一、图像分类(resnet18)
1. 简介
问题描述:使用图像分类经典模型resnet18进行蜜蜂/蚂蚁图像分类。
模型如何完成图像分类?
Resnet在2015年由《Deep Residual Learning for Image Recognition》提出, 网上有大量的文章讲解其原理和思路,简单来说,resnet巧妙地利用了shortcut连接,解决了深度网络中模型退化的问题。下面是不同层数resnet的网络结构:

下图展示了18层resnet与50层resnet结构对比:

推理基本步骤:
-
获取数据与模型
-
数据变换,如RGB → 4D-Tensor
-
前向传播
-
输出保存预测结果
Inference阶段注意事项:
-
确保 model处于eval状态而非training
-
设置torch.no_grad(),减少内存消耗
-
数据预处理需保持一致,RGB o rBGR?
输入:任意大小图片(含有蜜蜂或蚂蚁)
输出:分类图像+描述(包括输入尺寸,时间)
样例描述:ant1-ant5均为蚂蚁图像,bee1-bee5为蜜蜂图像。其中ant5被错分为蜜蜂,可能因为背景是花,同样bee5也被错分,由此可见,我们使用resnet18训练出来的模型的分类有点依赖背景而非主体。
2. 样例
ant1


input shape:(800, 534)
time:0.033s
ant2

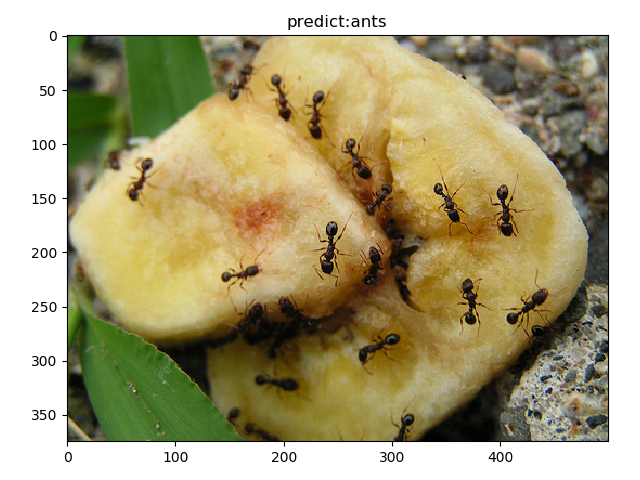
input shape:(500, 375)
time:0.032s
ant3

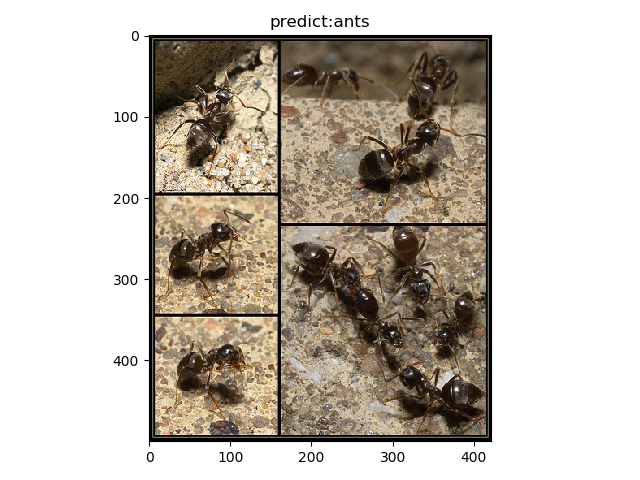
input shape:(422, 500)
time:0.038s
ant4

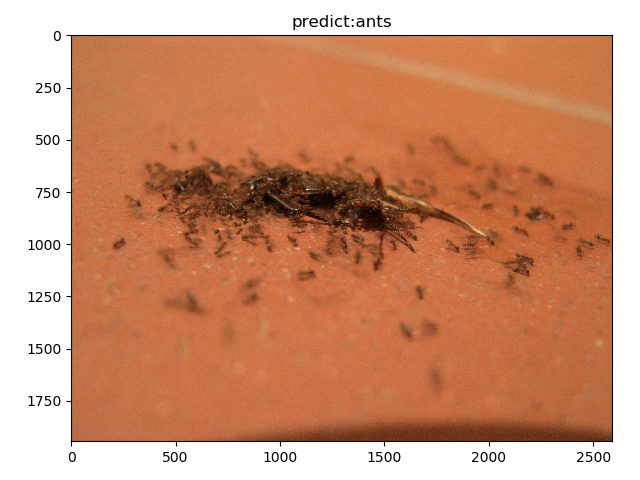
input shape:(2592, 1944)
time:0.050s
ant5


