1、集群配置
1、集群的规划
三台机器进行相关的不同的部署

注意:
NameNode和SecondaryNameNode占用内存是1:1,要求他俩不在一个节点上。
ResourceManager是整个资源管理器的龙头需要避开NameNode和SeconddarynameNode
2、配置集群
hadoop2配置
1、核心配置文件(core-site.xml)

<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</configuration>
2、HDFS配置文件
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_131
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop4:50090</value>
</property>
</configuration>
3、yarn配置文件
配置yarn-env.sh的java环境变量
# some Java parameters
export JAVA_HOME=/opt/jdk1.8.0_131
配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
4、MapReduce配置文件
配置mapred-env.sh的java环境变量
export JAVA_HOME=export JAVA_HOME=/opt/jdk1.8.0_131
配置mapred-site.xml
使用命令进行重命名
mv mapred-site.xml.template mapred-site.xml
进行配置
<configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、进行同部
[root@hadoop2 hadoop]# xsync /opt/module/hadoop-2.7.2/
fname=hadoop-2.7.2
pdir=/opt/module
------------------- hadoop3 --------------
root@hadoop3's password:
sending incremental file list
hadoop-2.7.2/etc/hadoop/core-site.xml
hadoop-2.7.2/etc/hadoop/hadoop-env.sh
hadoop-2.7.2/etc/hadoop/hdfs-site.xml
hadoop-2.7.2/etc/hadoop/mapred-env.sh
hadoop-2.7.2/etc/hadoop/mapred-site.xml
hadoop-2.7.2/etc/hadoop/yarn-env.sh
hadoop-2.7.2/etc/hadoop/yarn-site.xml
sent 29,961 bytes received 391 bytes 5,518.55 bytes/sec
total size is 249,336,011 speedup is 8,214.81
------------------- hadoop4 --------------
root@hadoop4's password:
sending incremental file list
hadoop-2.7.2/etc/hadoop/core-site.xml
hadoop-2.7.2/etc/hadoop/hadoop-env.sh
hadoop-2.7.2/etc/hadoop/hdfs-site.xml
hadoop-2.7.2/etc/hadoop/mapred-env.sh
hadoop-2.7.2/etc/hadoop/mapred-site.xml
hadoop-2.7.2/etc/hadoop/yarn-env.sh
hadoop-2.7.2/etc/hadoop/yarn-site.xml
sent 29,961 bytes received 391 bytes 3,570.82 bytes/sec
total size is 249,336,011 speedup is 8,214.81
2、集群单点启动
1、如果集群是第一次启动,需要格式化NameNode
[root@hadoop2 hadoop-2.7.2]# bin/hdfs namenode -format
