欢迎转载,转载请附原文地址:
http://www.cnblogs.com/NeighborhoodGuo/p/4684041.html
又到了,博客时间,咳咳咳
这次lecture7的内容不太多。不过讲解的东西却是很高大上也很重要。
这次的课程主要就是在开头介绍了一下传统的语言模型,然后在后半段介绍了一个高大上的用RNN进行自然语言处理的思路。
推荐阅读里的论文也是对lecture7课上内容的补充说明,也十分棒。
废话不多说开写喽!
1.Traditional Language Models
首先,什么事语言模型呢?语言模型就是计算一串单词是否是“合理”、“正确”的一串单词的概率。
这个东东很有用哦。1.在机器翻译方面,我们都知道不同语言的语序可能会不一样,日本人说中文常常会说成“你的什么的干活”这种形式。这就犯了一个使用日语语法,但是使用中文单词的错误。2.在单词的选择方面也很有用处,还是上一个例子“你的什么的干活”如果地道的中国人说应该是“你是做什么的”。如果语言模型合理的话P("你的什么的干活")会小于P(“你是做什么的”),以上两个就是LM的最广泛的用处。
那么以上的那个一串单词的概率该怎么计算呢?我们做了一个不正确的Markov assumption。在实际中,某个单词出现的概率应当取决于它之前的所有的单词,还是举上面日本人说中文的例子:“什么的”出现的概率应该取决于“你”“是”“做”这三个单词。现在做一个Markov assumption只基于之前某几个单词。这种模型常用的是unigrams和bigrams也就是只基于之前的一个或者两个单词。很显然这种方法会丢失很多信息,使用更多的之前的单词就会提高性能,但是目前的计算机还没有这么强大- -。
2.RNNs
这时候RNN就闪亮登场啦!
RNN模型里每个time step之间的weight都是相等的。
还有一个特牛X的特性就是,不像之前的TLM现在的RNN condition on all previous words,对你没有看错!还有一个就是他对RAM的要求仅仅和这一串单词的数量相关。好牛掰哦!
下面是RNN的核心公式和图形表示:
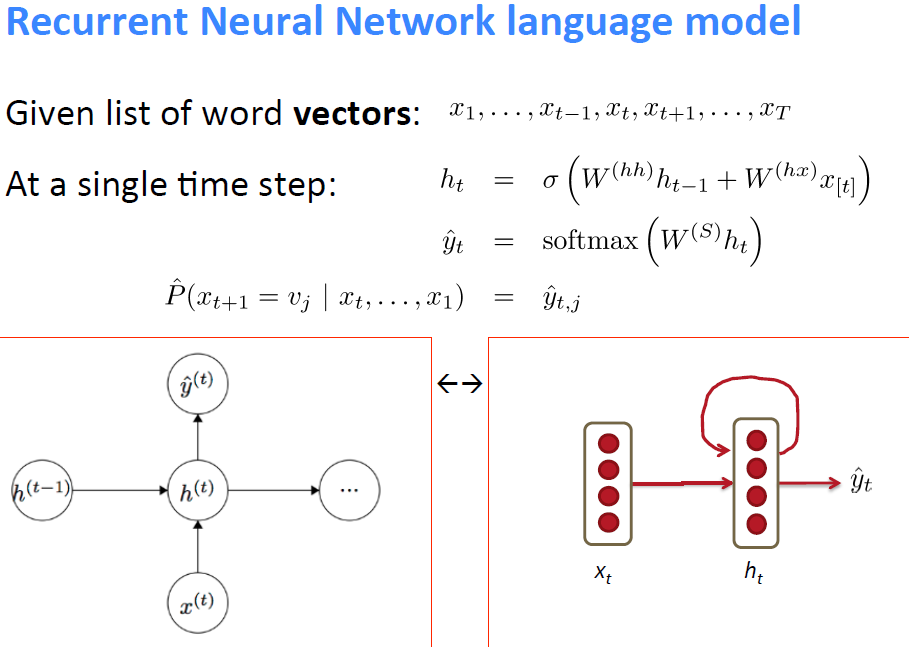
最后算loss function的方法还是俺们最常用的cross entropy loss function
这个模型虽然很好,但是训练起来很hard
原因是NN的固有问题vanishing/exploding gradient problem这两个问题随着NN的depth的增加还凸显的很严重。
1.vanishing gradient solution
第一个方法把所有weight都初始化为identity matrix,第二个方法就是把activation function换成Relu units
2.exploding gradient solution
课上只介绍了一种方法:clipping trick
以下是pseudo-code:

一旦超过threshold就clip
threshold一般选择范围是3~5
课上介绍了一种简单的优化这种model的方法,由于softmax计算起来很慢,怎么办呢?可以在word和预测的history之间增添一个class
class的数目肯定就比vocabulary的数目小很多了。然后在算p(w_t | c_t)这样就能在不显著降低performance的情况下大幅度提高运算速度
3.扩展内容
课程最后的结尾阶段讲了一个opinion mining with deep recurrent nets还有几个RNN的varients
opinion mining简单的说就是从别人的话里推断出说话的意图。而语言的表达里有direct subjective expressions(DSEs)还有expressive subjective experssions(ESEs)用一个段子做例子:
1:汉语八级考试: 领导:你这是什么意思? ---就是问小明这是想干什么?
2:小明:没什么意思,意思意思。---就是小明不干什么,给领导送点红包;
3:领导:你这就不够意思了。---就是 领导认为小明的红包太少;
4:小明:小意思,小意思。---第一个小意思是小明想明白了,说 小case;第二个小意思是小明拿出更大的红包送给领导;
5:领导:你这人真有意思。---就是领导夸奖小明懂事;
6:小明:其实也没有别的意思。---就是小明想让领导给他行点方便;
7:领导:那我就不好意思了。---就是领导收下红包的谦虚表达词;
8:小明:是我不好意思。 ---就是小明送了红包后的谦虚表达词
左半部分就是ESEs(- -)
右半部分差不多就是DSEs(- -)
如果用计算机处理上文的话(估计计算机也会疯了),简单的办法可以用BIO notation来标注每一个单词。
实现的时候使用了RNN,Bidirectional RNNs, Deep Bidirectional RNNs
论文里面的测试结果是使用Deep Bidirectional RNNs效果更好。
以下是几个模型的核心公式和figure
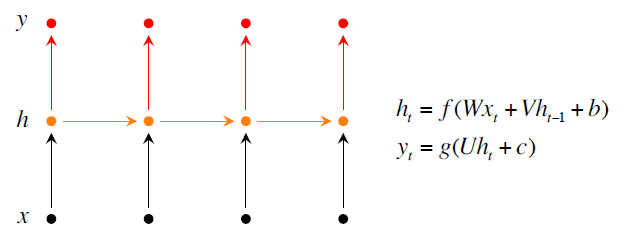
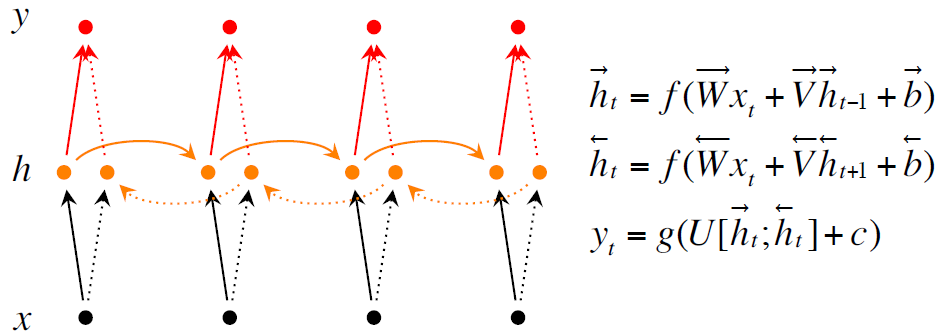
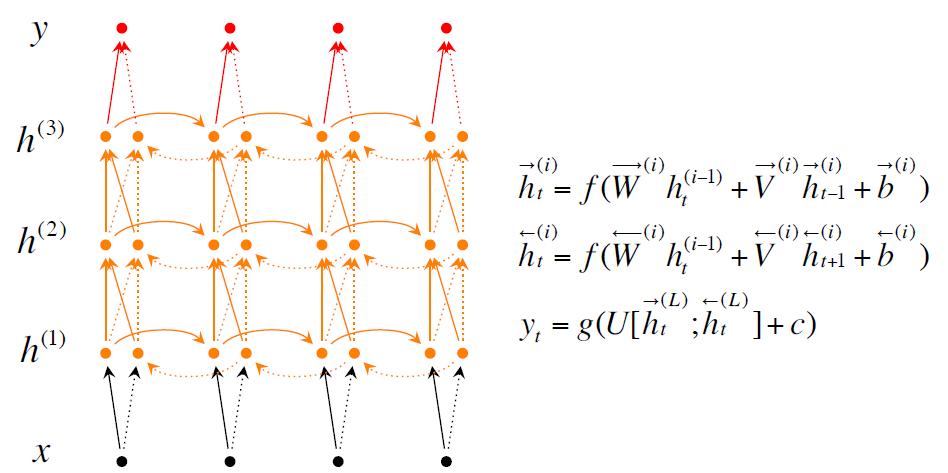
最后给出了F1的计算公式:
F1 = 2 * precision * recall / (precision + recall)