input shape:(500, 375)
time:0.032s
bee1


input shape:(500, 477)
time:0.029s
bee2


input shape:(399, 300)
time:0.063s
bee3

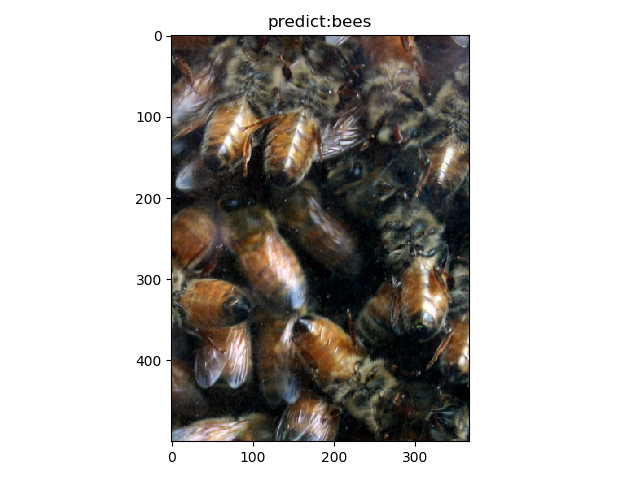
input shape:(366, 500)
time:0.036s
bee4

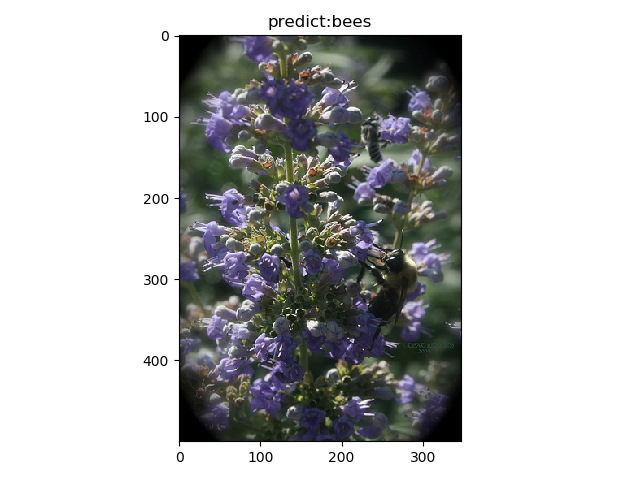
input shape:(348, 500)
time:0.034s
bee5


input shape:(500, 375)
time:0.036s
二、人脸图像生成(dcgan)
1. 简介
问题描述:通过已有的人脸数据库,学习数据的分布,并生成大量相同分布的人脸图像。我们希望生成的图像尽可能的真实
《Generative Adversarial Networks》,简写GAN,即生成对抗网络在2014年提出,是一种可以生成特定分布数据的模型。GAN训练模式与传统模式最大的差异在于原本的损失函数被替换为判别器(D network),而原本的模型被替换为了生成器(G network)。我们的判别器充当损失函数的角色督促生成器产生尽量令人满意的结果,由于判别器最初也是一个网络,也需要被训练,因此采用了交替训练的方式。

GCGAN网络结构:生成器(由100维随机向量生成64*64*3图片)如图所,判别器则相反(由图片卷积到单一输出,表示real/fake),详见DCGAN结构解读,及本任务数据项目
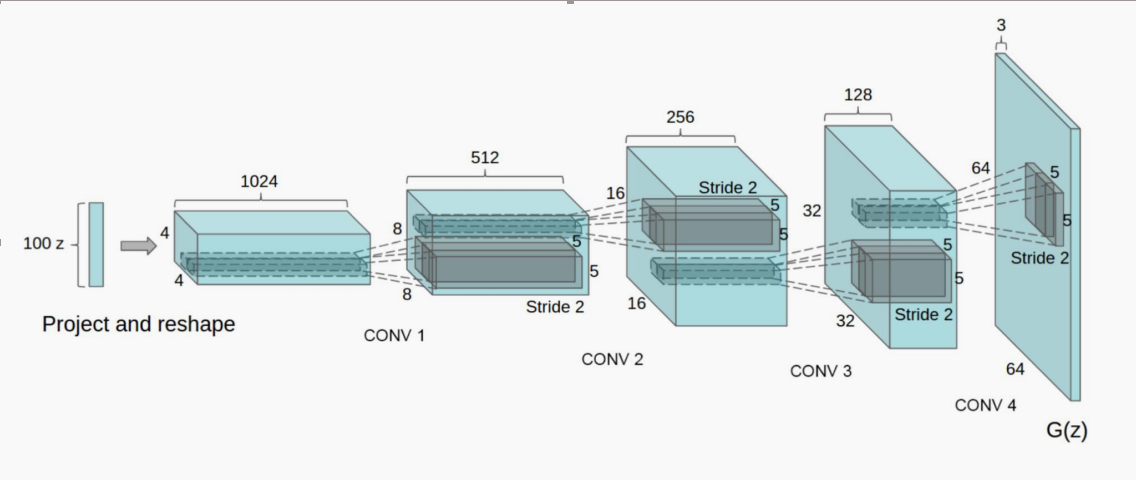
输入:
- num_img = 16 # 生成图片数量
- nrow = 4 # 每行展示数量
- noise_continue = False # 随机噪声是否连续:当取True时,在两个随机向量中产生等间距分布的num_img-2个向量,生成连续变化的照片,可以清晰地看出一个人脸转换为令一个的过程。
输出:通过网格图生成num_img个图像,每张图大小均为64*64 + 运行时间
2. 生成样例:
样例1
num_img = 16
nrow = 4
noise_continue = False
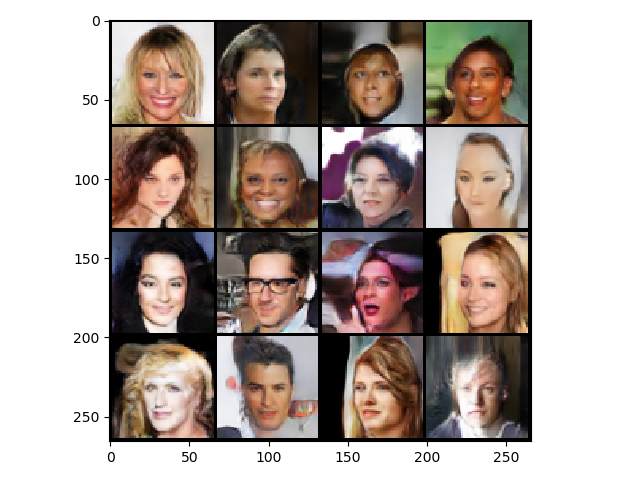
time: 0.430
样例2
num_img = 16
nrow = 4
noise_continue = True

