Transformer原理
论文地址:Attention Is All You Need:https://arxiv.org/abs/1706.03762
Transformer是一种完全基于Attention机制来加速深度学习训练过程的算法模型。Transformer最大的优势在于其在并行化处理上做出的贡献。
Transformer抛弃了以往深度学习任务里面使用到的 CNN 和 RNN ,目前大热的Bert就是基于Transformer构建的,这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。
Transformer总体结构
和Attention模型一样,Transformer模型中也采用了 encoer-decoder 架构。但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
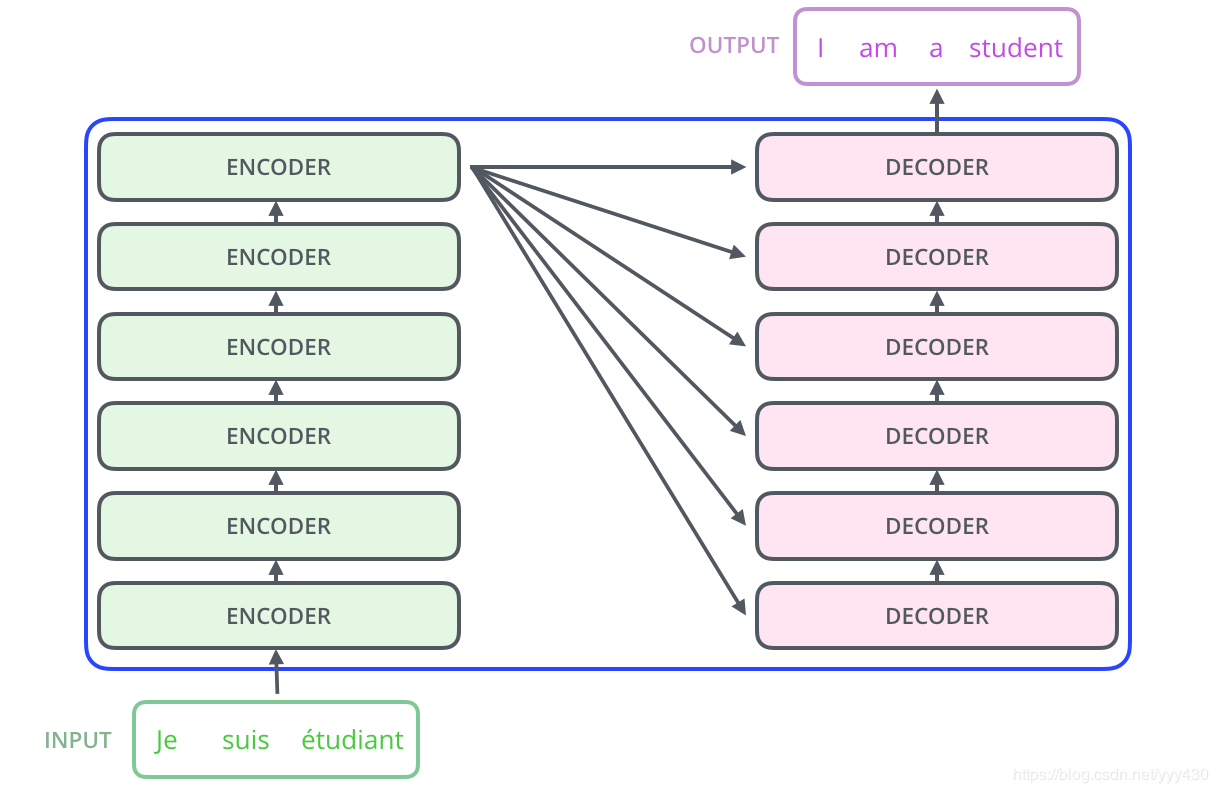
对于encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容。
现在我们知道了模型的主要组件,接下来我们看下模型的内部细节。首先,模型需要对输入的数据进行一个embedding操作,也可以理解为类似w2c的操作,embedding结束之后,输入到encoder层,self-attention处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个encoder。
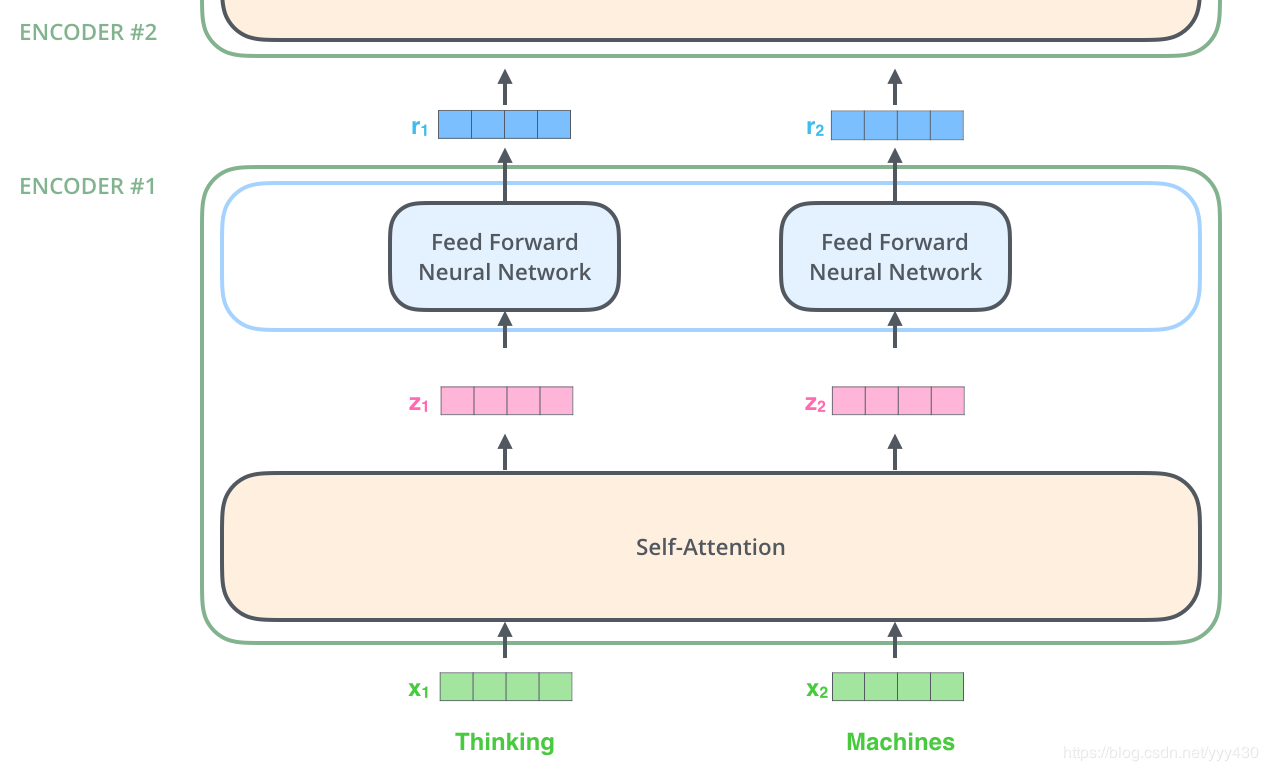
Self-Attention
接下来我们详细看一下self-attention,其思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路,我们看个例子:
The animal didn't cross the street because it was too tired
这里的it到底代表的是animal还是street呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention就能够让机器把it和animal联系起来,接下来我们看下详细的处理过程。
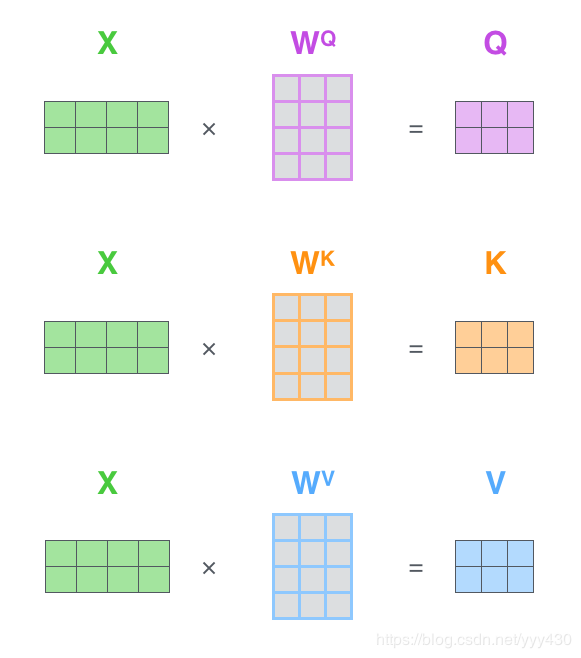
1、首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,其值在BP的过程中会一直进行更新,得到的这三个向量的维度是64低于embedding维度的。
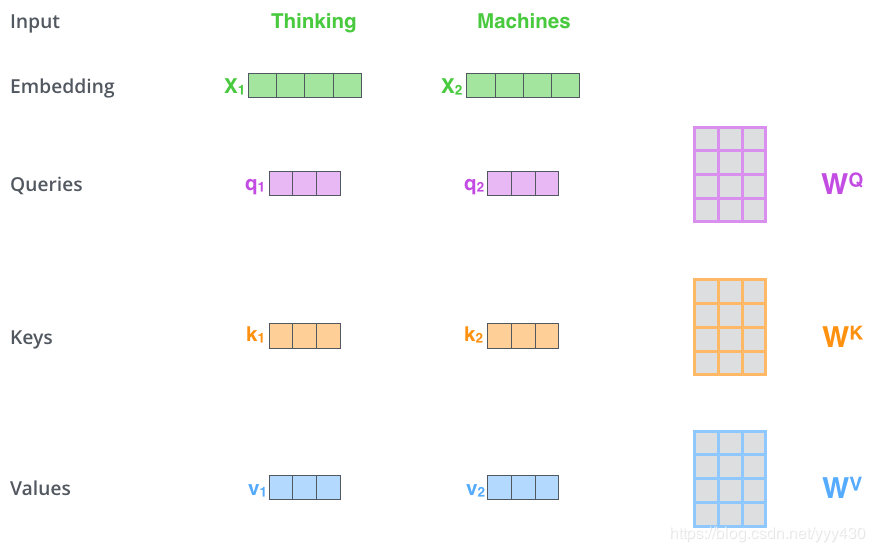
那么Query、Key、Value这三个向量又是什么呢?这三个向量对于attention来说很重要,当你理解了下文后,你将会明白这三个向量扮演者什么的角色。
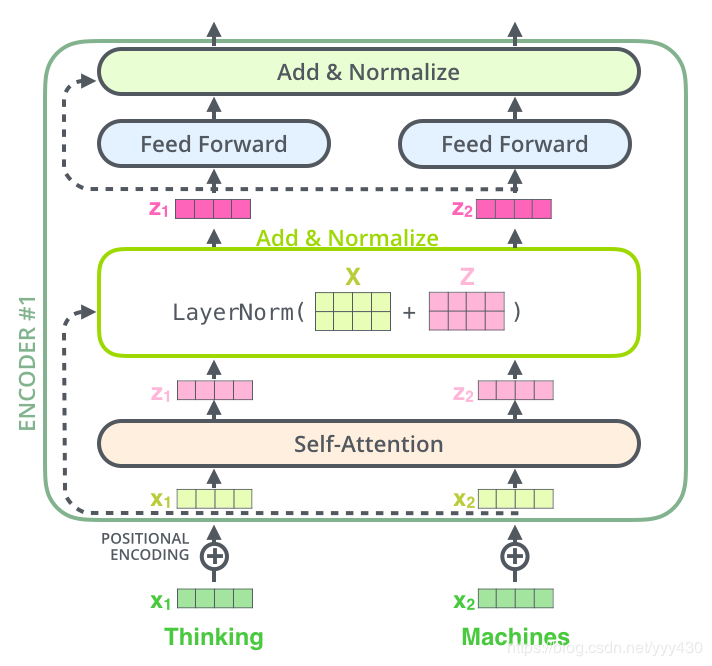
2、计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是Query与Key做点成,以下图为例,首先我们需要针对Thinking这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即q1·k1,然后是针对于第二个词即q1·k2
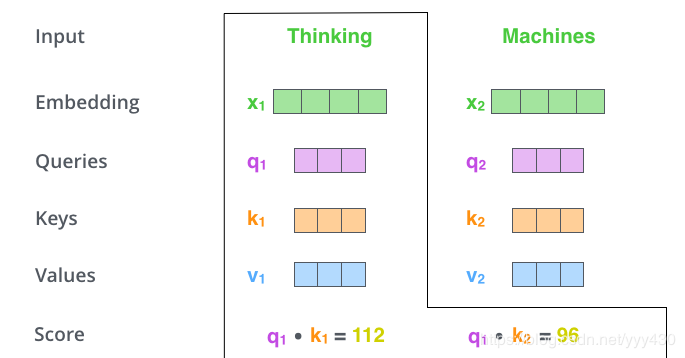
3、接下来,把点成的结果除以一个常数,这里我们除以8,这个值一般是采用上文提到的矩阵的第一个维度的开方即64的开方8,当然也可以选择其他的值,然后把得到的结果做一个softmax的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大
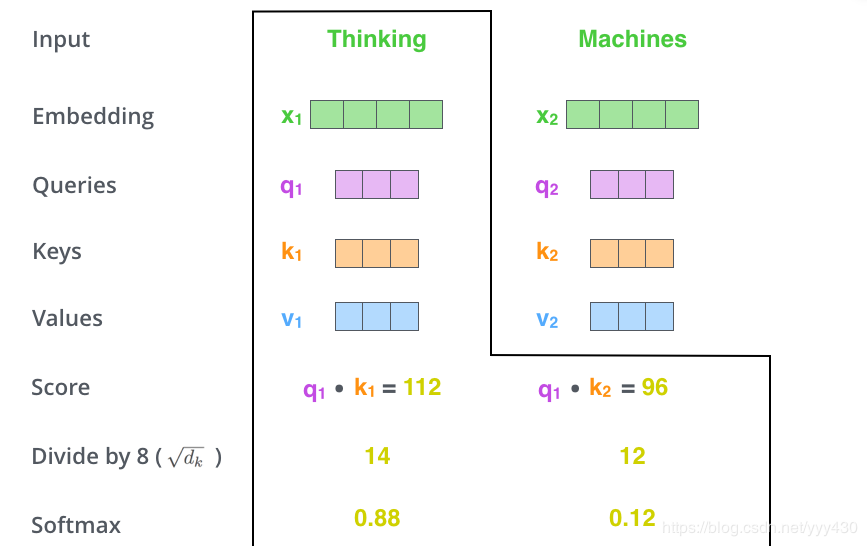
4、下一步就是把Value和softmax得到的值进行相乘,并相加,得到的结果即是self-attetion在当前节点的值。
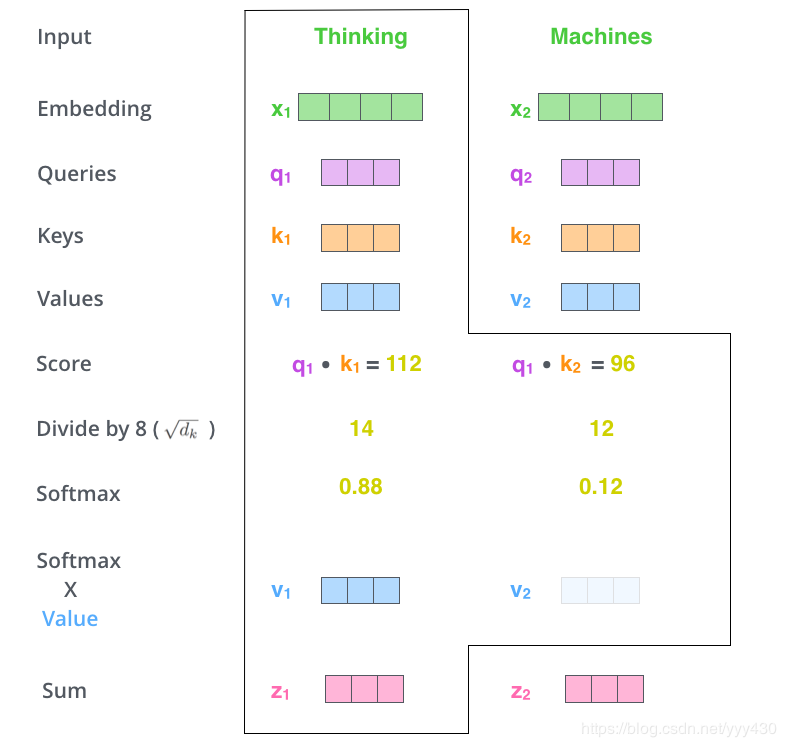
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出Query, Key, Value的矩阵,然后把embedding的值与三个矩阵直接相乘,把得到的新矩阵Q与K相乘,乘以一个常数,做softmax操作,最后乘上V矩阵:
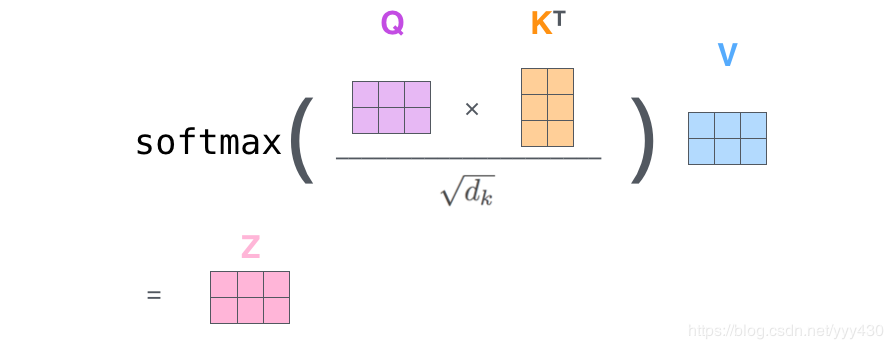
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
Multi-Headed Attention
这篇论文更牛逼的地方是给self-attention加入了另外一个机制,被称为“multi-headed” attention,该机制理解起来很简单,就是说不仅仅只初始化一组Q、K、V的矩阵,而是初始化多组,tranformer是使用了8组,所以最后得到的结果是8个矩阵。


这给我们留下了一个小的挑战,前馈神经网络没法输入8个矩阵呀,这该怎么办呢?所以我们需要一种方式,把8个矩阵降为1个,首先,我们把8个矩阵连在一起,这样会得到一个大的矩阵,再随机初始化一个矩阵和这个组合好的矩阵相乘,最后得到一个最终的矩阵。

这就是multi-headed attention的全部流程了,这里其实已经有很多矩阵了,我们把所有的矩阵放到一张图内看一下总体的流程。

Positional Encoding
到目前为止,transformer模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下:
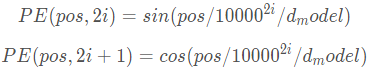
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码,这里提供一下代码。
1 position_encoding = np.array( 2 [[pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)] for pos in range(max_seq_len)]) 3 4 position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2]) 5 position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
最后把这个Positional Encoding与embedding的值相加,作为输入送到下一层。
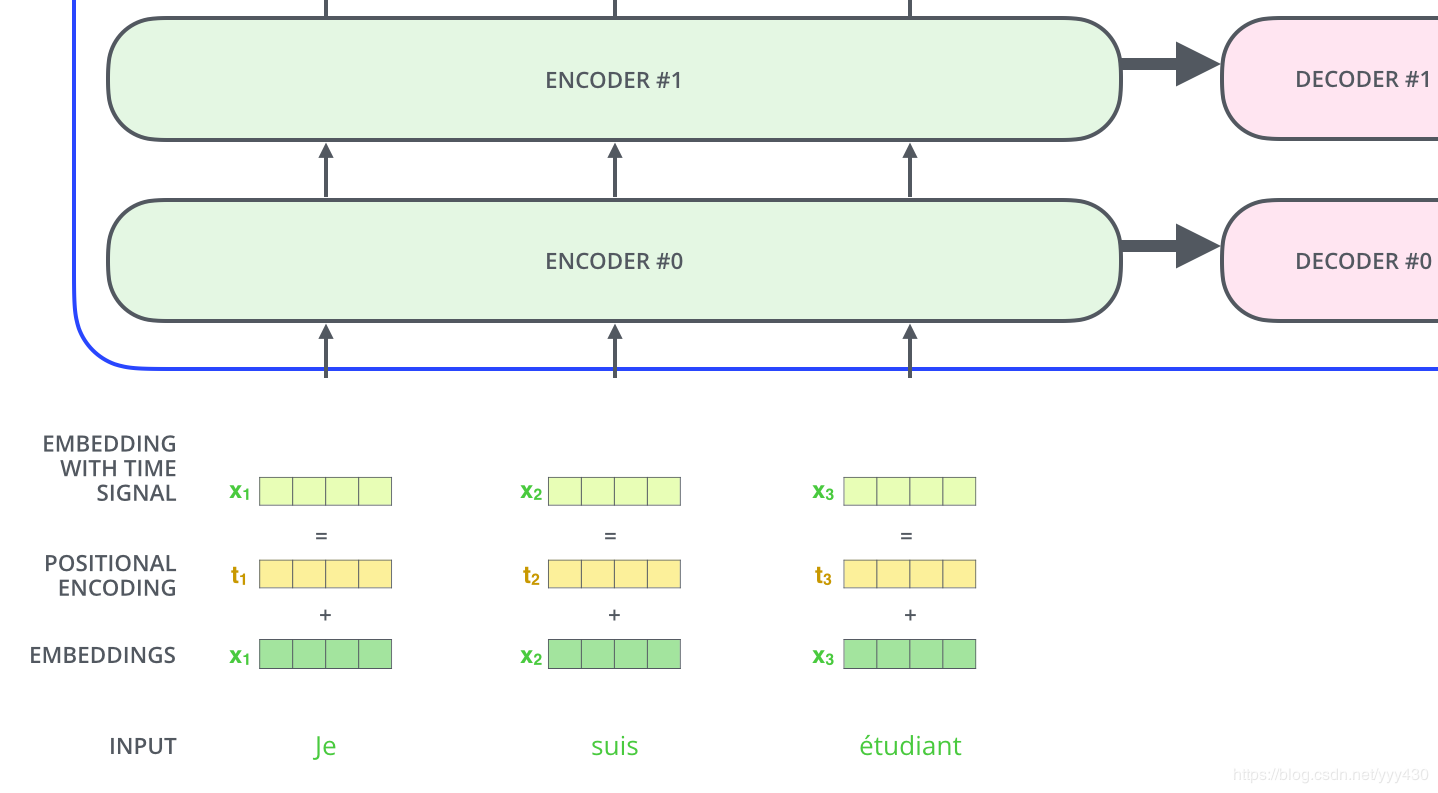
Layer normalization
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残缺模块,并且有一个Layer normalization
残缺模块相信大家都很清楚了,这里不再讲解,主要讲解下Layer normalization。Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
说到 normalization,那就肯定得提到 Batch Normalization。BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示:
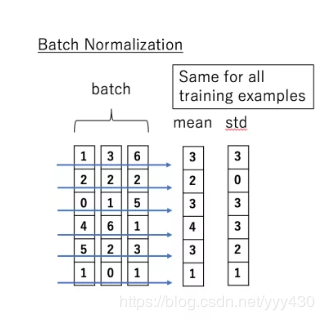
可以看到,右半边求均值是沿着数据 batch_size的方向进行的,其计算公式如下:
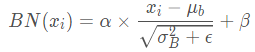
那么什么是 Layer normalization 呢?它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
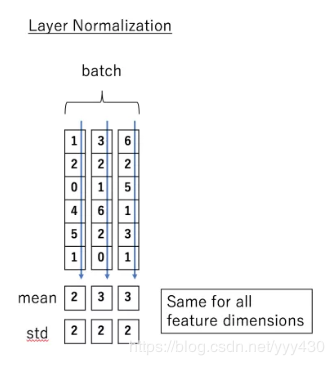
