Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr 配置
1 修改tomcat下的创建好的solr项目(web应用)的web.xml配置文件
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/work/solr-work/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
2 创建文件夹 D:/work/solr-work/solr 在这个文件夹下我们可以创建多个工作核心(每个工作核心需要添加在solr.xml文件中)
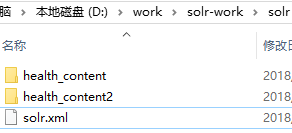
solr.xml配置如下:
<cores adminPath="/admin/cores" host="${host:}" hostPort="${jetty.port:8983}" hostContext="${hostContext:solr}">
<core name="order" instanceDir="order" />
<core name="indexdrug" instanceDir="indexdrug" />
<core name="indexstore" instanceDir="indexstore" />
<core name="storedrug" instanceDir="storedrug" />
<core name="health_content" instanceDir="health_content" />
<core name="health_content2" instanceDir="health_content2" />
<shardHandlerFactory name="shardHandlerFactory" class="HttpShardHandlerFactory">
<str name="urlScheme">${urlScheme:}</str>
</shardHandlerFactory>
</cores>
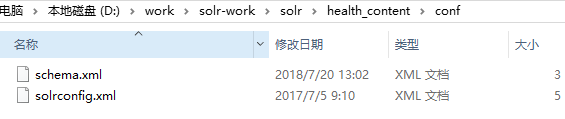
每个工作核心下包含两个大目录
(1) conf 结构如下
(2)data (在index中放建立的索引)
schema.xml的配置如下:
<schema name="example core zero" version="1.5">
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="int" class="solr.IntField"/>
<fieldtype name="text" class="solr.TextField" sortMissingLast="true" omitNorms="true"/>
<!-- general
<fieldType name="plong" class="solr.LongField"/>
<fieldType name="pfloat" class="solr.FloatField"/>
<fieldType name="pdouble" class="solr.DoubleField"/>
<fieldType name="pdate" class="solr.DateField" sortMissingLast="true"/>
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="tags" type="string" indexed="true" stored="true"/>
<field name="txt_content" type="text_ik" indexed="true" stored="true"/>
<field name="keywords" type="text_ik" indexed="true" stored ="false" multiValued="true"/>
<copyField source="title" dest="keywords"/>
<copyField source="txt_content" dest="keywords"/>
<defaultSearchField>keywords</defaultSearchField>
<uniqueKey>id</uniqueKey> <!--高亮显示的时候map取值用-->
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
<solrQueryParser defaultOperator="AND|OR"/>
</schema>
3 在WEB-INFclasses中配置三个文件如下图所示:
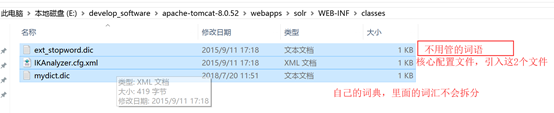
通过上面的配置便可以访问自己的solr项目了 访问地址http://localhost:8080/solr (solr为自己的项目名) 接下来通过java代码实现创建索引 和索引搜索
创建索引
/*添加索引*/
@Override
public void itemSolrAdd(String baseURL) throws Exception {
List<Item> list=itemMapper.selectByExample(null);
SolrServer server=new HttpSolrServer(baseURL);
for(Item item:list){
SolrInputDocument document=new SolrInputDocument();
document.addField("id", item.getId());
document.addField("title", item.getTitle());
document.addField("sell_point", item.getSellPoint());
document.addField("image", item.getImage());
server.add(document);
}
server.commit();
}
搜索索引
@Override
public List<Item> itemSolrShow(String name,String baseURl) {
SolrServer server = new HttpSolrServer(baseURl);
// 创建一个查询对象
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery(name);
// 从那条开始获取 默认重0 开始?
/*query.setStart((page - 1) * rows);
query.setRows(rows);*/
// 必须先设置高亮显示
query.setHighlight(true);
query.addHighlightField("title");
query.addHighlightField("sell_point");
// query.addHighlightField("sell_point");
query.setHighlightSimplePre("<em style="color:red">");
query.setHighlightSimplePost("</em>");
List<Item> items = null;
try {
QueryResponse response=server.query(query);
SolrDocumentList solrDocumentList=response.getResults();
// 取高亮显示
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
System.out.println(highlighting);
Item item;
String title;
items = new ArrayList<>();
for (SolrDocument solrDocument : solrDocumentList) {
item = new Item();
item.setId(Long.parseLong((String) solrDocument.get("id")));
System.out.println(solrDocument.get("id"));
// 取高亮显示的结果
List<String> list = highlighting.get(solrDocument.get("id")).get("title");
List<String> list2 = highlighting.get(solrDocument.get("id")).get("sell_point");
System.out.println(list);
if(list!=null){
if (list.size() > 0) {
item.setTitle(list.get(0));
} else {
item.setTitle(solrDocument.get("title").toString());
}
}
if(list2!=null){
if (list.size() > 0) {
item.setSellPoint(list2.get(0));
} else {
item.setSellPoint(solrDocument.get("sell_point").toString());
}
}
//item.setSellPoint(solrDocument.get("sell_point").toString());
item.setPrice(10000L);
item.setImage(solrDocument.get("image").toString());
//item.setPrice(100l);
items.add(item);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return items;
}
删除solr索引数据,使用XML有两种写法:
1)
<delete><id>1</id></delete> <commit/>
2)
<delete><query>id:1</query></delete> <commit/>
删除所有索引,这样写就可以了:
<delete><query>*:*</query></delete> <commit/>
solr整合spring来实现查询:
配置文件:

在service中注入HttpSolrServer,就可以查询了
public SearchResult searchItem(String keyWords, int page, int rows) { SolrQuery solrQuery = new SolrQuery(); // 构造搜索条件 solrQuery.setQuery("title:" + keyWords + " AND status:1"); // 搜索关键词 // 设置分页 start=0就是从0开始,,rows=5当前返回5条记录,第二页就是变化start这个值为5就可以了。 solrQuery.setStart((Math.max(page, 1) - 1) * rows); solrQuery.setRows(rows); // 是否需要高亮 boolean isHighlighting = !StringUtils.equals("*", keyWords) && StringUtils.isNotEmpty(keyWords); if (isHighlighting) { // 设置高亮 solrQuery.setHighlight(true); // 开启高亮组件 solrQuery.addHighlightField("title");// 高亮字段 solrQuery.setHighlightSimplePre("<em>");// 标记,高亮关键字前缀 solrQuery.setHighlightSimplePost("</em>");// 后缀 } try { // 执行查询 QueryResponse queryResponse = this.httpSolrServer.query(solrQuery); List<Item> items = queryResponse.getBeans(Item.class); if (isHighlighting) { // 将高亮的标题数据写回到数据对象中 Map<String, Map<String, List<String>>> map = queryResponse.getHighlighting(); for (Map.Entry<String, Map<String, List<String>>> highlighting : map.entrySet()) { for (Item item : items) { if (!highlighting.getKey().equals(item.getId().toString())) { continue; } item.setTitle(StringUtils.join(highlighting.getValue().get("title"), "")); break; } } } return new SearchResult(queryResponse.getResults().getNumFound(), items); } catch (SolrServerException e) { e.printStackTrace(); } return null; }