time: 0.388
样例3
num_img = 64
nrow = 8
noise_continue = False

time: 0.430
样例4
num_img = 64
nrow = 8
noise_continue = True
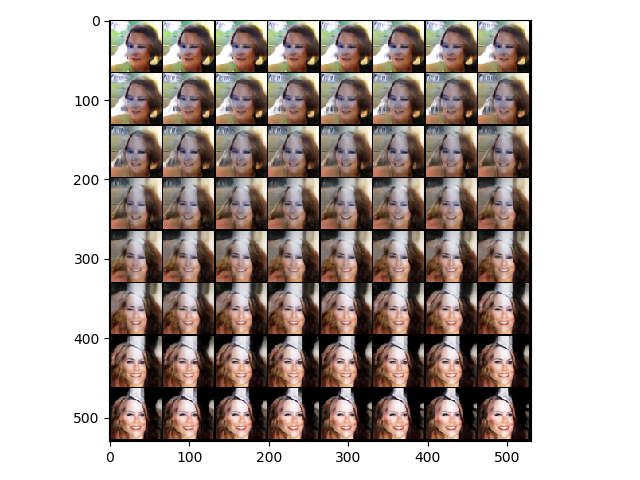
time: 0.430
三、目标检测(faster_rcnn)
1. 简介
问题描述:物体识别和物体定位的综合,不仅仅要识别出物体属于哪个分类,更重要的是得到物体在图片中的具体位置
目标检测两要素
- 分类:分类向量[p0, …, pn]
- 回归:回归边界框[x1, y1, x2, y2]
现阶段实现目标检测的算法一般分为one-stage与two-stage两种,multi-stage已被淘汰。one-stage直接通过主干网络给出类别和位置信息,没有使用RPN网路;而two-stage第一步是训练RPN网络,第二步是训练目标区域检测的网络,网络的准确度高、速度相对One-stage慢。

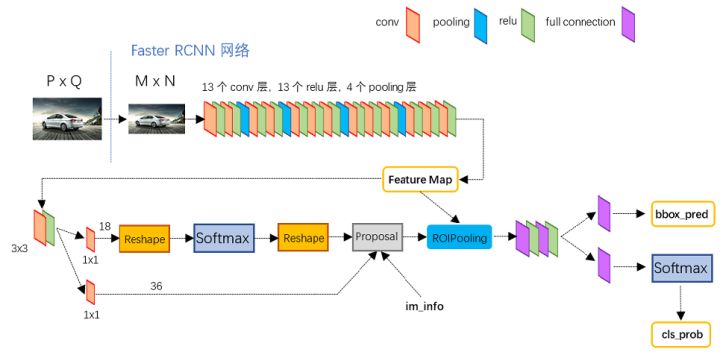
网络结构:Faster RCNN在2015年被提出,相比于之前的two-stage算法,在速度上有较大的提升,成为了目标探测领域主流的算法。RCNN全称Regions with CNN features,从名字也可以看出,RCNN的检测算法是先找出一些可能是物体的区域(即RPN层,如图Proposal生成过程),再把该区域的尺寸归一化成卷积网络输入的尺寸(即ROI Pooling层),最后判断该区域到底是不是物体,是哪个物体,以及对是物体的区域进行进一步回归的微微调整学习,使得框的更加准确。
目标检测推荐github: https://github.com/amusi/awesome-object-detection
输入:任意大小图片
输出:探测图 + 描述(输入大小,时间,标签及得分)
2. 样例
样例1


input img tensor shape:torch.Size([3, 624, 1270])
time: 3.468s
labels: ['person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'handbag', 'person', 'person', 'person', 'person', 'person', 'handbag', 'backpack', 'person', 'person', 'person', 'backpack', 'backpack', 'handbag', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'handbag', 'person', 'person', 'handbag', 'person', 'person', 'person', 'person', 'person', 'handbag', 'person', 'handbag', 'person', 'person', 'person', 'person', 'person', 'handbag', 'person', 'person', 'person', 'backpack', 'person', 'person', 'handbag', 'person', 'person', 'person', 'person', 'backpack', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'handbag', 'person', 'person', 'person', 'person', 'handbag', 'person']
scores: [0.9861, 0.985, 0.978, 0.9777, 0.977, 0.9735, 0.9488, 0.9457, 0.9451, 0.9073, 0.8724, 0.8721, 0.8539, 0.8525, 0.8394, 0.8078, 0.7983, 0.7772, 0.7599, 0.7478, 0.7289, 0.7089, 0.6798, 0.6635, 0.6635, 0.6547, 0.6513, 0.6507, 0.6486, 0.638, 0.6087, 0.6002, 0.5873, 0.5866, 0.5681, 0.5653, 0.5568, 0.5563, 0.5497, 0.5367, 0.527, 0.5192, 0.5159, 0.4952, 0.4536, 0.4505, 0.4493, 0.4458, 0.4407, 0.4389, 0.4288, 0.4184, 0.4058, 0.3983, 0.3913, 0.3878, 0.3873, 0.3766, 0.3633, 0.3479, 0.347, 0.345, 0.3419, 0.3407, 0.3377, 0.3356, 0.3273, 0.3202, 0.3139, 0.3098, 0.2969, 0.2954, 0.2953, 0.2906, 0.281, 0.2802, 0.28, 0.2781, 0.2758, 0.2721, 0.2699, 0.2681, 0.2658, 0.2643, 0.2599, 0.2526, 0.2497, 0.2455, 0.237, 0.236, 0.2311, 0.2309, 0.2292, 0.2239, 0.221, 0.2201, 0.2136, 0.211, 0.2063, 0.1997]
样例2