下面看一下 LN 的公式:
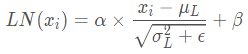
到这里为止就是全部encoders的内容了,如果把两个encoders叠加在一起就是这样的结构:
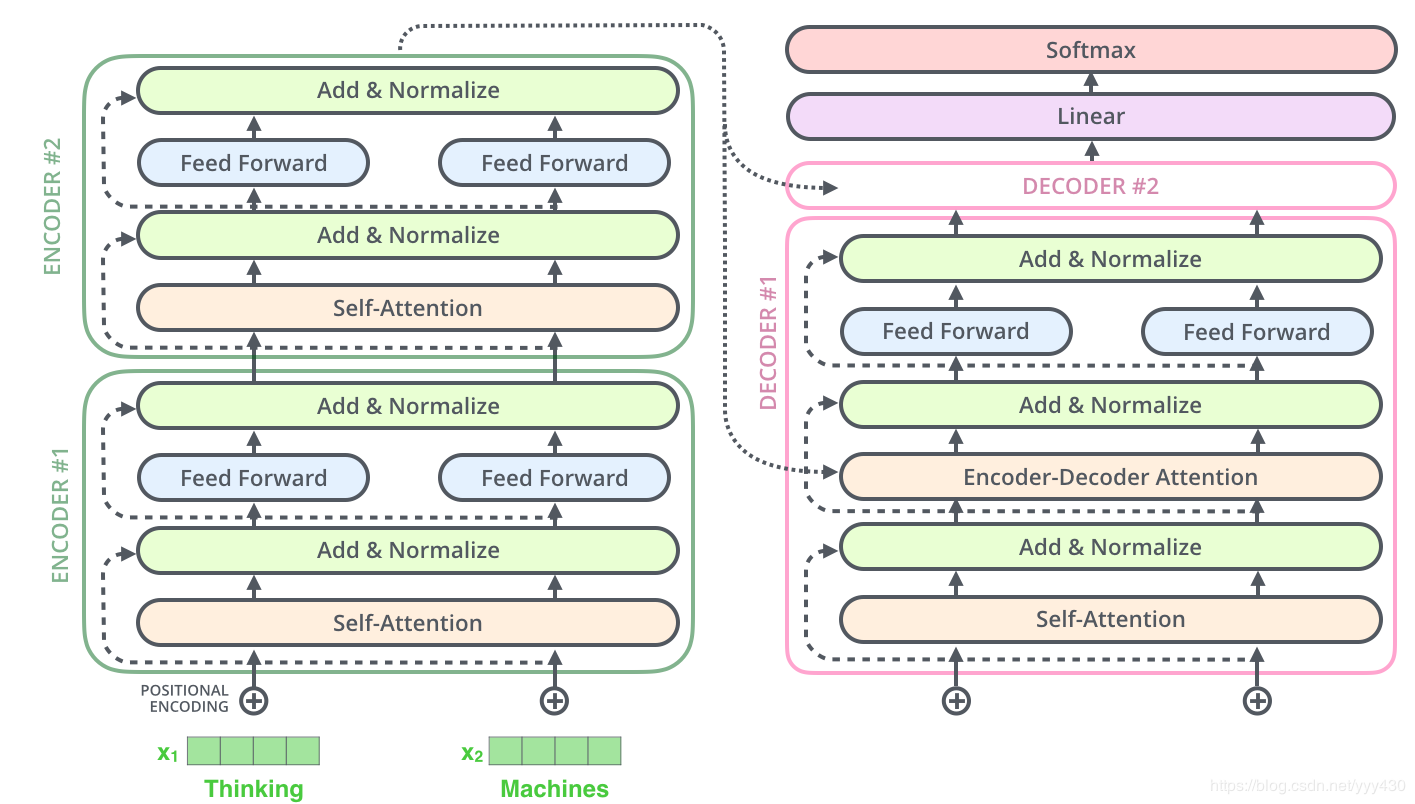
Decoder层
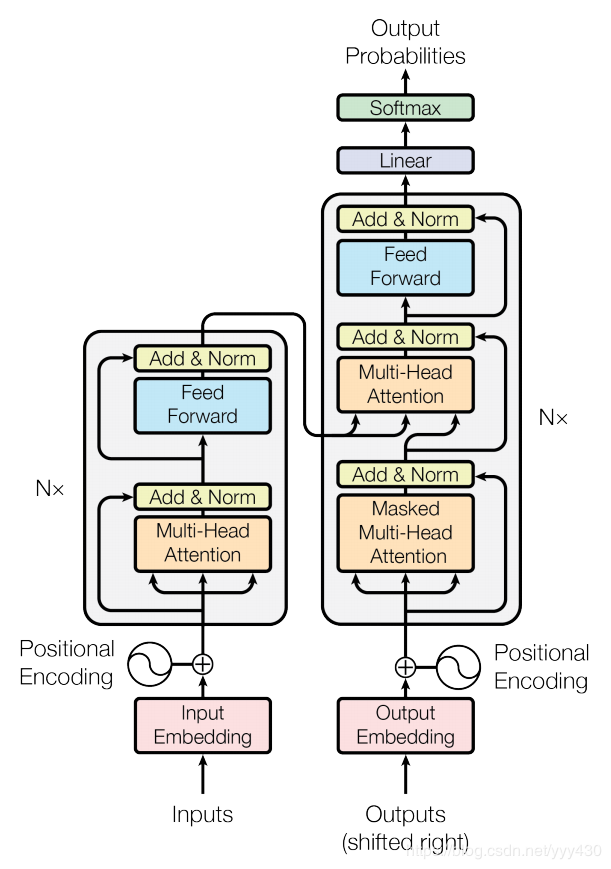
上图是transformer的一个详细结构,相比本文一开始结束的结构图会更详细些,接下来,我们会按照这个结构图讲解下decoder部分。
可以看到decoder部分其实和encoder部分大同小异,不过在最下面额外多了一个masked mutil-head attetion,这里的mask也是transformer一个很关键的技术,我们一起来看一下。
Mask
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到
Padding Mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
输出层
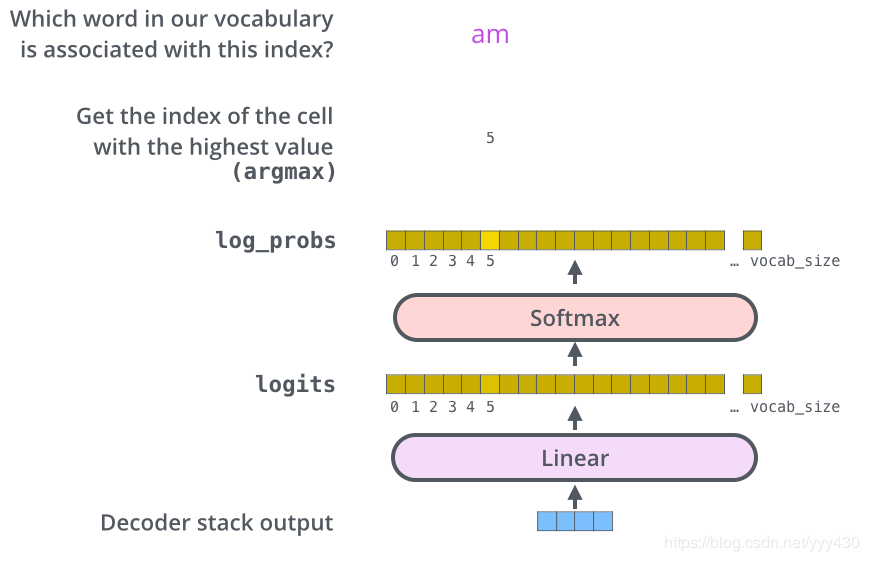
当decoder层全部执行完毕后,怎么把得到的向量映射为我们需要的词呢,很简单,只需要在结尾再添加一个全连接层和softmax层,假如我们的词典是1w个词,那最终softmax会输入1w个词的概率,概率值最大的对应的词就是我们最终的结果。
BERT的原理
BERT 的创新点在于它将双向 Transformer 用于语言模型,
之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来。
实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,
论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。
BERT 利用了 Transformer 的 encoder 部分。
Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。
Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,
这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
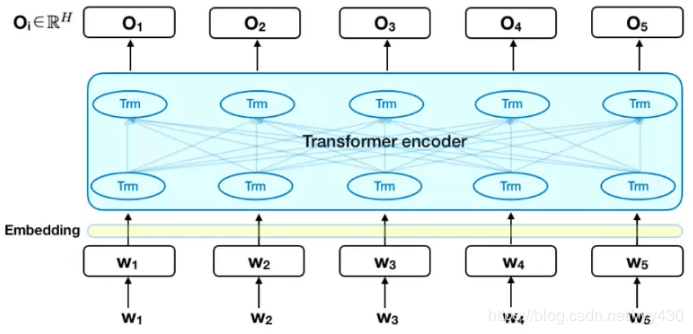
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,
“The child came home from ___”
双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
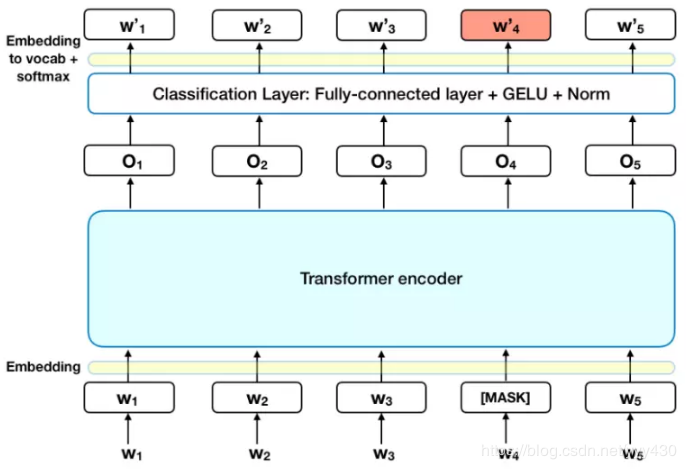
1. Masked LM (MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
在 encoder 的输出上添加一个分类层
