1.Python的基本数据类型:
1、int(整数),主要用来进行数学运算,(不可迭代)
2、str(字符串) (可迭代)
3、bool(布尔值) 判断真假 true false
4、list(列表) 存储大量数据 用[]表示 (可迭代)
5、tuple(元组),不可以发生改变 (5可迭代)
6、dict(字典),保存键值对,可以保存大量的数据,无序
7、set(集合),保持大量数据,不可以重复
1.基础数据类型总结
| 有序无序 | 是否可变 | 是否迭代 | 取值方式 | |
|---|---|---|---|---|
| int | 有序(不支持索引) | 不可变(可哈希) | 不可迭代 | 直接查看 |
| bool | 不可变(可哈希) | 不可迭代 | 直接查看 | |
| str | 有序(支持索引) | 不可变(可哈希) | 可迭代 | 通过索引查看 |
| tuple | 有序(支持索引) | 不可变(可哈希) | 可迭代 | 通过索引查看 |
| list | 有序(支持索引) | 可变(不可哈希) | 可迭代 | 通过索引查看 |
| dict | 无序(不支持索引) | 可变(不可哈希) | 可迭代 | 通过键查看 |
| set | 无序(不支持索引) | 可变(不可哈希) | 可迭代 | 直接查看 |
##注意事项
-
列表和元组进行乘法时元素都是共用的
lst = (1,2,[]) lst1 = lst * 2 lst1[-1].append(8) print(lst) print(lst1) >>>(1, 2, [8]) (1, 2, [8], 1, 2, [8]) -
字典和集合
- 大小说的是字典的长度,长度就是键值的个数
- 不能修改键值对的大小,但能修改键对应的值
-
集合
- 大小说的是集合的长度,长度就是元素的个数
2.字符串
- 字符串在+和*时都是新开辟地址
3.元组
-
V1 = (11, 22, 33) ###tuple
-
数据类型之一,支持索引,支持切片
-
元组是一个有序、可迭代、不可变的数据类型
-
元组 v1 = (11,22,33) ---->叫元组,元组里的一个个值叫元素,以逗号分隔
-
元组不能增删改,只能查
-
()括号中如果只有一个元素,并且没有逗号,那么它不是元组,它与该元素的数据类型一致。
-
长度说的是元素的个数
v1 = (11, 11, 22, 33) print(v1.count(33)) >>>>1 print(v1.count(11)) >>>>2 ###统计元素的个数 print(v1.index(33)) >>>>3 ###通过元素的名称获取元素的索引 -
面试题
# a = (10) print(type(a)) >>><class 'tuple'> #当小括号中没有逗号时,数据类型就是括号中数据类型本身 # a = ("alex") print(type(a)) >>><class 'str'> #当小括号中没有逗号时,数据类型就是括号中数据类型本身 # a = ("alex",) print(type(a)) >>><class 'tuple'> #这是一个元组 # a = () print(type(a)) >>><class 'tuple'> #这是元组 # a = (1,2,3) print(type(a)) >>><class 'tuple'> #这是元组
4.列表
- V1 = [11, 22, 33] 以逗号分隔每一个内容为元素
- 列表就是一容器
- 可以存储大量不同数据类型的数据
- 列表可以增删改查
- 列表是可变数据类型,可迭代数据类型,有序数据结构
- 列表在进行乘法时,元素都是共用的
##增
+
lis = [1,2,3]
lst1 = [4,5,6]
print((lis + lst1))
>>>>[1, 2, 3, 4, 5, 6]
*
lst = [1,2,3]
print(lst * 5)
>>>>[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
append 追加
lst = ["Python学习手册", "核心编程"]
lst.append("流畅的Python")
print(lst)
>>>>['Python学习手册', '核心编程', '流畅的Python']
insert 按照索引插入
lst = ["Python学习手册", "核心编程"]
lst.insert(0, "Python的学习手册2")
print(lst)
>>>>['Python的学习手册2', 'Python学习手册', '核心编程']
extend 迭代着追加
lst = ["Python学习手册", "核心编程"]
lst.extend(["老男孩"])
print(lst) >>>>['Python学习手册', '核心编程', '老男孩']
lst.extend("老男孩")
print(lst) >>>>['Python学习手册', '核心编程', '老男孩', '老', '男', '孩']
##删
pop 按照索引位置删除,默认删除列表中最后一位元素,并且有返回值,返回被删除的元素
lst = ["傻屌1", "笨蛋1", "傻狗1"]
lst.pop(1)
print(lst)
>>>>['傻屌1', '傻狗1']
remove 指定元素删除,如果有重名元素,默认删除从左数第一个
lst = ["傻屌1", "笨蛋1", "傻狗1"]
lst.remove("傻屌1")
print(lst)
>>>>['笨蛋1', '傻狗1']
clear 清空整个列表,不能指定
lst = ["傻屌1", "笨蛋1", "傻狗1"]
lst.clear()
print(lst)
>>>>[]
del 删除整个列表,也可按照索引删除 del l1[-1]
lst = ["傻屌1", "笨蛋1", "傻狗1"]
del lst
print(lst)
>>>>>NameError: name 'lst' is not defined
del lst[2]
print(lst)
>>>>['傻屌1', '笨蛋1']
###for循环删除
lst = [11,22,33,44,55]
for循环
####投机取巧
for i in lst:
lst.clear()
print(lst)
####方式一:
for i in range(len(lst)):
lst.pop(0)
print(lst)
for i in range(len(lst)):
lst.pop()
print(lst)
####方式二:
lst = [11,22,33,44,55]
lst1 = lst.copy()
for i in lst1:
lst.remove(i)
print(lst)
##改
- 按照索引进行改值
lst = ["傻屌1", "笨蛋1", "傻狗1"]
lst[2] = "傻帽1"
print(lst)
>>>>['傻屌1', '笨蛋1', '傻帽1']
- 按照切片进行改值
- 必须是可迭代数据,步长为1时,修改的内容可多可少
lst = ["傻屌1", "笨蛋1", "傻狗1", "哈皮1"]
lst[1:3] = "杀鬼", "鸟蛋", "狗屎"
print(lst)
>>>>['傻屌1', '杀鬼', '鸟蛋', '狗屎', '哈皮1']
lst[0:3] = "杀鬼鸟蛋狗屎"
>>>>['杀', '鬼', '鸟', '蛋', '狗', '屎', '哈皮1']
#######################################################################
l1 = [44, 55, 66]
l1[2:] = "f","s","asdasd","asdasdasdasd"
>>>>[44, 55, 'f', 's', 'asdasd', 'asdasdasdasd']
- 按照切片(步长)进行改值,所谓的隔值进行更改
- 必须是可迭代数据,步长不为1时,修改的内容得一一对应
lst = ["傻屌1", "笨蛋1", "傻狗1", "哈皮1","山药","鬼"]
lst[0:4:2] = [ "狗屎","朱"]
print(lst)
>>>>['狗屎', '笨蛋1', '朱', '哈皮1', '山药', '鬼']
lst[1:3:2] = [ "狗屎"]
>>>>['傻屌1', '狗屎', '傻狗1', '哈皮1', '山药', '鬼']
lst[1:4:2] = [ "狗屎","猪"]
>>>>['傻屌1', '狗屎', '傻狗1', '猪', '山药', '鬼']
-
反向列表中的元素
lst = [1,2,3,4,6,5] lst.reverse() # 原地修改 print(lst) >>>>[5, 6, 4, 3, 2, 1]- 排序
lst = [1,2,3,4,6,5] lst.sort() # 排序 默认是升序 print(lst) >>>>[1, 2, 3, 4, 5, 6]- 降序
lst = [1,2,3,4,6,5] lst.sort(reverse=True) # 降序 print(lst) >>>[6, 5, 4, 3, 2, 1]
##查
按照索引进行查找(索引正序从0开始,倒序从-1开始)
l1 = [44, 55, 66, 22, 22]
print(l1[1])
>>>>55
安装切片进行查找
l1 = [44, 55, 66, 22, 22]
print(l1[0:3])
>>>[44, 55, 66]
例子:
li = [1, 3, 2, "a", 4, "b", 5, "c"]
print(li[0:3]) >>>>[1, 3, 2]
print(li[1:7:2]) >>>>[3, 'a', 'b']
print(li[-3:-8:-2]) >>>>['b', 'a', 3]
#列表嵌套
lst = ["傻屌1", ["笨蛋1","笨蛋2", ["傻狗1", "傻狗2"],"哈皮1"],"山药","鬼"]
print(lst[1][2][1])
>>>>傻狗2
5.while循环
- break #跳出当前循环,while循环遇到break直接退出不再循环
- continue #跳出本次循环,继续下次循环(continue就是所在循环体的最后一行代码,循环遇到continue相当于执行到循环底部)
- 在循环体中当遇到break或continue,那么此循环体中break或continue下方的代码都不会被执行
- while...else语句,while如果被break打断,则不执行else语句
6.if循环
-
单if
-
if...else...
-
if...elif...elif...elif
-
if...elif...elif...else
-
if嵌套
-
if...if...if
-
例子
# num = input("儿子,让爸爸看看你考了多少分:") # if int(num) >= 90: # print("A") # elif int(num) >= 80 and int(num) < 90: # print("B") # elif int(num) >= 70 and int(num) < 80: # print("C") # else: # print("太笨了,不像我,呼伦贝尔大草原呀") -
三元运算
num = input("请输入你喜欢的数字:") s = 0 if int(num) > 0: for i in num: s = s + int(i) ** 3 # print(s) ###三木 print("是水仙花" if s == int(num) else "不是")
7.for循环
-
for循环结构
# for i in xxx: # for 关键字 # i 变量名 # in 关键字 # xxx 可迭代对象 -
例子:
name = "alex" for i in name: print(i) a l e x -
for i in "": ###为空 print(i) ###不会执行
8.编码
- ASCII 最早的密码本,不支持中文。
#英文 一个字符占用8位
- GBK 国标
#英文 一个字符占用8位(1字节)
#中文 一个字符占用16位(2字节)
- Unicode 万国码 兼容性高
#英文 32位(4字节)
#中文 32位(4字节)
- UTF-8 Unicode的升级版本
#英文 8位(1字节)
#欧洲 16位(2字节)
#亚洲 24位(3字节)
-
单位转换:
1byte = 8bit 1kb = 1024byte 1mb = 1024kb -
在内存中所有的编码必须是unicode存在,除去bytes
#bytes
-
bytes类型存在的意义:
因为Python字符串类型为str,在内存中用Unicode表示,但是在网络传输过程中或者要存入磁盘时,就需要将str转换成以字节为单位的bytes类型
9.str取值
安装索引:s1[index]
按照切片:s1[start_index:end_index+1]
按照切片步长:s1[start_index:end_index+1:2]
反向按照切片步长:s1[start_index:end_index后延一会:2]
10.哈希数据类型
- 不可变数据类型(可哈希):int str tuple bool
- 可变(不可哈希)的数据类型:list dict set
11.解构
- 一行代码进行数值交换
a = 10
b = 20
a, b = b, a
print(a) >>>>>20
print(b) >>>>>10
a ,b ,c, d, f = (1, 2, 3, 4, 5)
print(a, b, c, d, f)
>>>>1 2 3 4 5
a ,b ,c, d, *f = (1, 2, 3, 4, 5, 6, 7, 8)
print(a, b, c, d, f)
>>>>>1 2 3 4 [5, 6, 7, 8]
12.字典
-
info = {’k1‘:'v2','k2','v2'}
k1和k2叫键(keys) v1和v2叫值(values )
-
键:必须是不可变的数据类型(int,str,bool,tuple),唯一的
-
值:任意数据类型,对象
-
查找方便,查询速度快 ,可存储大量的关联型数据
-
可变,无序,不支持索引
-
例子:
info = {'k1':'v2', 'k2': 'v2'} print(info.keys()) >>>>dict_keys(['k1', 'k2']) print(info.values()) >>>>dict_values(['v2', 'v2']) ############ dic = {} print(dict(k=1,v=2,b=4)) print(dict([(1,2),(4,5),(7,8)])) >>> {'k': 1, 'v': 2, 'b': 4} {1: 2, 4: 5, 7: 8} ##################### locals = {'沪':'上海', '⿊':'⿊⻰江', '鲁':'⼭东'} for i in locals: print(i) >>>>沪 黑 鲁
##批量创建键值对
- fromkeys(seq,values)
- 批量创建键值对,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值
dic = dict.fromkeys('abc', 100)
print(dic) >>>>{'a': 100, 'b': 100, 'c': 100}
dic1 = dict.fromkeys([1, 2, 3], "qwe")
print(dic1) >>>>{1: 'qwe', 2: 'qwe', 3: 'qwe'}
dic2 = dict.fromkeys([1, 2, 3], [])
print(dic2) >>>>{1: [], 2: [], 3: []}
dic3 = dict.fromkeys([1, 2, 3], [])
dic3[1].append(666)
print(dic3)>>>>{1: [666], 2: [666], 3: [666]}
##增
- 通过键直接加
dic2 = {'na' : 'chen', 'age22' : '32'}
dic2["inttt"] = "lichen"
print(dic2)
>>>>{'na': 'chen', 'age22': '32', 'inttt': 'lichen'}
- setdefault()
- 如果键不已经存在于字典中,将会添加键并将值设为默认值None
dic2 = {'na' : 'chen', 'age22' : '32'}
dic2.setdefault('na',"18")
print(dic2)
>>>{'na' : 'chen', 'age22' : '32'} ###字典中键存在时不添加,不存在时再进行
dic2.setdefault('na2')
print(dic2)
>>>>{'na': 'chen', 'age22': '32', 'na2': None} ## 键不存在返回None
##删
- 字典中没有remove
- pop(),删除指定键值对
- 有返回值,返回被删除的键对应的值
dic2 = {'na' : 'chen', 'age22' : '32'}
dic2.pop('na')
print(dic2)
>>>>{'age22': '32'}
- clear()
- 清空
- popitem()
- 随机删除,默认删除最后一个
dic2 = {'na' : 'chen', 'age22' : '32'}
dic2.popitem()
print(dic2)
>>>>{'na': 'chen'}
- del
- 删除整个字典
- 可指定键进行删除
dic2 = {'na' : 'chen', 'age22' : '32'}
del dic2['na']
print(dic2)
>>>>{'age22': '32'}
###for循环删除字典中的键值对
dic = {"key":1,"key2":2}
dic1 = dic.copy()
for i in dic1:
del dic[i]
print(dic)
>>>>{}
##改
- 通过键直接改,键不存在时再增加
dic2 = {'na' : 'chen', 'age22' : '32'}
dic2['na'] = "chenhao"
print(dic2)
>>>>>>{'na': 'chenhao', 'age22': '32'}
dic2['name'] = "ALEX"
>>>>>>{'na': 'chen', 'age22': '32', 'name': 'ALEX'}
- update
- 增加键值对(有则更新,无则添加)
dic = {'na' : 'chli', 'age' : '18'}
dic2 = {'na' : 'chen', 'age22' : '32'}
dic.update(dic2) >>>>{'na': 'chen', 'age': '18', 'age22': '32'}
dic2.update(dic) >>>>{'na': 'chli', 'age22': '32', 'age': '18'}