input img tensor shape:torch.Size([3, 433, 649])
time: 3.446s
labels: ['person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'frisbee', 'backpack', 'person', 'frisbee', 'handbag', 'person', 'person', 'person', 'person', 'person', 'person', 'person', 'backpack', 'person', 'backpack', 'baseball glove', 'person', 'handbag', 'cell phone', 'person', 'baseball glove', 'handbag', 'person', 'skateboard', 'person', 'handbag', 'person', 'bench', 'tie', 'person', 'person', 'person', 'baseball glove', 'baseball glove', 'person', 'person', 'person', 'person', 'car', 'person', 'baseball glove', 'person', 'baseball glove']
scores: [0.9989, 0.9984, 0.998, 0.998, 0.9958, 0.9945, 0.9927, 0.987, 0.9841, 0.977, 0.9709, 0.9694, 0.9575, 0.95, 0.9377, 0.916, 0.9138, 0.8392, 0.7031, 0.6829, 0.6816, 0.4896, 0.4661, 0.4086, 0.3937, 0.3934, 0.3471, 0.2957, 0.2796, 0.2519, 0.2344, 0.2308, 0.1834, 0.1582, 0.1572, 0.1476, 0.1428, 0.1385, 0.1196, 0.118, 0.1108, 0.1054, 0.1012, 0.0976, 0.0959, 0.0937, 0.0873, 0.0868, 0.0854, 0.0828, 0.0781, 0.0731, 0.0726, 0.0721, 0.0701, 0.0691, 0.0663, 0.0632, 0.0616, 0.0612, 0.0592, 0.0589, 0.057, 0.0559, 0.0552, 0.0551, 0.0531, 0.0516, 0.0511]
样例3

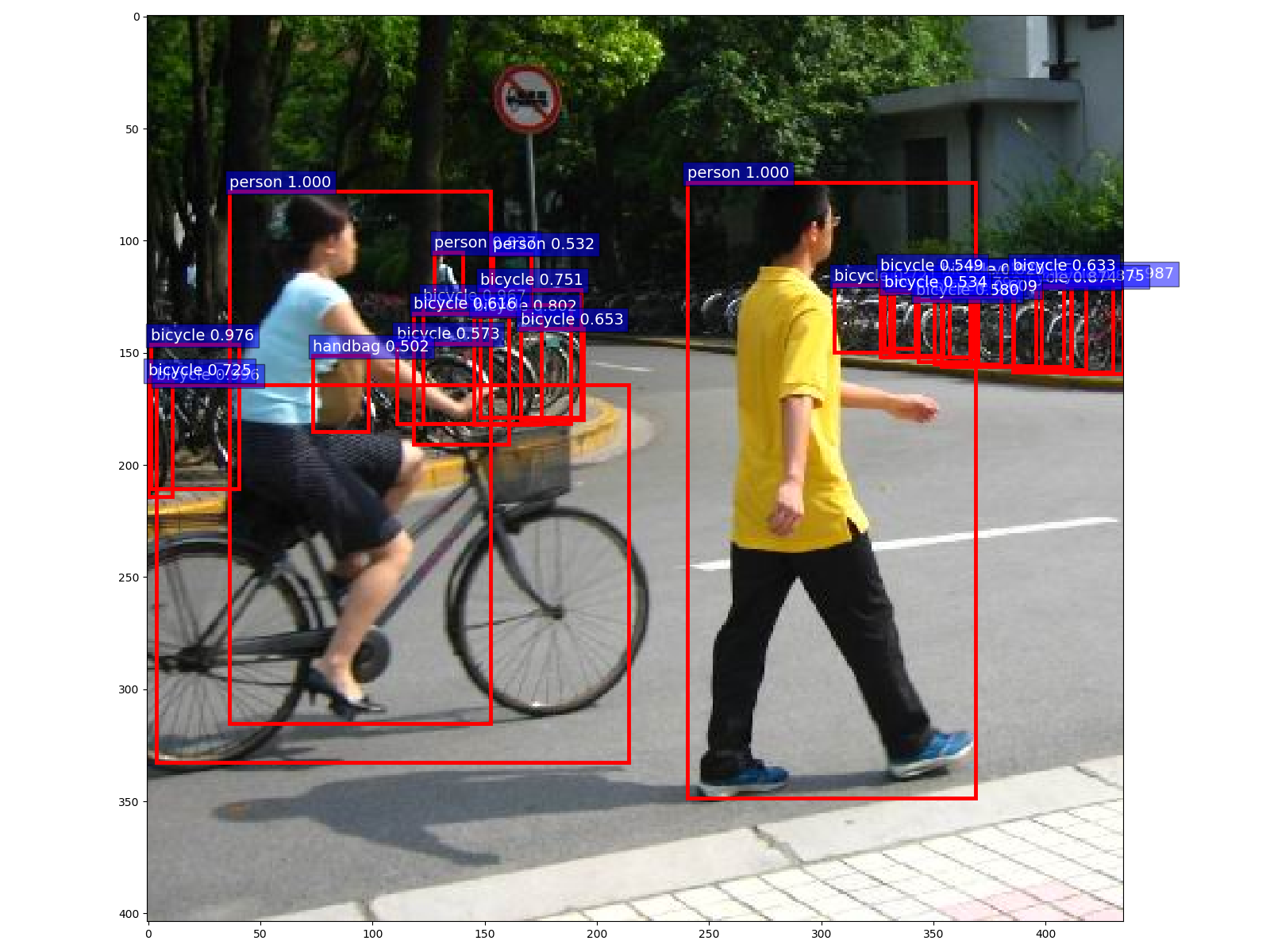
input img tensor shape:torch.Size([3, 404, 435])
time: 2.437s
labels: ['person', 'person', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'person', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'person', 'handbag', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'person', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'motorcycle', 'bicycle', 'bicycle', 'backpack', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'car', 'person', 'bicycle', 'skateboard', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'stop sign', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle', 'bicycle']
scores: [0.9997, 0.9995, 0.9962, 0.9865, 0.976, 0.9674, 0.9191, 0.8953, 0.8745, 0.8735, 0.8365, 0.8203, 0.8016, 0.7921, 0.7511, 0.7246, 0.7214, 0.6532, 0.6327, 0.616, 0.6086, 0.5796, 0.5732, 0.5494, 0.534, 0.532, 0.5016, 0.4768, 0.451, 0.4438, 0.4215, 0.3844, 0.3572, 0.3446, 0.3433, 0.3162, 0.3137, 0.2468, 0.241, 0.2177, 0.1947, 0.1934, 0.1751, 0.1486, 0.1417, 0.1263, 0.1187, 0.1187, 0.1149, 0.1145, 0.1071, 0.1051, 0.0987, 0.0983, 0.0895, 0.0845, 0.0837, 0.081, 0.0783, 0.0767, 0.0707, 0.0703, 0.0697, 0.0605, 0.0574, 0.0573, 0.0536]
样例4


input img tensor shape:torch.Size([3, 438, 567])
time: 3.521s
labels: ['person', 'person', 'person', 'person', 'person', 'bicycle', 'backpack', 'person', 'bicycle', 'backpack', 'person', 'person', 'person', 'person', 'backpack', 'backpack', 'bicycle', 'handbag', 'person', 'person', 'bicycle', 'person', 'person', 'person', 'handbag', 'bicycle', 'person', 'tennis racket', 'backpack', 'backpack', 'person', 'bicycle', 'person', 'handbag', 'handbag', 'person', 'potted plant', 'handbag', 'person', 'handbag', 'person', 'person', 'person', 'person', 'chair', 'bicycle', 'person', 'person', 'person', 'bicycle', 'person', 'potted plant', 'person', 'backpack', 'person', 'motorcycle', 'person', 'handbag', 'bicycle', 'handbag', 'person', 'backpack', 'handbag', 'bicycle', 'backpack', 'tie', 'backpack', 'person', 'bicycle', 'person', 'backpack', 'bicycle', 'person', 'motorcycle']
scores: [0.9992, 0.9977, 0.9966, 0.9948, 0.9912, 0.9906, 0.9861, 0.9855, 0.9731, 0.9693, 0.9678, 0.9662, 0.959, 0.9394, 0.936, 0.8802, 0.8656, 0.8219, 0.819, 0.7878, 0.7354, 0.6874, 0.6777, 0.6356, 0.4796, 0.4632, 0.4269, 0.4146, 0.326, 0.2994, 0.2711, 0.2325, 0.2219, 0.2054, 0.1846, 0.184, 0.1698, 0.1687, 0.1613, 0.1577, 0.1575, 0.1533, 0.1526, 0.1486, 0.1432, 0.1426, 0.1304, 0.1222, 0.1209, 0.1139, 0.1126, 0.1122, 0.1026, 0.0974, 0.097, 0.091, 0.0883, 0.0853, 0.0791, 0.0781, 0.0754, 0.0664, 0.0656, 0.0647, 0.0631, 0.0625, 0.0602, 0.0578, 0.0562, 0.053, 0.0513, 0.051, 0.0505, 0.0504]
样例5
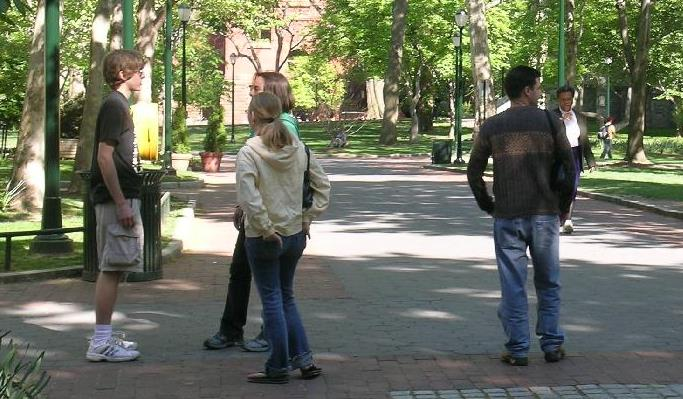
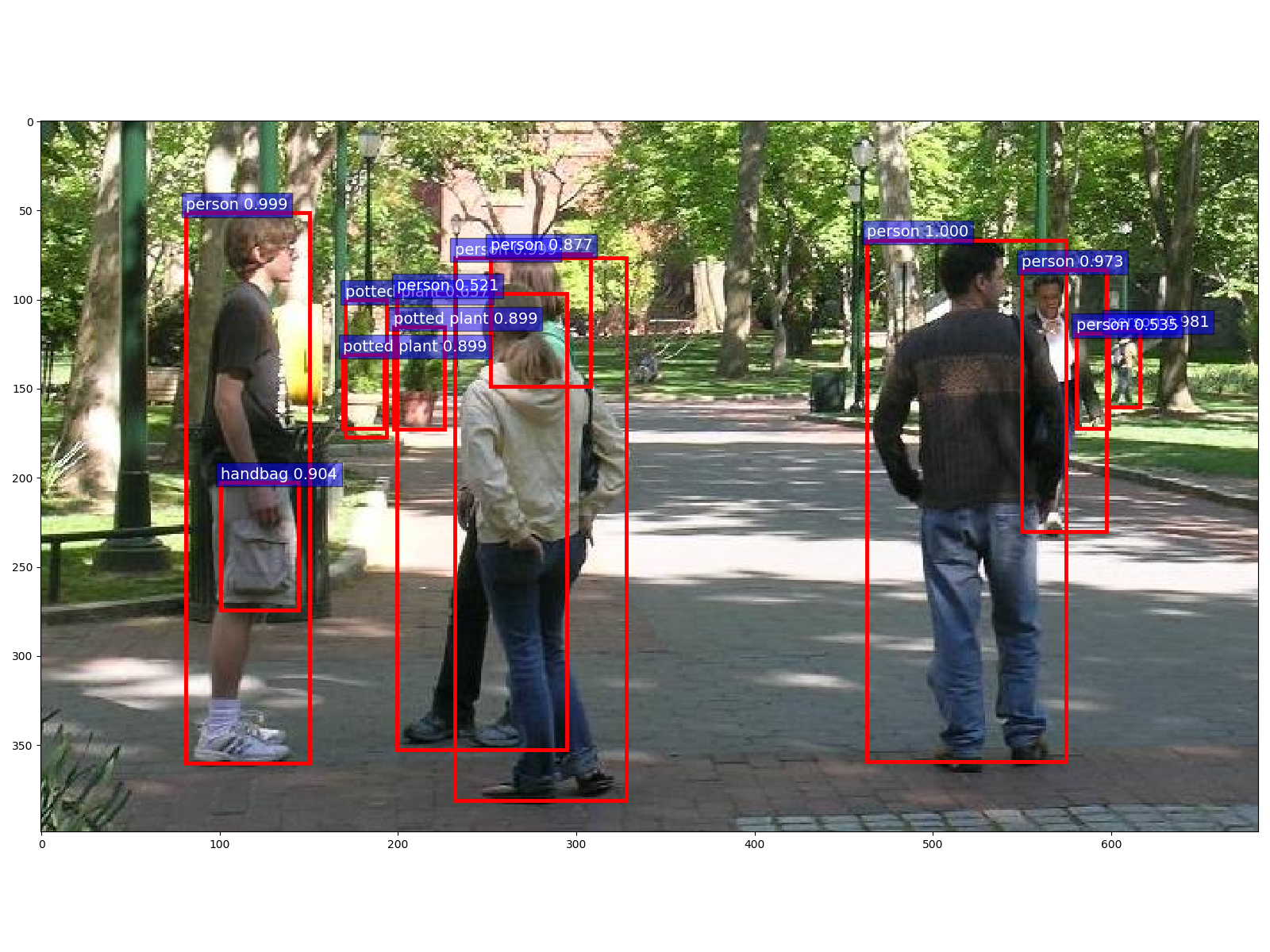
input img tensor shape:torch.Size([3, 399, 683])
time: 4.199s
labels: ['person', 'person', 'person', 'person', 'person', 'handbag', 'potted plant', 'potted plant', 'person', 'potted plant', 'person', 'person', 'handbag', 'backpack', 'person', 'handbag', 'person', 'handbag', 'handbag', 'person', 'person', 'potted plant', 'handbag', 'backpack', 'person', 'backpack', 'potted plant', 'person', 'person', 'person', 'tie', 'person', 'handbag', 'backpack', 'potted plant', 'handbag', 'handbag', 'potted plant', 'person', 'potted plant', 'backpack', 'bicycle', 'handbag', 'potted plant', 'chair', 'potted plant', 'potted plant', 'potted plant', 'potted plant', 'handbag', 'backpack', 'tie', 'person', 'backpack', 'potted plant', 'dining table', 'potted plant', 'bench', 'handbag', 'tie', 'potted plant', 'handbag', 'backpack', 'potted plant', 'backpack', 'potted plant', 'backpack', 'potted plant']
scores: [0.9997, 0.9991, 0.9985, 0.9807, 0.9731, 0.9043, 0.8989, 0.8985, 0.8772, 0.6565, 0.5354, 0.5205, 0.4876, 0.4571, 0.421, 0.4015, 0.3939, 0.3668, 0.3612, 0.3448, 0.3254, 0.3165, 0.29, 0.2851, 0.2605, 0.2525, 0.2439, 0.2414, 0.2204, 0.2136, 0.1969, 0.196, 0.1757, 0.1695, 0.1635, 0.1608, 0.1571, 0.1536, 0.15, 0.145, 0.1413, 0.1404, 0.1312, 0.1172, 0.1164, 0.1025, 0.1023, 0.0899, 0.0888, 0.0879, 0.087, 0.0822, 0.081, 0.0757, 0.0748, 0.0738, 0.0729, 0.0709, 0.0707, 0.0681, 0.0663, 0.0648, 0.0627, 0.0588, 0.0567, 0.0531, 0.0525, 0.052]
四、人像分割(unet)
1. 简介
问题描述:将人物与背景相分离,即人物区域判定为1,其他区域判为0,逐像素的二分类,属于图像分割问题
图像分割分类:图像分割一般分为以下四大任务,人像分割属于其中语义分割的一种
- 超像素分割:少量超像素代替大量像素,常用于图像预处理
- 语义分割:逐像素分类,无法区分个体
- 实例分割:对个体目标进行分割,像素级目标检测
- 全景分割:语义分割结合实例分割

网络结构:2015年提出的《U-Net: Convolutional Networks for Biomedical Image Segmentation》能非常好地应对这样问题,在原本encoder-decoder的基础上加入了跳线结构,使得收缩路径和扩张路径直接能够共享部分低级信息,因此被广泛应用,人像分割也属于一种典型的应用。
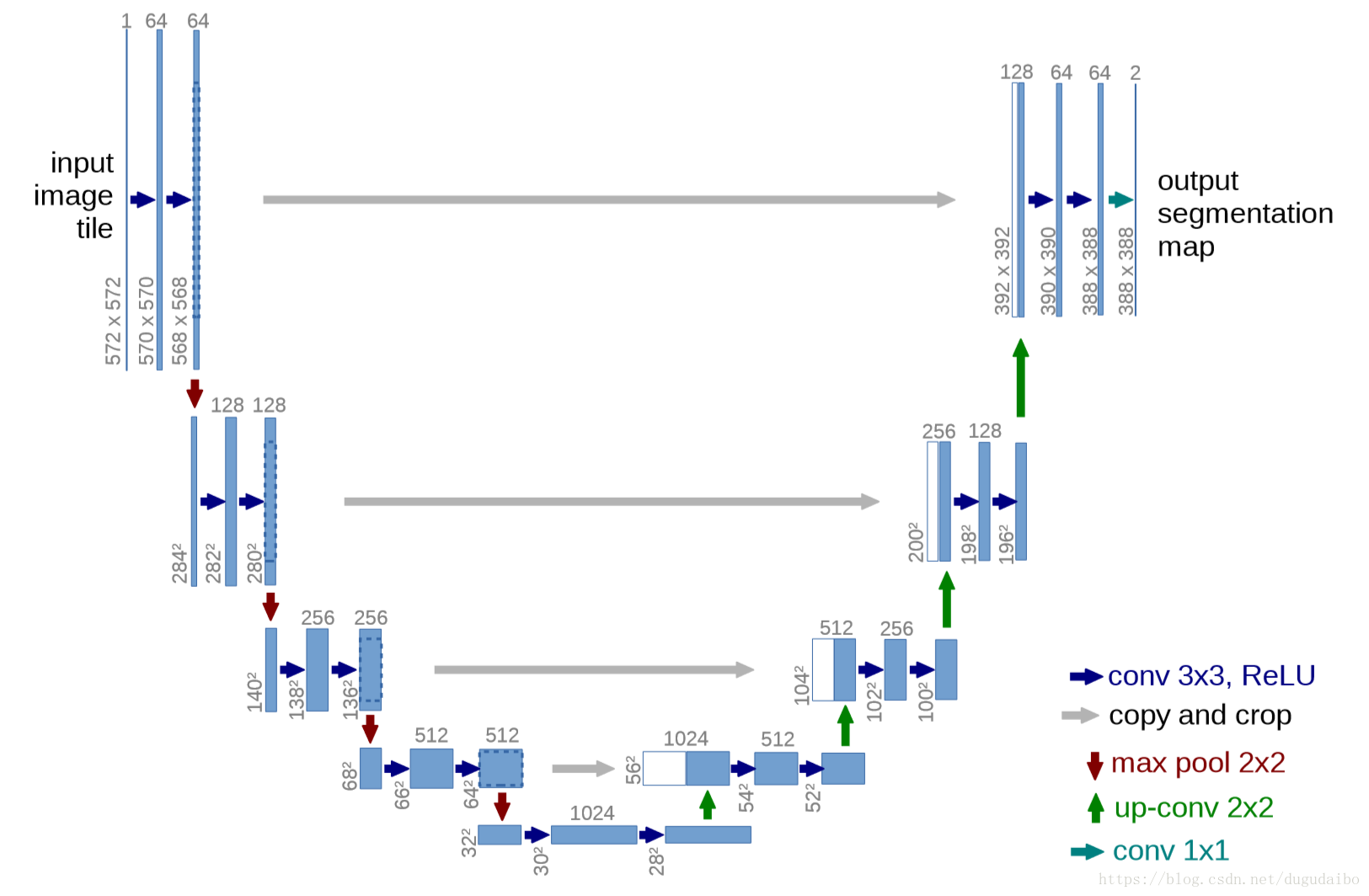
输入:任意大小图片
输出:分割图 + 时间
2. 样例
样例1

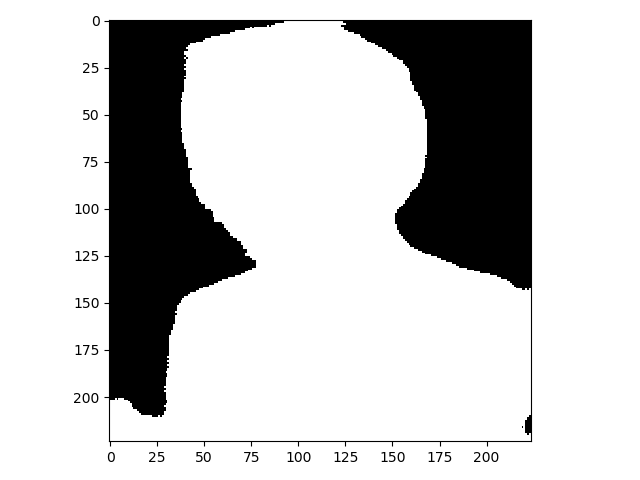
time: 0.735s
样例2

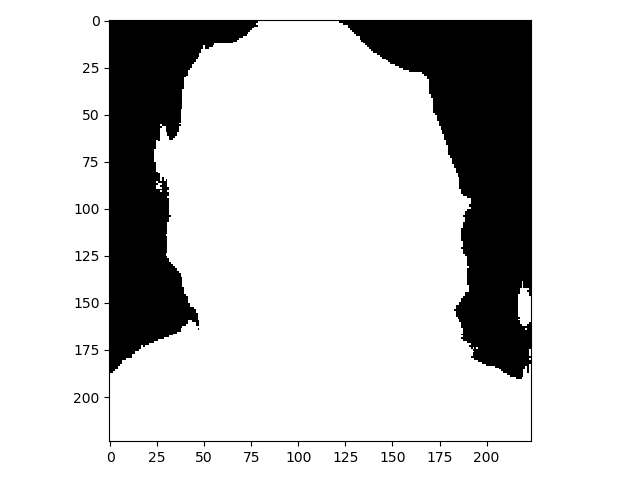
time: 0.415s
样例3

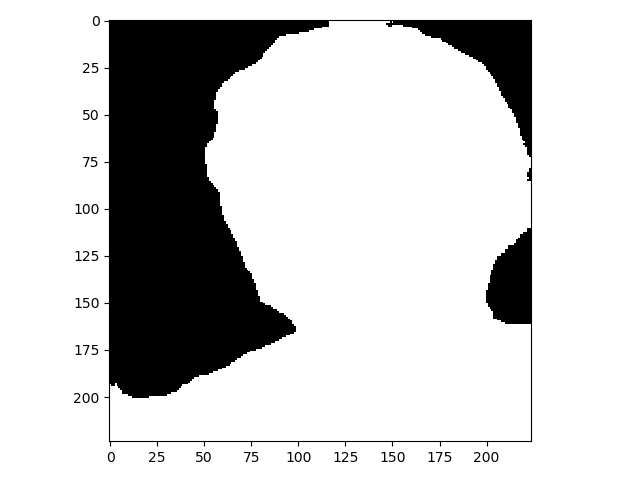
time: 0.471s
五、语义分割(resnet101)
1. 简介
问题:将图像中每个像素分类为21类('__background__', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')的一种
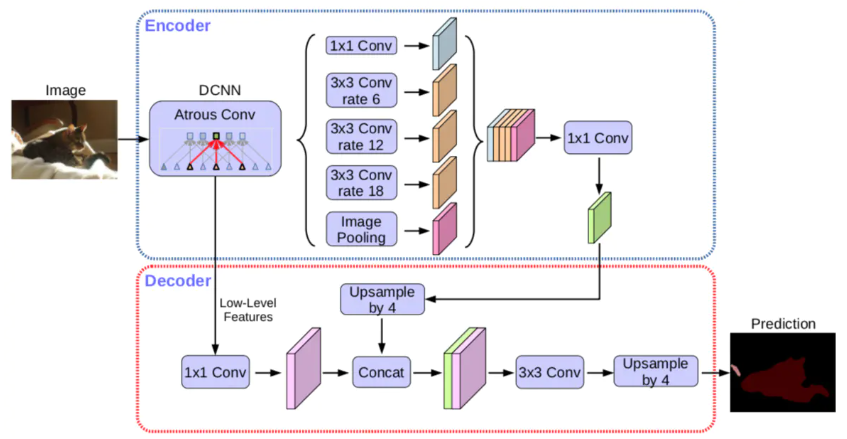
网络结构:2017年提出的《deeplabv3+》是一种非常先进的基于深度学习的图像语义分割方法,可对物体进行像素级分割,解决了语义分割方向的两个问题: 一是 feature map 的分辨率过低导致后续在恢复为原图分辨率时不够精确,二是对多尺度物体的检测表现不好。
- deeplabv1采用了1.孔洞卷积:借助孔洞卷积,增大感受野;2.CRF:采用CRF进行mask后处理
- deeplabv2采用了ASPP(Atrous spatial pyramid pooling ):解决多尺度问题
- deeplabv3采用了1. 孔洞卷积的串行; 2. ASPP的并行
- deeplabv3+加上Encoder-Decoder思想,具体结构如下:
输入:一张任意大小的图片
输出:语义分割图 + 描述(输入大小,输出大小,描述)
样例说明:对于样例3中的小狗的头“嫁接”小猫的身体,网络会把猫的身体错分为狗的一部分。由此可见网络所提取的特征更多的是头部的特征,因为身体与头部相连才被分为一块。
2. 样例
样例1

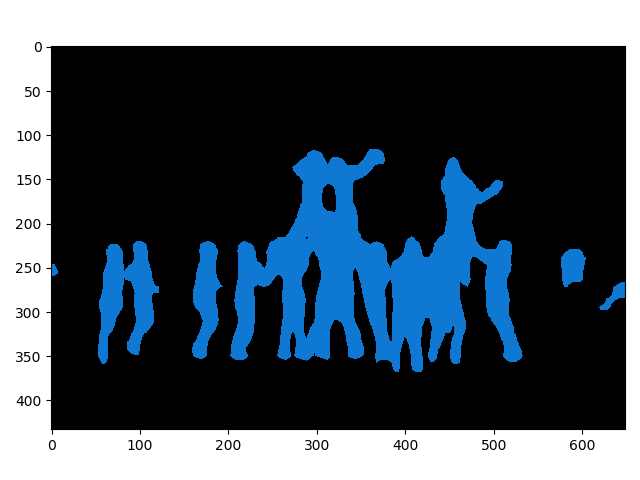
input shape: [1, 3, 433, 649]
output shape: [21, 433, 649]
time: 4.205s
样例2

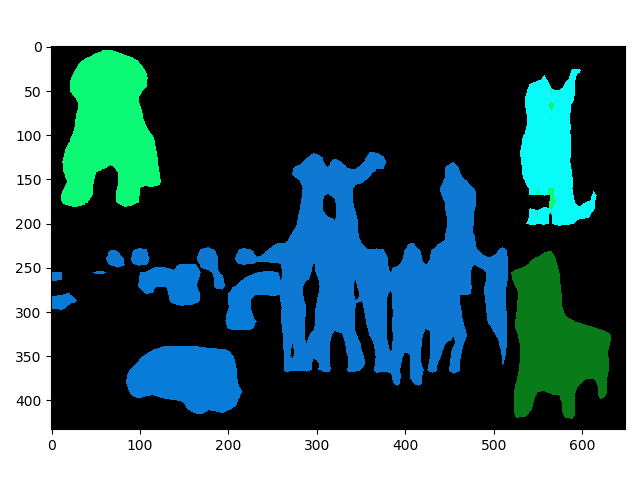
input shape: [1, 3, 433, 649]
output shape: [21, 433, 649]
time: 4.534s
样例3

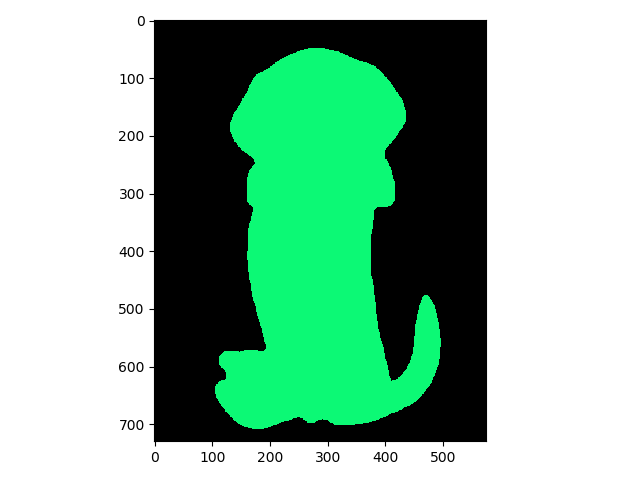
input shape: [1, 3, 730, 574]
output shape: [21, 730, 574]
time: 6.472s