用嵌入矩阵乘以输出向量,将其转换为词汇的维度
用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2. Next Sentence Prediction (NSP)
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
1在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
2将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
3给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
1整个输入序列输入给 Transformer 模型
2用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
3用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。

如何使用 BERT?
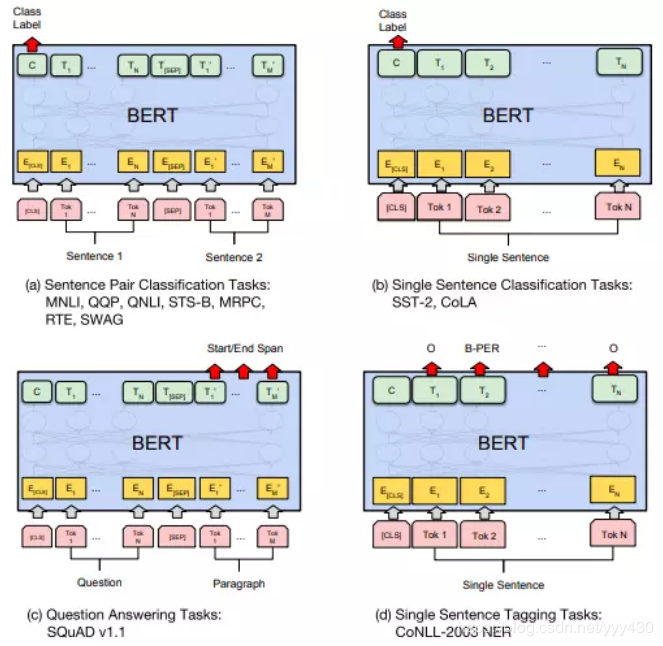
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
在 fine-tuning 中,大多数超参数可以保持与 BERT 相同,在论文中还给出了需要调整的超参数的具体指导(第3.5节)。
https://blog.csdn.net/yyy430/article/details/88682656