2、分别启动节点
hadoop2上
[root@hadoop2 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop2.out
[root@hadoop2 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop2.out
[root@hadoop2 hadoop-2.7.2]# jps
3778 Jps
3621 NameNode
3706 DataNode
[root@hadoop2 hadoop-2.7.2]#
hadoop3
[root@hadoop3 hadoop-2.7.2]# sbin/hadoop-daemon.sh start
datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop3.out
[root@hadoop3 hadoop-2.7.2]# jps
3652 DataNode
3688 Jps
[root@hadoop3 hadoop-2.7.2]#
hadoop4
[root@hadoop4 hadoop-2.7.2]# sbin/hadoop-daemon.sh start
datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop4.out
[root@hadoop4 hadoop-2.7.2]# jps
3256 DataNode
3292 Jps
[root@hadoop4 hadoop-2.7.2]#
注意:在hadoop102、hadoop103以及hadoop104上分别启动DataNode
思考:每次都一个一个节点启动,如果节点数增加到1000个怎么办?
此时需要使用ssh无密码登陆配置
3、SSH无密码登陆配置
小演示:
[root@hadoop2 hadoop-2.7.2]# ssh hadoop3
root@hadoop3's password:
Last login: Sun Jul 21 04:34:06 2019 from desktop-shrmqh1
[root@hadoop3 ~]# hostname
hadoop3
[root@hadoop3 ~]#
[root@hadoop3 ~]#
[root@hadoop3 ~]# exit
免密登陆原理:
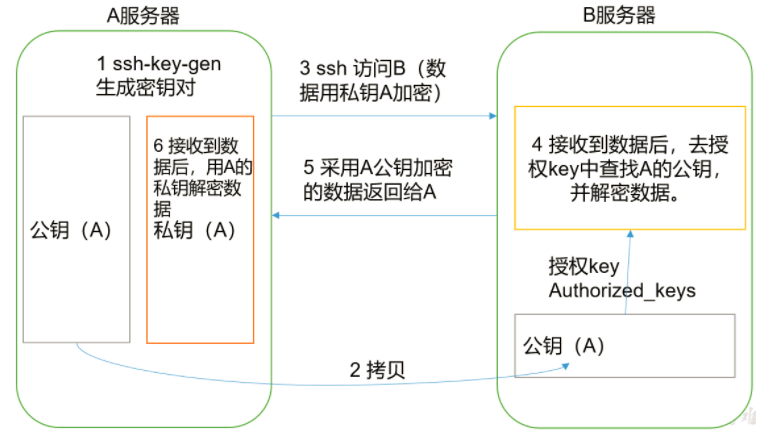
hadoop1
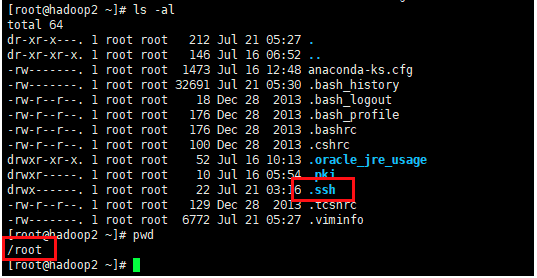
[root@hadoop2 ~]# cd .ssh/
[root@hadoop2 .ssh]# pwd
/root/.ssh
进行生成密钥
[root@hadoop2 .ssh]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:Qet88Bq/J/ko+1MQYjHxAOeGKOwczVFu3Z8gg+Pf5Qk root@hadoop2
The key's randomart image is:
+---[RSA 2048]----+
| ..o.Bo |
| . o + Bo*. |
| + + *.X.+. |
| o o o = *.o . |
| o . S E.+ |
| . * +.. |
| o ooo |
| . +o. |
| .++=. |
+----[SHA256]-----+
查看生成的公钥和私钥
[root@hadoop2 .ssh]# ll
total 12
-rw-------. 1 root root 1675 Jul 21 05:54 id_rsa
-rw-r--r--. 1 root root 394 Jul 21 05:54 id_rsa.pub
-rw-r--r--. 1 root root 367 Jul 21 03:17 known_hosts
进行拷贝id到hadoop3、hadoop4
[root@hadoop2 ~]# ssh-copy-id hadoop3
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop3'"
and check to make sure that only the key(s) you wanted were added.
同时还要拷贝到自身

