我是参照《Hadoop in action》完成示例程序。
如果是在eclipse下需要将 hadoop-datajoin-xxx.jar 导入工程的Library中。
另外新的API已经不再使用mapper,reducer接口,而Datajoin中DataJoinMapperBase,DataJoinReducerBase都是实现前两个的接口,所以job.setMapperClass会出错。只能使用旧的jobconf。
若完全按照书上的示例,会出现问题,如下错误:
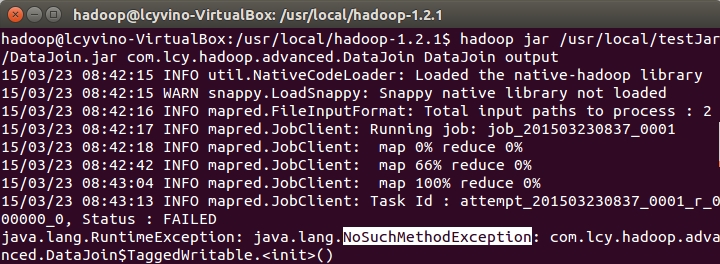
终于在stackoverflow上找到了解决办法:
解决方案是为TaggedWritable 类加一个无参构造方法。
原因是Hadoop uses reflection to create this object, and requires a default constructor (no args).
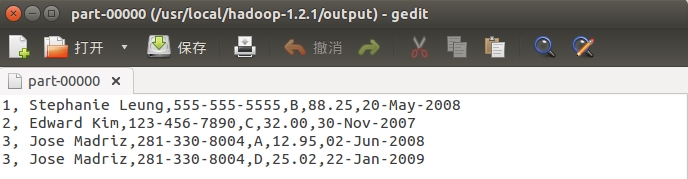
要处理的两个文本的文本内容如下:
Customers
1,Stephanie Leung,555-555-5555 2,Edward Kim,123-456-7890 3,Jose Madriz,281-330-8004 4,David Stork,408-555-0000
Orders
3,A,12.95,02-Jun-2008 1,B,88.25,20-May-2008 2,C,32.00,30-Nov-2007 3,D,25.02,22-Jan-2009
程序如下:
package com.lcy.hadoop.advanced;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.contrib.utils.join.DataJoinMapperBase;
import org.apache.hadoop.contrib.utils.join.DataJoinReducerBase;
import org.apache.hadoop.contrib.utils.join.TaggedMapOutput;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class DataJoin extends Configured implements Tool {
public static class MapClass extends DataJoinMapperBase {
protected Text generateInputTag(String inputFile) {
String datasource = inputFile.split("-")[0];
return new Text(datasource);
}
protected Text generateGroupKey(TaggedMapOutput aRecord) {
String line = ((Text) aRecord.getData()).toString();
String[] tokens = line.split(",");
String groupKey = tokens[0];
return new Text(groupKey);
}
protected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv = new TaggedWritable((Text) value);
retv.setTag(this.inputTag);
return retv;
}
}
public static class Reduce extends DataJoinReducerBase {
protected TaggedMapOutput combine(Object[] tags, Object[] values) {
if (tags.length < 2)
return null;
String joinedStr = " ";
for (int i = 0; i < values.length; i++) {
if (i > 0)
joinedStr += ",";
TaggedWritable tw = (TaggedWritable) values[i];
String line = ((Text) tw.getData()).toString();
String[] tokens = line.split(",", 2);
joinedStr += tokens[1];
}
TaggedWritable retv = new TaggedWritable(new Text(joinedStr));
retv.setTag((Text) tags[0]);
return retv;
}
}
public static class TaggedWritable extends TaggedMapOutput {
private Writable data;
public TaggedWritable() {
this.tag = new Text();
}
public TaggedWritable(Writable data) {
this.tag = new Text("");
this.data = data;
}
public Writable getData() {
return data;
}
public void setData(Writable data) {
this.data = data;
}
public void write(DataOutput out) throws IOException {
this.tag.write(out);
out.writeUTF(this.data.getClass().getName());
this.data.write(out);
}
public void readFields(DataInput in) throws IOException {
this.tag.readFields(in);
String dataClz = in.readUTF();
if (this.data == null
|| !this.data.getClass().getName().equals(dataClz)) {
try {
this.data = (Writable) ReflectionUtils.newInstance(
Class.forName(dataClz), null);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
this.data.readFields(in);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, DataJoin.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("DataJoin");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TaggedWritable.class);
job.set("mapred.textoutputformat.separator", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new DataJoin(), args);