dic.update(na = 'yyf',set = 'asdasd') >>>>{'na': 'yyf', 'age': '18', 'set': 'asdasd'}
dic = {}
dic.update({"ysue" : "asd"})
print(dic) >>>{'ysue': 'asd'}
##查
-
通过键直接查找,查不到会报错
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2['na']) >>>chen 通过键查找,查不到是报错 -
keys()
- 获取字典索引的键
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2.keys()) >>>>dict_keys(['na', 'age22']) -
values()
- 获取字典所有的值
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2.values()) >>>>>dict_values(['chen', '32']) -
setdefault()
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2.setdefault('na')) >>>>chen -
get()
- 存在是返回值,不存在返回None
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2.get('age22')) >>>32 print(dic2.get('name')) >>>>None 键不存在时返回None- 通过键查找,若键存在,返回对应的值,若不存在,可指定返回内容
dic2 = {'na' : 'chen', 'age22' : '32'} print(dic2.get('age22','没有找到')) >>>>32 print(dic2.get('name','没有找到')) >>>>没有找到 dic2["age22"] = dic2.get("age22") + 1 print(dic2) >>{'na': 'chen', 'age22': 33} dic = {"A": {"c" : "稷山"}, "B": "唐山"} dic['A']['c'] = dic.get(dic['A']['c'], 1) +1 print(dic) >>>>{'A': {'c': 2}, 'B': '唐山'}
##高仿列表
- 可用于for循环
dic2 = {'na' : 'chen', 'age22' : '32'}
lst = dic2.keys()
print(lst)
>>>> ['na', 'age22']
##字典的嵌套
dic = {"1":"饺子",
"2":"粥",
"3":"面条",
"4":"肉",
"5":"土",
"6":"东南风",
"7":"切糕",
"8":"烤全羊",
"9":"烤骆驼",
"10":"锅包肉",
"11":"杀猪菜",
"12":"乱炖"
}
while True:
choose = input("请输入月份:")
if choose in dic:
print(dic[choose])
13.运算符
##比较运算符
-
> < >= <= == !=
##算术运算符
-
+ - * /(加减乘除) //(整除|底板除(向下取整)) ** 幂 % 取余 (模) #### print(5 / 2) # 2.5 #### print(5 // 2) # 2 #### print(2 ** 0) # 1 #### print(5 % 2) # 1
##赋值运算符
-
#### = #### += #### -= #### *= #### /= #### //= #### **= #### %= #### a = 10 #### b = 2 #### b += 1 # b = b + 1 #### a -= 1 # a = a - 1 #### a *= 2 # a = a * 2 #### a /= 2 # a = a / 2 #### a //= 2 # a = a // 2 #### a **= 2 # a = a ** 2 #### a %= 2 # a = a % 2
##逻辑运算符
-
and ## or ## not
-
优先级:()> not > and > or
-
查找顺序:从左到右
-
练习
# 3>2 and 4>2 or True and not False and True # 3>2 and 4>2 or True and True and True # True and True or True and True and True -
Ture和False进行逻辑运算时:
and:
- 一真一假,就是假
- 同真为真,同假为假
or:
- 一真一假就是真
- 同真为真,同假为假
-
and数字进行逻辑运算时:
- 数字不为0时和不为False,and运算选择and后面的内容
- and运算都为假是选择and前的内容
- and运算一真一假选择假
-
or数字进行逻辑运算时:
- 数字不为0时和不为False,or运算选择or前面的内容
- or运算都为假时选择or后面的内容
- or运算一真一假选择真
##成员运算符
- in(在)
- not in(不在)
name = "alex"
msg = input(">>>")
if name in msg:
print(111)
else:
print(222)
14.格式化输出
#%s-%d-%i
name = input("name")
age = input("age")
msg = """
------info------
name:%s
age:%s
-------end------
"""
print(msg%(name,int(age),))
####此处的变量会按照位置来进行一一对应
-
%:占位符
-
%s字符串:%s可以填充字符串也可以添加数字
-
%d或i% 整型:必须填充数字
name = int(input("请输入你喜欢的数字")) msg = ''' NAME = %d ''' print(msg%(name)) -
%%转义:变成普通的%
num = int(input("请输入你喜欢的数字")) msg = ''' NUM = 目前的学习进度是%d%% ''' print(msg%(num))
#f-strings
F(f)+ str的形式,在字符串中想替换的位置用{}展位,与format类似,但是用在字符串后面写入替换的内容,而他可以直接识别
msg = f'name:{input("name")},age:{input("age")}'
print(msg)
-
任意表达式
- 字典
lst = {'name' : 'chenhao_li' , 'age' :18} msg = f"我是{lst['name']},年龄{lst['age']}" print(msg) >>>>我是chenhao_li,年龄18- 列表
lst = ['chenhao_li',18] msg = f"我是{lst[0]},年龄{lst[1]}" print(msg) >>>>我是chenhao_li,年龄18 -
表达式
- 用函数完成相应的功能
def lst(a,b): return a + b a = 1 b = 2 print("相加为:" + f"{lst(a,b)}") >>>>相加为:3 -
多行f输入
name = 'barry' age = 18 ajd = 'handsome' speaker = f'我叫{name}.' f'You are {age} years old.' print(speaker) >>>>我叫barry.You are 18 years old. -
if
a = 10 b = 20 msg = f"{a if a < b else b}" print(msg) >>>>10 -
其他
print(f"{{73}}") # {73} print(f"{{{73}}}") # {73} print(f"{{{{73}}}}") # {{73}}-
!,:{};这些标点不能出现在{}里面,会报错
-
使用lambda表达式会出现问题,可将lambda嵌套在圆括号里面解决问题
x = 5 print(f'{(lambda x: x*2) (x)}') # 10
-
15.赋值与深浅copy
##赋值
- 两个或多个变量名指向同一个内存地址,有一个操作内存地址的值进行改变,其余的变量名在查看的时候都进行更改
##浅copy
-
只copy第一层的元素内存地址,可变的不可变的数据都是公用的
-
多个变量指向同一个内存地址时,如果要修改的内存地址的数据是可变数据类型时,会在原地进行修改(列表、集合)。如果要修改的内存地址的数据是不可变数据类型时,是会重新开辟一个空间(字符串,数字)
-
共用一个值(不同变量的地址指向同一个值)
-
这两个变量指向值的内存地址一样
-
可变数据类型:对其中一个变量的值改变,另外一个变量的值也会改变
-
不可变数据类型:对其中一个的改变,另外一个不变
-
不可变数据类型时
lst1 = [1, 2, 3, [9, 8, 7], 4] lst2 = lst1[:] #浅copy lst1.append(99) print(lst1,lst2) >>>>[1, 2, 3, [9, 8, 7], 4, 99] [1, 2, 3, [9, 8, 7], 4] -
可变数据类型时
lst1 = [1, 2, 3, [9, 8, 7], 4] lst2 = lst1[:] lst1[-2].append(99) print(lst1,lst2) >>>>[1, 2, 3, [9, 8, 7, 99], 4] [1, 2, 3, [9, 8, 7, 99], 4]
-
##深copy
-
对于不可变的数据,元素是共用的,可变的数据,开辟新的空间,不管嵌套多少层(copy完之后,彼此之间没关系,各过个的日子)
-
两个变量的内存地址不同
-
两个变量各有自己的值,且互不影响
-
对其任意一个变量的值的改变不会影响另外一个
-
不可变数据类型
b = [1 ,2, 3, [99, 88, 77]] b1 = copy.deepcopy(b) b.append(44) print(b,b1) >>>>[1, 2, 3, [99, 88, 77], 44] [1, 2, 3, [99, 88, 77]] -
不可变数据类型
b = [1 ,2, 3, [99, 88, 77], 22] b1 = copy.deepcopy(b) b[-2].append(44) print(b,b1) -
##==
- 判断等号两边的值是否相同
a = 10
b = 10
print(a == b)
>>>>Ture
##is
- 判断两边的值的内存地址是否相同
a = 10
b = 10
print(a is b)
>>>>Ture
16.小数据池和代码块(驻留机制)
驻留机制------节省内存,提高效率
代码块的优先级高于小数据池
##代码块
- 一个py文件、一个函数、一个模块、一个类、终端下的每一行
- 数字:-5 ~ 正无穷
- 所有的代码都是依赖代码块执行
- 乘法时总长度不能超过20
##小数据池
- 数字、字符串、布尔值
- 数字:-5 ~ 256
- 字符串
- 定义和乘法时不能出现中文和特殊字符
- 3.6版本乘法时总长度不能超过20
- 3.7版本乘法总长度不能超过4096
17.集合
-
set = {‘太白’, '张三', '李四', '王五'}
-
可以去重
s5 = {1, 1, 1, 2, 2, 2, 3, 3, 4, 4, 5, 6, 6 } l1 = list(s5) print(l1) ###>>> [1, 2, 3, 4, 5, 6] -
大小说的是集合的长度
##增
-
add 随意位置插入
set = {'太白', '张三', '李四', '王五'} set.add('xx') print(set) >>>>{'张三', '李四', '王五', '太白', 'xx'} -
update 随意位置按元素增加,并去除重复
set = {'太白', '张三', '李四', '王五'} set.update('asdasdasd') print(set) >>>>{'李四', '王五', 'd', '张三', '太白', 's', 'a'}
##删
-
remove 指定元素进行删除
set = {'太白', '张三', '李四', '王五'} set.remove('太白') print(set) >>>>{'李四', '王五', '张三'} -
pop 例:set.pop() 随机删除,有返回值
set = {'太白', '张三', '李四', '王五'} set.pop() print(set) >>>>{'张三', '李四', '太白'} -
clear() 清空
a = {1, 2, 3, 4, 5} a.clear() print(a) >>>>set()
##改
-
先删除再添加
a = {1, 2, 3, 4, 5} a.remove(2) a.add(333) print(a) >>>>{1, 3, 4, 5, 333} -
转换数据类型
a = {1, 2, 3, 4, 5} b = list(a) b[2] = 33 print(b) >>>>[1, 2, 33, 4, 5]
##查
- for 循环
##交-并-差-反交-子-超
s1 = {1, 2, 3, 4, 5, 6}
s2 = {5, 6, 7, 8, 9, 10}
###交集
print(s1 & s2) ###>>>{5, 6}
###并集
print(s1 | s2) ###>>>{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
###差集
print(s1 - s2) ###>>>{1, 2, 3, 4} #s1对比s2取独有的
print(s2 - s1) ###>>>{8, 9, 10, 7} #s2对比s1取独有的
###反交集
print(s1 ^ s2) ###>>>{1, 2, 3, 4, 7, 8, 9, 10}
###子集
s3 = {1, 2, 3}
s4 = {1, 2, 3, 4, 5}
print(s3 < s4) ###>>>True
###超集
print(s3 > s4) ###>>>False
18.文件操作
##文件操作模式
- r 只读
- w 清空写(可创建文件)
- a 追加写(可创建文件)
- rb 只读字节
- wb 清空写字节
- ab 追加写字节
- r+ 读写
- w+ 清空写读
- a+ 追加写读
##文件操作步骤
f = open("文件名字或文件路径",mode="操作模式",encoding="编码")
##转义
- "C:user" 用两个 转义一个
- r"C:user" 用 r 代表转义 (推荐使用)
f = open(r"C:Python_26day07萝莉.txt",mode="r",encoding="utf-8")
##读操作( r , rb)
- read() 全读
- read(3) r 模式是三个字符,rb 模式是三个字节
- readline() 读取一行,默认带一个
- readlines() 读取所有,存储在列表中
- for i in f: 文件句柄可以迭代,一行一行读取
##清空写( w , wb)
- 有文件时清空文件,没文件时创建文件
- 打开文件时清空文件内容
- 写入内容
def lst(name,sex,age,work):
mingdan = (f"姓名:{name},性别:{sex},年龄:{age},学历:{work}")
with open("student_msg.txt","a",encoding="utf-8") as f:
f.write("
"+mingdan)
lst("lichenhao","nan",18,"IT")
##追加写( a,ab)
-
没文件时创建文件
-
永远在文件的末尾添加内容
f = open("F:学习python-lch作业day08l1.txt","a",encoding="utf-8") f.seek(0,0) print(f.tell()) f.write("嘿嘿我是李晨浩sb") ####在已有的内容后面进行追加
##“+”操作
-
r+ 读写 覆盖内容
# f = open("test","r+",encoding="utf-8") # a = f.read() # print(a) # f.write("这是读写") #####此处就是先读 之后在写之前清空# f = open("test","r+",encoding="utf-8") # f.write("这是读写啊") # a = f.read() # print(a) #####此处就是先清空再写 之后再读 -
w+ 清空写读