注意:
还需要在hadoop2上采用root账号,配置一下无密登录到hadoop2、hadoop3、hadoop4;
还需要在hadoop3上采用其他账号配置一下无密登录到hadoop2、hadoop3、hadoop4服务器上
注意:hadoop3也需要进行生工公钥和私钥
因为该机器上又ResourceManager,然后进行hadoop2、hadoop4上进行拷贝
.ssh文件夹下(~/.ssh)的文件功能解释

4、群起集群
1、配置slaves

不允许有空格,不允许有空行

其他两台机器进行分发
[root@hadoop2 hadoop]# xsync slaves
2、启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
bin/hdfs namenode -format
(2)启动HDFS(包括namenode和datanode)
命令:[root@hadoop2 hadoop-2.7.2]# sbin/start-dfs.sh
[root@hadoop2 hadoop-2.7.2]# sbin/start-dfs.sh Starting namenodes on [hadoop2] hadoop2: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop2.out hadoop2: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop2.out hadoop3: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop3.out hadoop4: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop4.out Starting secondary namenodes [hadoop4] hadoop4: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop4.out
此时需要要进行对比

(3)启动YARN
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动
YARN,应该在ResouceManager所在的机器上启动YARN。
hadoop3上进行启动
[root@hadoop3 hadoop-2.7.2]# sbin/start-yarn.sh
[root@hadoop3 hadoop-2.7.2]# sbin/start-yarn.sh
starting yarn daemons
resourcemanager running as process 4249. Stop it first.
hadoop2: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop2.out
hadoop3: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop3.out
hadoop4: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop4.out
此时需要要进行对比

此时访问
http://hadoop2:50070是成功的

4、集群的基本测试
1、进行上传文件
[root@hadoop2 hadoop-2.7.2]# bin/hdfs dfs -put wcinput/wc.input /

此时是上传成功的
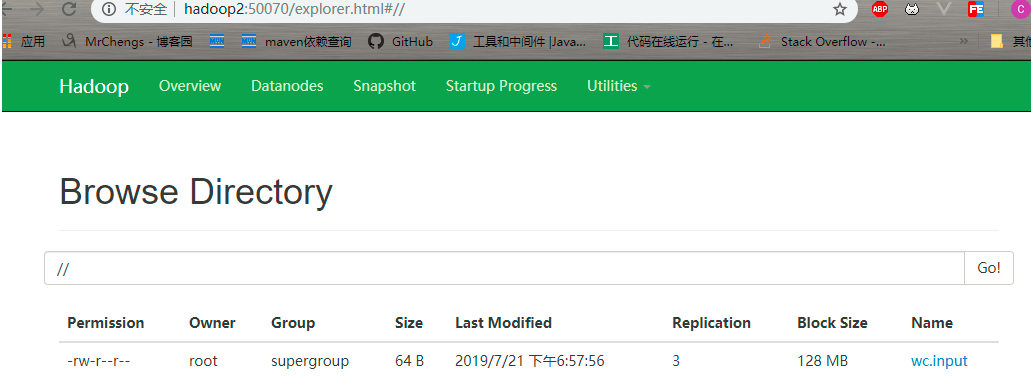
此时可以发现复本数
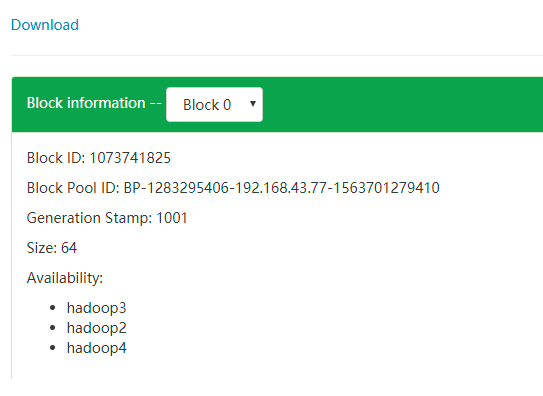
问题:数据存在那?
注意:小文件是一个,大文件可能进行分割成不同的文件夹
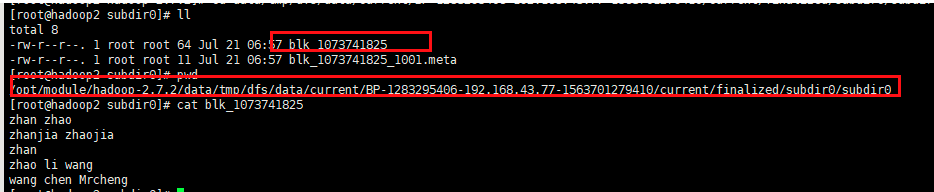
5、集群启动和停止的方式
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2. 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh