分布式事务
分布式环境下的事务
要了解分布式事务,首先要了解分布式环境
分布式
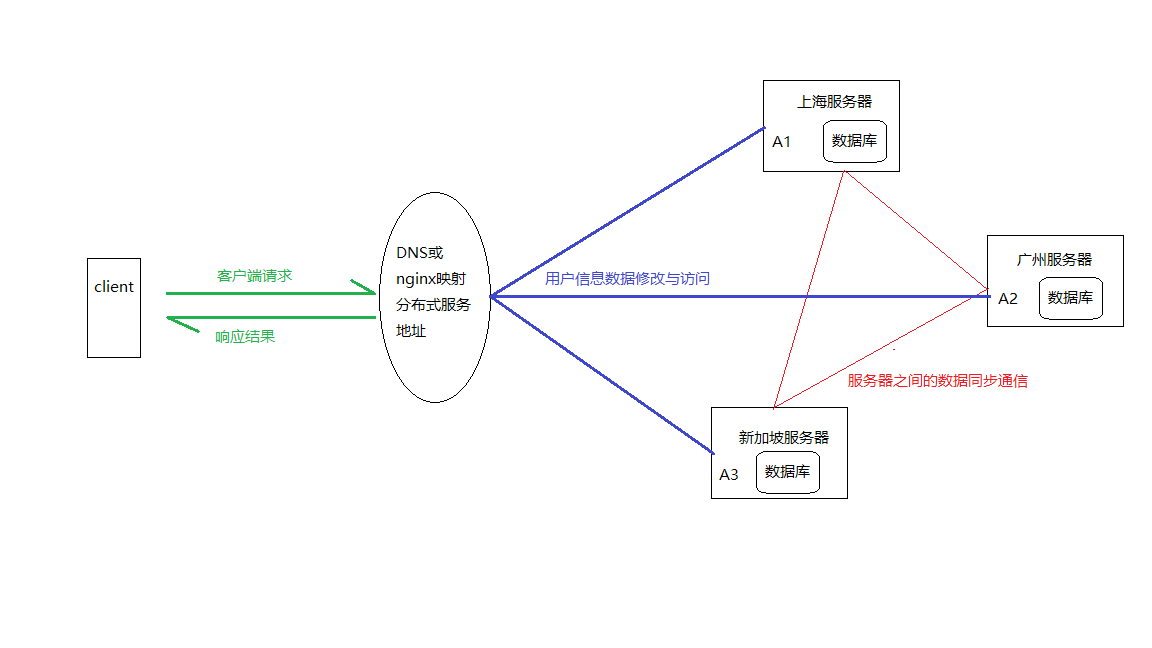
如一网站,访问一个服务A(查询自己用户信息), 提供服务A的服务器分别有A1(上海)A2(广州) A3(新加坡)
同一个服务分布在三个区域的服务器上,这就是分布式。你可以访问 上海的服务器,广州的或者新加坡的,但是
三个服务器之前通信是有延迟的,所以数据同步需要一定时间
分布式中的问题
举例一个分布式场景
如果用户Y个人信息 名字为 "南柯一梦" Y改为 "南柯梦", 同一时间,Y用户好友查看Y的名字,好友查询的结果是"南柯一梦" 还是 "南柯梦" 这是分布式系统常见的问题(数据修改发生在上海,访问发生在新加坡)。
CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
参考文章
An Illustrated Proof of the CAP Theorem
CAP 定理的含义
以为网络有延迟和不可测故障,因此分布式系统是保持服务稳定的常用手段,但是分布式因为服务机器分布在不同地点,因此也会有分布式的特点问题。
分布式中 一致性 可用性 容灾性 是三个指标
Consistency
数据一致性,分布式环境下,不同地点的服务器,数据库数据同步一致。
Availability
服务可用性,分布式环境下,调用服务,都可用
Partition tolerance
分区容错性,容灾能力
分布式环境多台服务器运行,其中一部分机器故障了,整个系统仍然可以正常运行提供服务
CAP不能同时满足
必须满足P
首先分布式环境,系统需要稳定运行,一台服务器意外断电,不应该影响系统整体功能正常,另一台或多台服务器还能稳定提供服务,所以分区容错是必须要满足。
满足C
数据一致性,所指的是同一个服务所在不同服务器的数据是同步的。如上改名字的场景 南柯一梦 改为 南柯梦 (在上海的数据库被修改) 那么系统要做到满足数据一致性,必须马上同步广州和新加坡的数据库,这样才能满足广州或者新加坡的访问者获得的结果也一致是 "南柯梦" 而不是"南柯一梦"
满足A
服务可用性,指任何时候访问服务,都返回结果
A与C是冲突的,上海服务器南柯一梦改为南柯梦后,为了服务可用,此时间访问新加坡和广州的服务器,返回的结果应该是南柯一梦(任何时候服务都返回结果) 但是严格上讲,数据是错误的,因为用户已经改了名字,改为南柯梦,但是数据在上海的才是正确的。
满足数据一致性必须牺牲服务可用性 或者相反
要达到数据一致性的要求,必须在上海服务器修改数据的同时,同步广州和新加坡的数据库,并且在数据同步完成之前,访问广州和新加坡的数据库中这条数据需要等待,返回同步后的结果(一致性)。
失去了服务可用性(这里服务是等待数据同步完成才返回结果,而不是立刻返回)
因此CAP 要么 满足AP (分区服务可用)要么 CP (分区数据一致)
分布式中事务
商品购买中的事务
以商品购买生成订单为例子
网络上用户A 购买 一双鞋子 价格50 付款后生成消费订单
事务中包含子的服务
这里简单设为三个服务,他们是事务相关的
1.商品信息服务
提供商品信息等服务
鞋子 颜色 价格 库存数量等信息 这里设 价格price为 50 库存数 num 9
2.商家账号收款服务
提供金额收入信息等服务
用户购买鞋子,需要付款50元到商家账号
3.用户消费订单服务
提供购买消费凭证信息等服务
首先分析用户购买鞋子,三个服务分别要做什么
@1 鞋子库存减1
@2 商家账号金额增加50
@3 生成 用户购买鞋子的订单记录, 包括数量金额等信息
事务特性
原子性
@1 @2 @3 要么同时发生,要么都不发生
一致性
鞋子库存减少1,收入增加50
隔离性
鞋子库存减1,后续用户最多只能购买(9-1=8)双鞋子
持久性
动作执行成功后,订单生效,收入新增50生效,库存减1生效
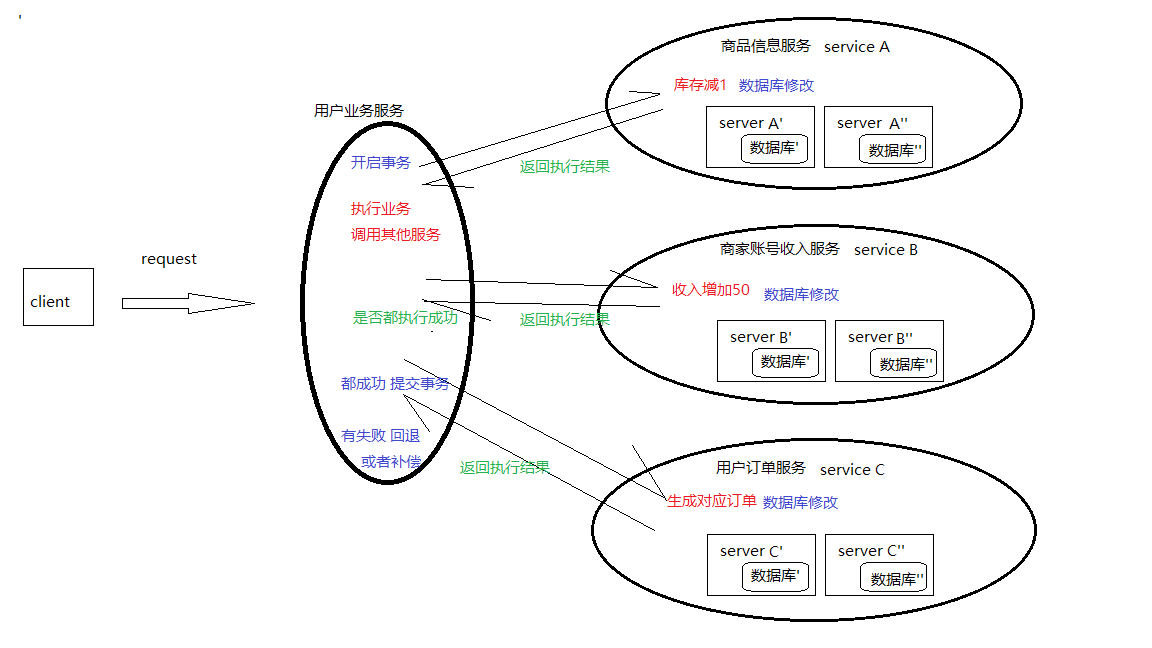
上述三个服务他们可以在不同的地点,不同机器上部署的,并很常见。
保证数据正确
开启事务
确定要执行的服务,每个服务的数据库事务开启
执行业务
调用库存减1,转账,生成订单等子服务
提交
业务执行过程中没有意外,各子服务的数据库提交事务,生效数据修改
回退
回退,如果服务调用出现了差错,或者某个子服务执行失败,可以通过回滚所有数据库达到数据正确。
补偿
某些情况下,某个子服务执行失败,但是不影响整体业务,也可以提交事务,后续补偿机制将失败的子服务重新执行。
补偿机制
个人认为就商品购买而言,补偿机制多数情况可以使用且实用。(对强一致要求没那么高的情况下)
@1 库存减1
@2 收入增加50
@ 3生成订单记录
如果这次执行的动作, 只有@3失败,@1 @2成功 说明金额交易,商品库存业务都没问题,只是订单记录失败,这是可以提交事务的,订单错误可以生成一条记录(携带商品,金额等信息),发送到MQ消息队列(或者其他设计)通过消息队列通知订单相关服务,补偿重新执行生成订单,达到最终一致性。
分布式事务控制问题
不同服务在不同区运行
不管是从安全性,稳定性,还是服务粒度细化方便维护等多因素考虑,都是很有必要让不同的服务分开在不同服务区运行。
单体数据库的事务不被支持,购买商品到生成订单所有操作加起来算一个事务,涉及的数据在不同一服务(不同的数据库),并且同一个服务可能运行在多台服务器上。
数据库开启事务针对的是单台服务器,多个服务多个数据库,并不支持数据库的事务,需要额外设计处理数据一致性问题(或者最终一致性)
同一个服务运行在多个区
不同服务不在一个服务器,同样的,分布式为稳定性可用而生,因此,一个服务大多有在多个区的服务器上运行,开启事务的时候,如何保证事务开启提交等事务相关命令每次发送到同一个区的同一个服务器,也是一定要考虑的问题。
分布式事务处理方式
如上所述分布式服务代表多个数据库,不支持数据库的事务,
如何保证事务中涉及的数据库数据修改都提交生效或者都回滚。
建立控制中心
控制中心在执行业务时,统一发送开始事务的命令给三个服务,返回状态
状态没问题执行数据修改,
都没问题就发送给三个服务,提交事务,否在回滚事务
消息机制事务
MQ消息队列,达到控制事务正确目的,项目中kafka听的比较多,可在高并发环境下稳定运行,可以通过消息机制发送事务处理结果到子服务,子服务收到消息,通过分析消息内容,做出对应的操作,达到事务一致性或者最终一致性等目的
思考图:
