欢迎转载,转载注明出处:
http://www.cnblogs.com/NeighborhoodGuo/p/4725192.html
这一讲还是嘉宾的讲课,讲得是关于parallel计算方面的。俗话说的好:“三个臭皮匠,顶个诸葛亮嘛”。哈哈
因为一台计算机,或者一个处理器的处理能力是有限的,进行并行计算能够大大提高运算速度,节省调试的时间。而我们的NN是如此的复杂,有时候规模也特别大,所以使用并行计算是很有必要的。
这一讲呢,主要分为五个部分:1.Efficient formulations 2.CPUs and GPUs 3.Parallelism 4.Asynchronous SGD 5.Easy implementations and Current research
Efficient formulations
Structured VS unstructured computation
structured graph就是指各个units之间的连接都很规矩比如说CNN
这种规矩的表示方法的好处是:cache的使用都是连续的,很容易load,对内存的使用也很少。缺点就是灵活性不好
还有一种就是unstructured graph
好处是表达能力更强,但是cache的使用不连续,不容易load,对内存使用偏高(和之前的对立)
我们的目标就是在不影响性能的前提下,使表达更加structured
Block operations and BLAS
Block operations一个最简单的例子就是矩阵乘法和加法,也就类似把相似的运算打包成一整块,然后输入进去批量计算。
BLAS: Basic Linear Algebra Subroutines是一款很先进的并行计算工具,课上还推荐了其他很棒的并行计算工具。

Batching
就是之前说的Batching gradient descent就不赘述了。
CPUs and GPUs
课上讲师说CPU和GPU已经达到了peak performance。
内存的大小很受限,CPU和GPU的通讯很慢是一个瓶颈。
CPU更少的cores 每个core运算速度更快
GPU更多的cores 每个core运算速度慢
但是GPU有数量优势,整体来说GPU运算速度比CPU快
乍一看貌似完全使用GPU更好,其实不然。
由于有通讯瓶颈,在计算量较小的时候使用CPU其实更有计算优势,在计算数量较多的时候使用GPU才有明显的优势。

Data parallelism
这个就是用来优化之前的Batching gradient descent
1.先指定一个master core然后多个worker core,首先master给每个worker分配计算的任务
2.然后每个worker core各自分别计算
3.计算完成后汇总到master那里,由master汇总计算出最终结果
这里的parallelism是同步的。
Model parallelism
这个就是把model进行分块然后各个模块分别分配给各个core计算然后汇总结果。

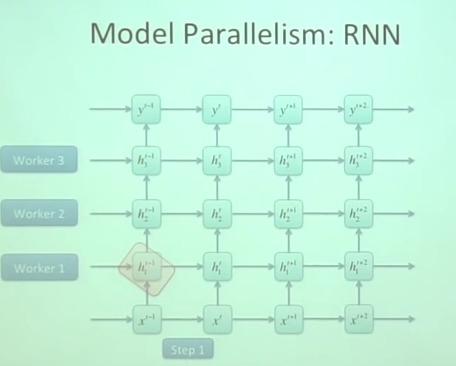
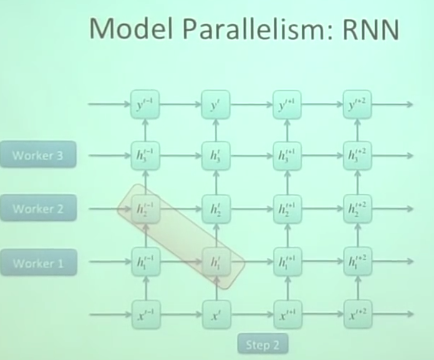

一台计算机的计算能力怎么说都是有限的,能不能使用多台计算机同时帮助计算呢?
但是计算机之间的以太网通信速度太慢了,开发更快速的计算机间通信才行。
Asynchronous SGD
前面说得同步的计算方法需要等待每个work core都计算完成才能汇总计算出结果,这样就会使一部分时间消耗在等待上面。
鉴于此就提出了异步的SGD

分配任务还是照常分配,但是谁计算完成谁就上传计算结果给master,然后master汇总完成之后立即给每个work core更新数据

Research directions
有三个可以改进的地方:
1.修改model尽量减少unstructured的部分,增加structured的部分;尽量增加model的宽度,降低深度
2.尽量使得Neural不饱和,使数据尽可能的在线性区。
3.找到更好的优化方法。

几个开源的Parallelism Packages
1.BLAS
2.CPUs: Intel MKL, Atlas, GOTO
GPUs: Cuda, OpenAcc, clBLAS
3.Theano, Torch