# f = open("test","w+",encoding="utf-8") # f.write("哈哈哈") # f.seek(0,0) # 移动光标 移动到文件的头部 # print(f.read()) #####先写 再读 -
a+ 追加写读(文件不存在时,实时显示)
f = open("F:学习python-lch作业day08l1.txt","a+",encoding="utf-8") f.write("asdasd嘿sss嘿") # f.seek(0,0) # 移动光标 移动到文件的头部 print(f.read()) #####直接在已有的内容后面追加
##光标seek()
- seek(0,0) 移动到文件头部
- seek(0,1) 移动到光标当前位置(没用)
- seek(0,2) 移动到末尾
- seek(3) 按照字节移动,根据不同编码决定移动字节大小
- tell() 查看光标,返回的是字节
##with open
- 自动关闭文件
- 可以操作多个文件
- as 起别名
with open("l1.txt","r",encoding="gbk") as f,
open("l2.txt","r",encoding="utf-8")as f1:
print(f.read())
print(f1.read())
##os
- 与操作员系统做交互
export os
os.rename("test","test2") 将test改名为test2
##注意事项:
-
在不移动光标的情况下,文件中的内容只能读取一次
-
a和w可以创建文件
-
写的类型必须是字符串
-
w写的时候想加换行符" "必须加引号再加上要写的内容
f.write(" "+mingdan) -
f.flush() 刷新
-
f.close() 关闭文件
19.迭代器
#迭代器
-
方法一:
lst = [1,2,3,4] l = lst.__iter__() #l是迭代器 print(l.__next__()) print(l.__next__()) print(l.__next__()) print(l.__next__()) >>>1 2 3 4 -
方法二:(推荐使用)
lst = [1,2,3,4] l = iter(lst) #l是迭代器 print(next(l)) print(next(l)) print(next(l)) print(next(l)) >>>>1 2 3 4 -
for循环支持直接循环迭代器
lst = [1,2,3,4] l = iter(lst) for i in l: print(i)
#for循环本质
-
for循环就是一个迭代器(for循环本质)
s = "alex" s1 = s.__iter__() #将数据转换成迭代器 while 1: #通过死循环不断调用 try: print(s1.__next__()) except StopIteration: #捕获异常,使之不会抛出异常 break >>> a l e
#可迭代对象和迭代器:
-
可迭代对象(str list tuple)
- 迭代器也是一个可迭代对象
- 具有iter()方法的就是一个可迭代对象
- 优点:1.使用灵活(每个可迭代对象都有自己的方法)
2.能够直接查看元素的个数
- 缺点:1.占内存
- 当内存大,数据量比较少时,建议使用可迭代对象
-
迭代器(文件句柄就是一个迭代器)
- 可next()和iter()的就是一个迭代器
- 优点:1.节省内存
- 缺点:1.只能一个方向执行
2.一次性的
3.不能灵活操作,不能直接查看元素的个数
- 内存小,数据量巨大时,建议使用迭代器
#时间、空间
-
时间换空间:迭代器、生成器
-
空间换时间:可迭代对象,使用大量的空间节省时间
20.生成器
- 生成器本身就是一个迭代器,迭代器不一定是生成器
- 惰性机制
- 迭代器都是Python给你提供的已经写好的工具或者通过数据转化得来的,(比如文件句柄,iter([1,2,3])。生成器是需要我们自己用python代码构建的工具
#基于函数实现的生成器
-
函数体中存在yield就是定义一个生成器
def func() print(1) yelid 5 print(func()) ##函数体中存在yelid就是生成一个生成器 ##print打印的是一个生成器对象的内存地址 -
生成器的使用 (next和yelid一一对应)
方法一:
def func(): yield 1 #记录执行位置 yield 2 yield 3 g = func() #获取生成器的内存地址 print(next(g)) #获取值 print(next(g)) #获取值 print(next(g)) #获取值方法二:
def func(): yield 1 #记录执行位置 yield 2 yield 3 g = func() #获取生成器的内存地址 print(next(g)) #获取值 print(next(g)) #获取值 print(next(g)) #获取值 g1 = func() print(next(g1)) #重头取值 print(next(g1)) #取值 >>>1 2 3 1 2方法三:函数嵌套
def func(): def foo(): print(1) yield foo g = func().__next__() ##g就是foo的内存地址 print(g(),type(g)) ##g() == foo() >>>1 None <class 'function'>方法四:列表
def func(): yield [1,2,3,4,5,6] print(func().__next__(),type(func().__next__())) >>>>[1, 2, 3, 4, 5, 6] <class 'list'>方法五:字典
def func(): yield {"name" : 123} print(func().__next__(),type(func().__next__())) >>>{'name': 123} <class 'dict'>方法六:返回多个
def func(): yield 1,2,3,4,5 print(next(func())) >>>>(1, 2, 3, 4, 5)方法七:yield from
def func(): yield from [1,2,3,4,5] g = func() print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g))
#生成器和迭代器区别:
- 迭代器:文件句柄,通过数据转换,Python自带提供
- 生成器:程序员自己实现
#生成器和函数区别
- 函数是return value ,生成器是yield value 并且能够标记或者记住yield执行的位置,以便下次执行时从标记点恢复执行,
- yield是函数转换成生成器,但是生成器又是一个迭代器
#时间、空间
-
空间还时间
-
时间换空间
def func(): for i in range(1,50001): yield i g = func() print(next(g)) print(next(g)) print(next(g)) print(next(g))
#区分迭代器和生成器
- 看内存地址(推荐)
- 看send()方法
def func()
yield 1
g = func()
print(g.send()) ###有send就是生成器
#迭代器和生成器的优缺点
-
优点:1、节省空间
-
缺点:1、不能直接使用元素
2、不能直接查看元素
3、使用不灵活
4、稍微消耗时间
5、一次性的, 不能逆行
#yield功能
- yield
- 能返回多个,以元组的形式存储
- 能返回各种数据类型(Ptyhon的对象)
- 能够写多个并且都能执行
- 能够记录执行位置
- 后边不写内容 默认返回None
- 能够暂停生成器的运行
- yield都是将数据一次性返回
#yield from 和 yield区别
- yield
- yield是将数据整个返回
- yield from
- 将可迭代对象逐个返回
#表达式(推导式)实现生成器
- 简化代码,提高逼格,提高可读性
- 生成一些有规律的数据,生成的数据较大时建议使用生成器推导式
- 推导式最多建议使用三层
#生成器推导式
-
普通模式
g = (i for i in range(3)) print(next(g)) >>>0 print(next(g)) >>>1 print(next(g)) >>>2 -
筛选模式
g = (i for i in range(3) if i+1 == 2) print(next(g)) >>>1
#列表推导式
-
普通循环
print([i for i in range(1,6)]) >>>[1,2,3,4,5] print([i for i in range(1,6,2)]) >>>[1,3,4] print([f"Py{i}期" for i in range(1,4)]) >>>['Py1期', 'Py2期', 'Py3期'] -
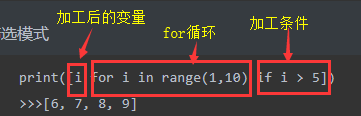
筛选模式
print([i for i in range(1,10) if i > 5]) >>>[6, 7, 8, 9] print([i+j for i in range(2) for j in range(2)]) # 推导式最多建议使用三层 >>>[0, 1, 1, 2]
#字典推导式
-
普通模式
print({i:i+1 for i in range(3)}) >>>{0: 1, 1: 2, 2: 3} -
筛选模式
print({i:i+1 for i in range(3) if i >1}) >>>{2: 3}
#集合推导式
-
普通模式
print({i for i in range(3)}) >>>{0,1,2} -
筛选模式
print({i for i in range(3) if i >0}) >>>{1,2} print({i for i in range(3) if i >2}) >>>set{}
#其他
names = [['Tom', 'Billy', 'Jefferson', ],['Alice', 'Jill', 'Ana', 'Wendy']]
print([em for i in names for em in i if "e" in em]) #查找有e的名字
>>>['Jefferson', 'Alice', 'Wendy']
print([em for i in names for em in i if em.count("e")>=2]) #查找名字中带e超过两个的
>>>['Jefferson']
multiples = [i for i in range(20) if i % 3 == 0]
print(multiples) >>>[0, 3, 6, 9, 12, 15, 18]
multiples = [i for i in range(20) if i % 3 is 0]
print(multiples) >>>[0, 3, 6, 9, 12, 15, 18]
21.闭包
- 闭包的定义
- 在嵌套函数中,使用非全局变量(且不适用本层变量)
- 将嵌套函数返回
- 作用:保持数据安全性,干净性
def func():
a = 10 # 自由变量
def foo():
print(a)
return foo
f = func()
print(f.__closure__) # 验证是否是闭包
print(f.__code__.co_freevars) # 查看自由变量
print(f.__code__.co_varnames) # 查看局部变量
>>>
(<cell at 0x0000024C254B9048: list object at 0x0000024C25365248>,)
('lst',)
('price', 'arg')
-
没有将嵌套的函数返回也是一个闭包,但这个闭包不是一个可使用的闭包
def func(): a = 10 def foo(): print(a) func() -
闭包的应用场景
- 装饰器
- 防止数据被误改动
-
实例(求几次的执行函数的平均值)
def buy_car(): lst = [] def func(price): # price = 1 lst.append(price) arg = sum(lst) / len(lst) print(arg) return func f = buy_car() print(f.__closure__) print(f.__code__.co_freevars) # 查看自由变量 print(f.__code__.co_varnames) # 查看局部变量 f(1) f(2) f(3) f(4) f(5)
22.装饰器
-
装饰器就是在原有基础的功能上添加新的功能的工具
-
开放封闭原则
- 对扩展开放,支持增加新功能
- 对修改的源代码是封闭的,对调用方式是封闭的
-
time
import time ###标准库 def index(): time.sleep(2) print("我真帅") index()
#标准版装饰器
def wrapper(f):
def inner(*args,**kwargs):
#被执行函数之前
ret = f(*args,**kwargs)
#被执行函数之后
return ret
return inner
@wrapper() ###func=wrapper(func)
def func()
print("我是被装饰函数")
#实例
####被装饰函数未传参
def wrapper(f):
def inner(*args,**kwargs):
print("我是爹,我先走")
ret = f() #
print("你是儿子,你后走")
return ret
return inner
@wrapper
def func():
return "我是女娲"
print(func())
>>>
我是爹,我先走
你是儿子,你后走
我是女娲
####被装饰函数传参
def wrapper(f):
def inner(*args,**kwargs):
print("我是爹,我先走")
ret = f(*args,**kwargs)
print("你是儿子,你后走")
return ret
return inner
@wrapper
def func(a,b,c):
print(f"我是女娲{a},{b},{c}")
func("ss","ww","yy")
#语法糖
-
语法糖必须要放在被装饰的函数正上方
-
语法糖的本质:被装饰的函数=装饰器函数(被装饰的函数)
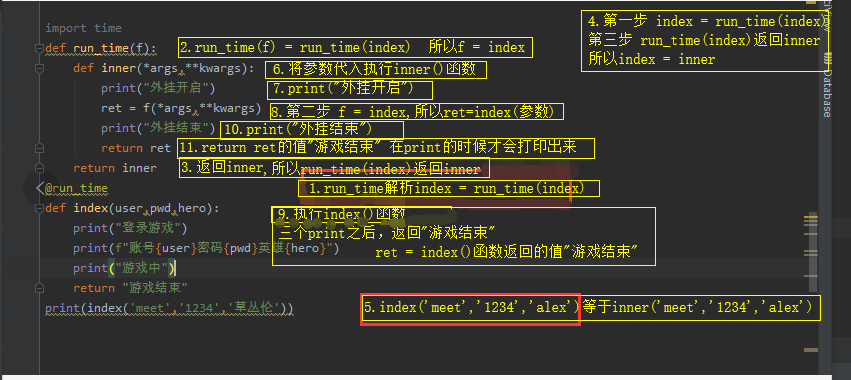
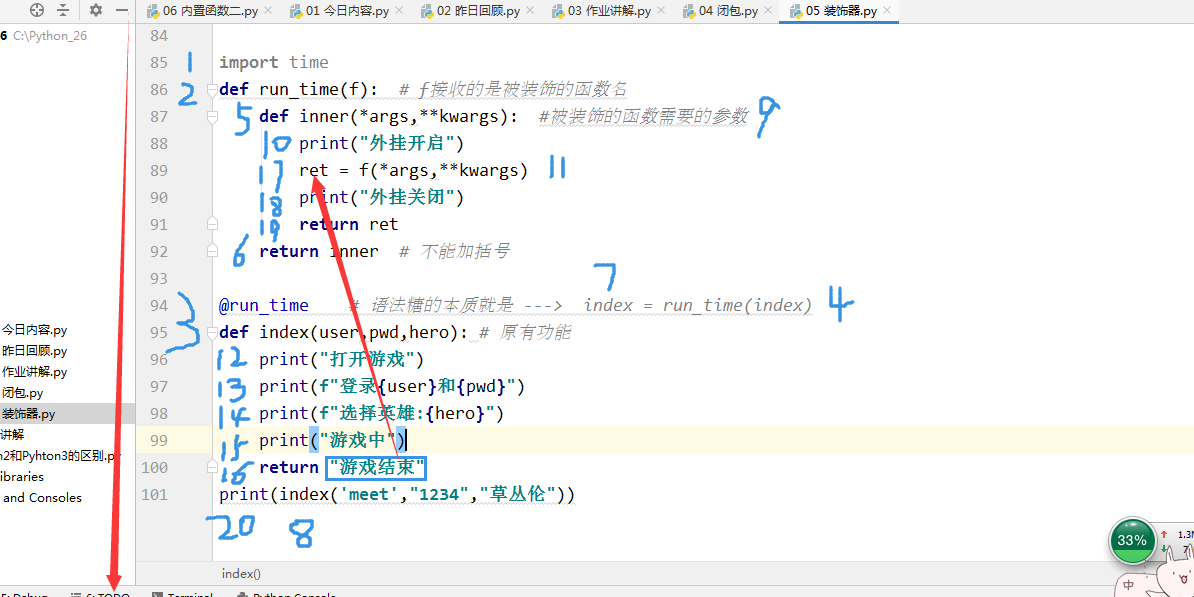
import time def run_time(f): #f接收的是被装饰的函数名 #run_time就是一个闭包 def inner(*args,**kwargs): #被装饰的函数需要的参数 strat_time = time.time() #被装饰函数之前 print("外挂开启") ret = f(*args,**kwargs) print("外挂结束") print(time.time() - strat_time) #被装饰函数之后 return ret return inner @run_time #语法糖的本质---> index=run_time(index) def index(user,pwd,hero): print("登录游戏") print(f"账号{user}密码{pwd}英雄{hero}") print("游戏中") return "游戏结束" print(index('meet','1234','草丛伦')) >>>
#有参装饰器
- 应用场景:flask框架的路由就是有参装饰器
##未带参数的装饰器
def wrapper(f):
def inner(*args,**kwargs):
#被执行函数之前
ret = f(*args,**kwargs)
#被执行函数之后
return ret
return inner
@wrapper() ###func=wrapper(func)
def func()
print("我是被装饰函数")
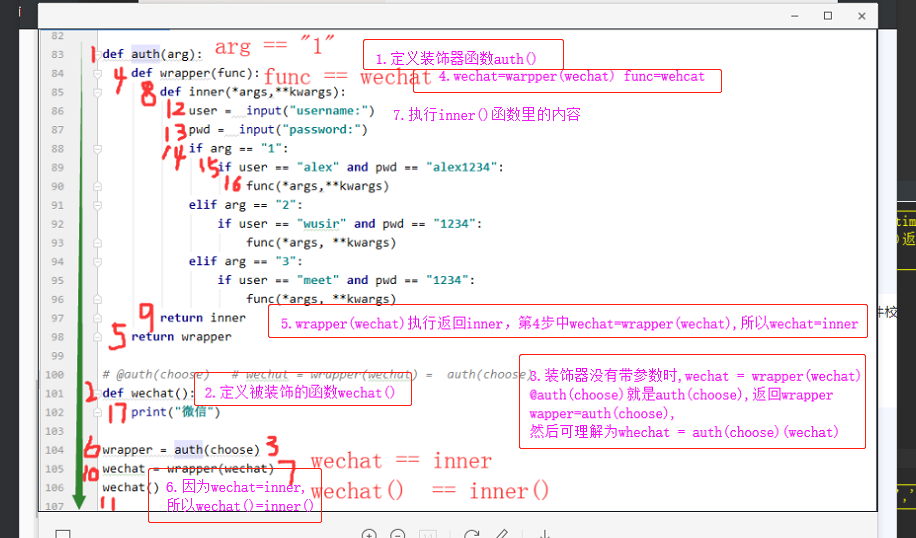
##带参数的装饰器
def wark(arg):
def wrapper(func):
def inner(*args,**kwargs):
ret = func1()
return ret
return inner
return wrapper
@wark(chose)
def func1():
print("我是被装饰函数")
##wrapper = wark(chose)
##func1 = wrapper(func1)
##func1()

#多个装饰器装饰一个函数
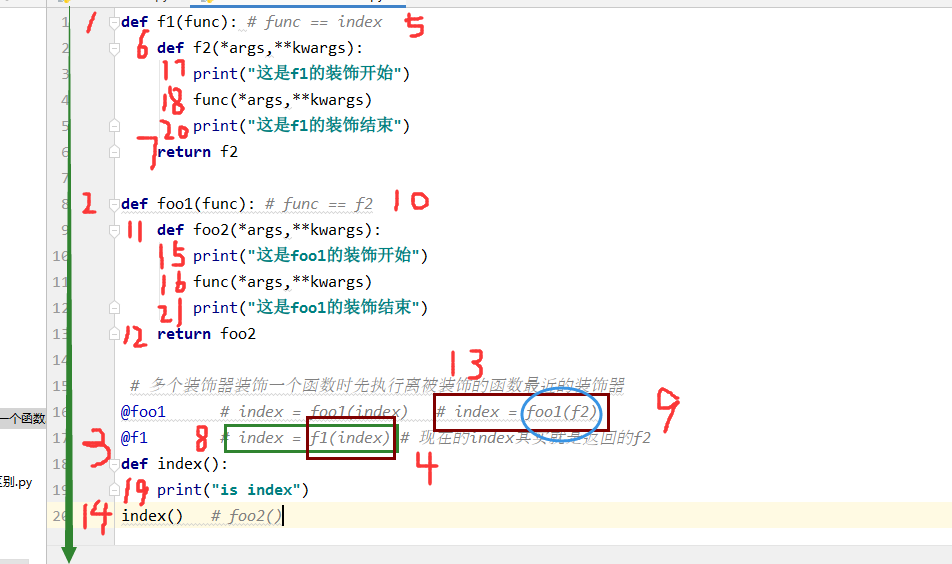
-
多个装饰器装饰一个函数时先执行离被装饰的函数最近的装饰器
-
实例
def f1(func): # func == index def f2(*args,**kwargs): print("这是f1的装饰开始") func(*args,**kwargs) print("这是f1的装饰结束") return f2 def foo1(func): # func == f2 def foo2(*args,**kwargs): print("这是foo1的装饰开始") func(*args,**kwargs) print("这是foo1的装饰结束") return foo2 @foo1 # index = foo1(index) # index = foo1(f2) @f1 # index = f1(index) # 现在的index其实就是返回的f2 def index(): print("is index") index() # foo2()
def f1(func): # func == index
def f2(*args,**kwargs):
print("sss")
func(*args,**kwargs)
print("stop")
return f2
def foo1(func): # func == f2
def foo2(*args,**kwargs):
print("good")
func(*args,**kwargs)
print("bbb")
return foo2
def ff(func):
def ff2():
print("is ff")
func()
print("ff is")
return ff2
@foo1
@ff
@f1
def f():
print("is f")
f()
>>>
good
is ff
sss
is f
stop
ff is
bbb

23.递归
-
定义:
- 不断地调用自己本身,##只满足这个条件的就是死递归
- 有明确的结束条件
-
递归最大深度:官方1000 实测994
-
阶乘5层
def jc(n): if n == 5: return 5 return jc(n+1) * n print(jc(1)) >>>> 120 -
斐波那契数列
lst = [1,1] for i in range(5): lst.append(lst[-1] + lst[-2]) print(lst) 函数: 还没做出来
24.函数:
def 函数名():
函数体
- 封装代码,减少重复的代码。
- 函数被调用后,函数体中开辟的空间会被自动销毁
- 函数名+括号(),有两个功能:第一个是调用函数,第二个是接受返回值
- 不管在什么位置,只要看到函数名+()就是调用函数
#return
- 在函数中遇到return直接结束函数
- 可以给函数的执行者返回任意数据类型
- 可以给函数的执行者返回多个数据类型(以元组形式接受)
- 函数体中不写return,默认返回None。写了return不写值,也是返回None
def func():
print(1)
func() >>>1 ##不打印函数,只执行函数,只会执行函数体
def func():
print(1) ##函数体中不写return,默认返回None
print(func())
>>>>1
None ##只有在print打印函数时,才会打印出None
#函数传参优先级
- 函数传参优先级:位置参数>*args(动态位置参数)>默认值参数>**kwargs(动态关键字参数)
#参数
-
形参 : 写在函数声明的位置的变量叫形参(在定义函数的阶段)
-
可以单独使用位置参数,也可单独使用默认参数,也可混合使用
-
位置参数:必须要一一对应
def yue(app,girl,age,addr): # 形参 print(f"打开{app}") print(f"找一位{girl},要求年龄:{age},地区:{addr}的人") yue("微信","女孩",18,"乌克兰") # 实参 按照位置传参 -
默认参数:可以不传,可以传,传的时候会将默认值覆盖
def userinfo(name,age,hobby,sex="男"): #sex就有默认值 print(f"姓名:{name} 年龄:{age} 性别:{sex} 爱好:{hobby}") userinfo("岳新力",23,"开车") -
动态位置参数(*args)
- 在函数定义阶段,*就是聚合
- 在函数体中,*就是打散list或tuple,**就是打散dict
- *args 程序员之间的约定俗称(可以更换,但不建议更换)
- 能够接受不固定长度的参数
- 位置参数过多时可以使用动态参数
- 获取到的是一个元组,没有值就是一个空元组
- 只接受多余的位置参数
def lst(a,b,c,*args,d=100,): #*args 此处的*是聚合 print(a,c,w,d) print( *args) #*args 此处的*是打散 print(args) lst(1,2,3,4,5,6,7) >>>>1 3 (4, 5, 6, 7) 100 >>>>4 5 6 7 (4 5 6 7) ####################################################################### def foo(a, b, args, c, sex=None, **kwargs): print(a,b,c) print(args) #此处的args前没有* 所有没有将列表打散 print(kwargs) #此处的kwargs前没有* 所有没有将字典打散 -
动态关键字参数(**kwargs)
-
在函数定义阶段,*就是聚合
- 在函数体中,**kwargs就是打散字典,获取到的是键
-
程序员之间的约定俗称(可以更好,但是不建议更换)
- 获取到的是一个字典,没有值时就是一个空字典
- 只接受多余的关键字参数
def func(**kwargs): # 万能传参 print(kwargs) func(c=22,a=1,b=2) >>>>{'c': 22, 'a': 1, 'b': 2} -
万能传参(面试必问)
def func(*args,**kwargs): # 万能传参 print(args,kwargs) func(12,2,121,12,321,3,a=1,b=2) >>>>(12, 2, 121, 12, 321, 3) {'a': 1, 'b': 2} ############################################################################### def foo(a, b, *args, c, sex=None, **kwargs): print(a,b,c) print(args) print(kwargs) print(*args) print(*kwargs) foo(*[1, 2, 3, 4],**{'name':'太白','c':12,'sex':'女'}) #*[]打散列表 **{}打散字典 >>> 1 2 12 (3, 4) {'name': '太白'} 3 4 name
-
-
实参:在函数调用的时候给函数传递的值(调用函数的阶段)
- 可以单独使用位置参数,也可单独使用关键字参数,也可混合使用
- 位置参数:必须要一一对应
- 关键字参数:指名道姓传参
- 混合参数:位置参数 > 默认参数
def yue(chat): # chat 形参 print("拿出手机") print("打开"+chat) yue("陌陌") # "陌陌"在这里就是实参
#注释
-
查看函数的注释
def add(a:int,b:int): # 提示(a:int)只是提示用户需要传参的类型,不是字典赋值 """ ####此处的注释必须都是三个双引号(三个单引号也可以) 加法 :param a: :param b: :return: """ return a + b print(add(1,2)) >>>>3 print(add("1","2")) >>>>12 print(add.__doc__) >>>> 加法 :param a: :param b: :return:
#函数的名称空间
-
名称空间
- 内置空间 #存放python自带的一些函数
- 全局空间 #当前python文件定格编写的代码开辟的空间
- 局部空间 #函数开辟的空间
-
程序的加载顺序
内置空间 > 全局空间 > 局部空间
-
程序的取值顺序
局部空间 > 全局空间 > 内置空间
#作用域
- 全局作用域: 包含内置命名空间和全局命名空间. 在整个文件的任何位置都可以使用(遵循 从上到下逐⾏执行).