System.exit(res);
}
}
运行过程:
hadoop@lcyvino-VirtualBox:/usr/local/hadoop-1.2.1$ hadoop jar /usr/local/testJar/DataJoin.jar com.lcy.hadoop.advanced.DataJoin DataJoin output
15/03/23 09:25:55 INFO util.NativeCodeLoader: Loaded the native-hadoop library
15/03/23 09:25:55 WARN snappy.LoadSnappy: Snappy native library not loaded
15/03/23 09:25:55 INFO mapred.FileInputFormat: Total input paths to process : 2
15/03/23 09:25:56 INFO mapred.JobClient: Running job: job_201503230837_0006
15/03/23 09:25:57 INFO mapred.JobClient: map 0% reduce 0%
15/03/23 09:26:11 INFO mapred.JobClient: map 33% reduce 0%
15/03/23 09:26:12 INFO mapred.JobClient: map 66% reduce 0%
15/03/23 09:26:31 INFO mapred.JobClient: map 100% reduce 0%
15/03/23 09:26:39 INFO mapred.JobClient: map 100% reduce 100%
15/03/23 09:26:40 INFO mapred.JobClient: Job complete: job_201503230837_0006
15/03/23 09:26:40 INFO mapred.JobClient: Counters: 30
15/03/23 09:26:40 INFO mapred.JobClient: Job Counters
15/03/23 09:26:40 INFO mapred.JobClient: Launched reduce tasks=1
15/03/23 09:26:40 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=46742
15/03/23 09:26:40 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
15/03/23 09:26:40 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
15/03/23 09:26:40 INFO mapred.JobClient: Launched map tasks=3
15/03/23 09:26:40 INFO mapred.JobClient: Data-local map tasks=3
15/03/23 09:26:40 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=27832
15/03/23 09:26:40 INFO mapred.JobClient: File Input Format Counters
15/03/23 09:26:40 INFO mapred.JobClient: Bytes Read=211
15/03/23 09:26:40 INFO mapred.JobClient: File Output Format Counters
15/03/23 09:26:40 INFO mapred.JobClient: Bytes Written=195
15/03/23 09:26:40 INFO mapred.JobClient: FileSystemCounters
15/03/23 09:26:40 INFO mapred.JobClient: FILE_BYTES_READ=893
15/03/23 09:26:40 INFO mapred.JobClient: HDFS_BYTES_READ=533
15/03/23 09:26:40 INFO mapred.JobClient: FILE_BYTES_WRITTEN=235480
15/03/23 09:26:40 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=195
15/03/23 09:26:40 INFO mapred.JobClient: Map-Reduce Framework
15/03/23 09:26:40 INFO mapred.JobClient: Map output materialized bytes=905
15/03/23 09:26:40 INFO mapred.JobClient: Map input records=8
15/03/23 09:26:40 INFO mapred.JobClient: Reduce shuffle bytes=905
15/03/23 09:26:40 INFO mapred.JobClient: Spilled Records=16
15/03/23 09:26:40 INFO mapred.JobClient: Map output bytes=871
15/03/23 09:26:40 INFO mapred.JobClient: Total committed heap usage (bytes)=407777280
15/03/23 09:26:40 INFO mapred.JobClient: CPU time spent (ms)=4640
15/03/23 09:26:40 INFO mapred.JobClient: Map input bytes=199
15/03/23 09:26:40 INFO mapred.JobClient: SPLIT_RAW_BYTES=322
15/03/23 09:26:40 INFO mapred.JobClient: Combine input records=0
15/03/23 09:26:40 INFO mapred.JobClient: Reduce input records=8
15/03/23 09:26:40 INFO mapred.JobClient: Reduce input groups=4
15/03/23 09:26:40 INFO mapred.JobClient: Combine output records=0
15/03/23 09:26:40 INFO mapred.JobClient: Physical memory (bytes) snapshot=464510976
15/03/23 09:26:40 INFO mapred.JobClient: Reduce output records=4
15/03/23 09:26:40 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1395036160
15/03/23 09:26:40 INFO mapred.JobClient: Map output records=8
合并结果: