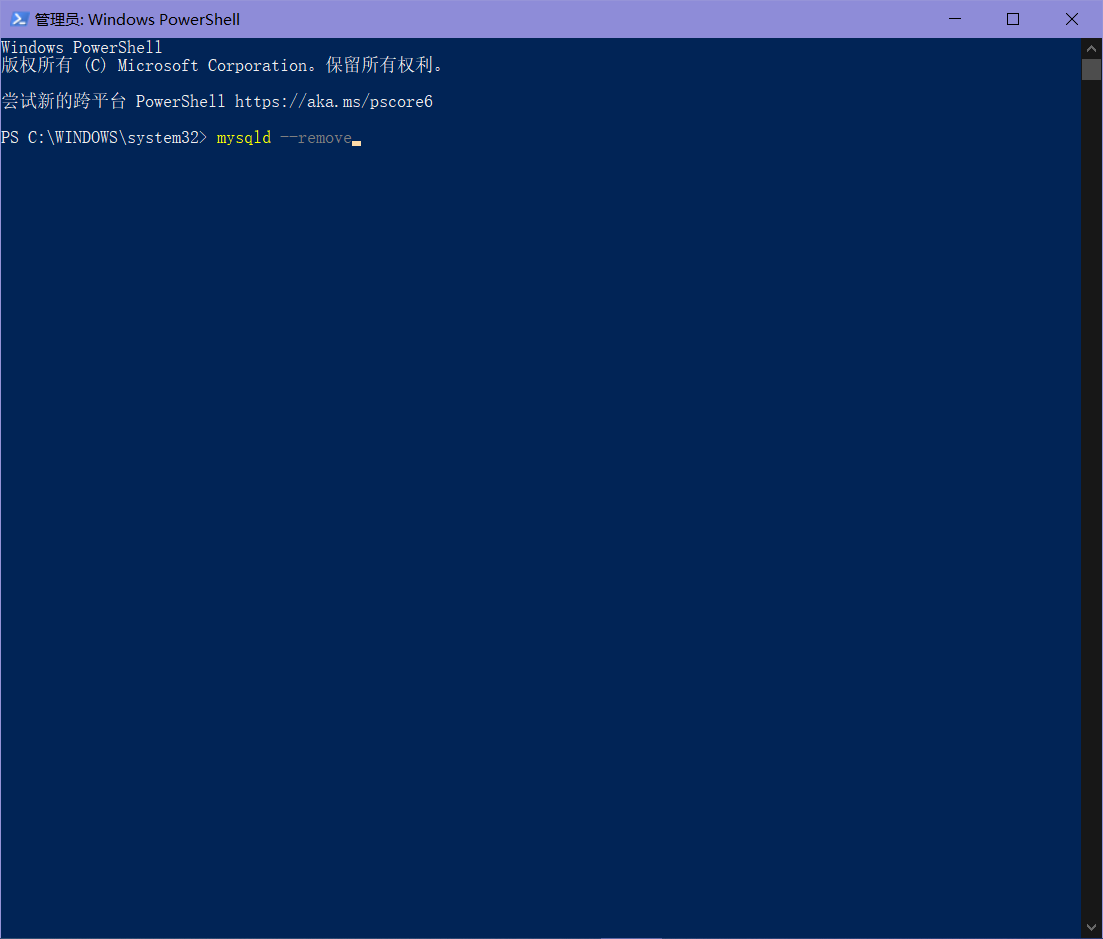
如果无,则在管理员终端输入mysqld install,再输入mysqld start
连接数据库
-
游客登录
>:mysql -
账号密码登录
>:mysql -uroot -p #回车后输入密码,如果没有密码就直接回车,也可先将密码写在-p后再回车(没设密码就直接回车) -
连接指定服务器的MySQL
>:mysql -h ip地址 -p端口号 -u账号 -p密码 #举例: >: mysql -hlocalhost -P3306 -uroot -p -
退出数据库
>:quit >:exit
用户信息查看
-
查看当前用户
>: select user(); -
没有登录的情况下,修改密码
>: mysqladmin -u用户名 -p旧密码 -h域名 password "新密码" 例>: mysqladmin -uroot -p12345678 -hlocalhost password "root" -
root权限下可以查看所有用户信息
>: select * from mysql.user; >: select * from mysql.user G >: select user,password,host from mysql.user; -
root登录下,删除游客(操作后要重启MySQL服务)
>: delete from mysql.user where user=''; -
root登录下,修改密码(操作后要重启MySQL服务)
>: update mysql.user set password=password('12345678') where host='localhost'; ``` -
root登录下,创建用户
>:grant 权限们 on 数据库名.表名 to 用户名@主机名 identified by '密码';
数据库的基本操作
-
查看已有数据库
>:show databases; -
选择某个数据库
>:use 数据库名 -
查看当前所在数据库
>:select database(); -
创建数据库
>:create database 数据库名 [charset=编码格式]; -
查看数据库的详细内容
>:show create database 数据库名; -
删除数据库
>: drop database 数据库名;
表的基本操作
前提:先选取要操作的数据库
-
查看已有表
>:show tables; -
创建表
>:create table 表名(字段们); -
查看创建表的sql
>:show create table 表名; -
查看创建表的结构
>:desc 表名; -
删除表
>: drop table 表名;
记录的基本操作
-
查看某个数据库中的某个表的所有记录(如果在对应数据库中,可以直接查看表)
>: select * from [数据库名.]表名; -
给表的所有字段插入数据
>: insert [into] [数据库名.]表名 values (值1,...,值n); -
根据条件修改指定内容
>: update [数据库名.]表名 set 字段1=新值1, 字段n=新值n where 字段=旧值; -
根据条件删除记录
>: delete from [数据库名.]表名 where 条件;