- globals() 查看全局作用域:内置+全局
- 局部作用域: 在函数内部可以使用.
- locals() 查看当前作用域:建议查看局部作用域
def func():
a = 40
b = 20
print("哈哈")
print(a, b)
print(globals()) # 打印全局作用域中的内容
print(locals()) # 打印当前作用域中的内容
func()
>>>>
哈哈
40 20
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001D4A2DDF848>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'F:/学习/python-lch/python26期视频/day10/代码和笔记/06 函数的名称空间.py', '__cached__': None, 'a': 10, 'func': <function func at 0x000001D4A2E97288>}
{'a': 40, 'b': 20}
#函数名的第一类对象及使用
-
函数名可以当做值,赋值给一个变量
def func(): print(1) a = func print(func) >>>> # 打印函数的内存地址 print(a) #打印函数的内存地址 a() #执行func函数 >>>><function func at 0x0000021BB93B7318> >>>><function func at 0x0000021BB93B7318> >>>>1 -
函数名可以当做另一个函数的参数来使用
def func(): print(1) def foo(a): # a = func print(a) # func这个函数的内存地址 foo(func) #此处函数foo的参数是func不是func() >>>><function func at 0x0000026EC54673A8>def func(): ###被执行,打印一个1 print(1) def foo(a): ##a = func(), return None print(a) ##将None打印出来 foo(func()) #此处函数foo的参数是func不是func() >>>>1 None -
函数名可以当做另一个函数的返回值
-
函数名可以当做元素存储在容器中
def login(): print("登录") def register(): print("注册") msg =""" 1.注册 2.登录 请输入您要选择的序号: """ func_dic = {"1":register,"2":login} while True: choose = input(msg) # "5" if choose in func_dic: func_dic[choose]() else: print("滚")
#函数的嵌套
- 交叉嵌套
def func():
foo()
def foo():
print(111)
func()
- 嵌套
def func(a,b): #a = 4 b = 7
def foo(b,a): #b = 4 a = 7
print(b,a) #4 7
return foo(a,b) #先执行函数调用 a = 4 b= 7
# return None
a = func(4,7)
print(a)
>>>4 7
>>>None
- global
- 只修改全局空间中的变量
- 在局部空间中可以使用全局中的变量,但是不能修改,如果要是要强制修改需要添加global
- 当变量在全局中存在时,global就是申明我要修改全局的变量,并且会在全局修改这个变量
- 当变量在全局中不存在时,global就是申明要在全局中创建一个变量,并且会在全局修改这个变量
- nolocal
- 只修改局部空间中的变量,最外层的一个函数
- 只修改离nonlocal最近的的一层,如果这一层没有就继续往上一层进行查找,只能在局部
- nonlocal不能创建变量
25.匿名函数
-
匿名函数的名字叫做lambda
-
匿名函数的编写格式
f = lambda a,b:a+b print(f(1,2)) >>>3 #################### def num(): return [lambda x:i * x for i in [1,2]] a= num() print(a) >>>获取到三个内存地址print((lambda a,b:a+b)(1,2)) #lambda和def是一样的 #a,b和(a,b)是一样的 代表形参 #: a+b 和 return a+b 是一样的 代表返回值 # 形参: 可以接受位置参数,动态位置,默认,动态关键,可以不写 # :返回值 只能返回一个数据,必须写 f = lambda x,y:(x,y,x+y) print(f.__name__) >>><lambda> print(f(1,2)) >>>(1,2,3) -
例子
-
算数
def square(x) : # 计算平方数 return x ** 2 map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 [1, 4, 9, 16, 25] >>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25]
-
-
字典
func = lambda a,b,*args,sex= 'alex',c,**kwargs: kwargs print(func(3, 4,c=666,name='alex')) >>>{'name': 'alex'} -
索引
func = lambda x:(x[0],x[3]) print(func('afafasd')) >>>('a', 'f')-
比较大小
func = lambda x,y: x if x > y else y print(func(3,100)) >>>100
-
###匿名函数题##
def num():
return [lambda x:i*x for i in range(3)] # [func,func,func]
print([m(3) for m in num()])
def num():
lst = []
for i in range(3)
def func(x):
return i*x
lst.append(func)
return lst
new_list = []
for m in num():
new_list.append(m(3))
print(new_list)


26.软件开发规范
- 各个文件夹
- bin ----启动文件
- lib ----公共组件
- core ----主逻辑
- db ----存储数据
- log ---记录日志
- conf ---配置文件
27.log日志
- 记录程序的运行状态
- 记录用户的操作
#日志的级别
- debug调试 --10
- info 信息 --20
- warning警告 --30
- error 错误 --40
- srirical 危险 --50
#日志文件写入
import logging
logger = logging.getLogger()
#创建一个空架子
fh = logging.FileHandler("test.log",mode = "a",encoding = "utf-8")
#创建一个文件句柄,用来记录日志
ch = logging.StreamHandler()
#创建一个屏幕流,打印记录的内容
f_str = logging.Formatter("%(asctime)s %(name)s %(levelname)s %(filename)s %(lineno)s %(message)s")
##d定义一个记录日志的格式
logger.level = 10 #设置一个记录级别
fh.setFormatter(f_str) #给文件句柄设置记录的格式
ch.setFormatter(f_str) #给中控台设置打印内容的格式
logger.addHandler(fh) #将文件句柄添加logger对象中
logger.addHandler(ch) #将中控台添加的logger对象中
logger.debug(1234)
logger.info(1234)
logger.warning(1234)
logger.error(1234)
logger.critical(1234)
28.包
- 具有—init—.py文件的文件夹就是一个包,目的就是管理模块
- 包的本质就是一个模块,模块可以导入,包也可以导入
Python2中,使用import一个包时,包中没有--init--.py报错
Python3中,使用import一个包时,包中没有--init--.py不报错
- 导入时,发现使用.(点)的操作就是导入包
- 导入前.(点)前面必须是一包
#路径
- 绝对路径:从最没外层的开始查找
- 相对路径:取决于在哪个文件中启动
#import 包.包.模块
-
import bake.api.versions ##bake是包 api也是包 version是模块

#起别名
-
import bake1.api.versions as v
#from 包.包.模块 import 函数,变量,*
29垃圾回收机制
- 概述:python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
- 引用计数:
- 每当新的引用指向该对象时,引用计数加1,当对该对象的引用失效时,引用计数减1,当对象的引用计数为0时,对象被回收。缺点是,需要额外的空间来维护引用计数,并且无法解决对象的循环引用。
- 分代回收:
-
- 以时间换空间的回收方式
- 分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
- 同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
- 标记清除:
- 活动对象会被打上标记,会把那些没有被打上标记的非活动对象进行回收。
30什么是断言
- assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。
- 应用场景:
- 防御型编程
- 运行时检查程序逻辑
- 检查约定
- 程序常量
- 检查文档