目录结构
1.Hadoop概述
1.1 Hadoop简介
1.2 Hadoop发展史
1.3 Hadoop特点
2.Hadoop核心
2.1 分布式文件系统——HDFS
2.2 分布式计算框架——MapReduce
2.3 集群资源管理器——YARN
3.Hadoop生态系统
4.Hadoop应用场景
5.小结
一、Hadoop介绍
1.Hadoop概述
两大核心:HDFS和MapReduce
用于资源与任务调度的框架:YARN
1.1 Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。它的目的是从单一的服务器扩展到成千上万的机器,将集群部署在多台机器,每个机器提供本地计算和存储,并且将存储的数据备份在多个节点,由此提高集群的可用性,而不是通过硬件的提升,当一台机器宕机时,其他节点仍可以提供备份数据和计算服务,Hadoop框架最核心的设计是HDFS和MapReduce。
1.2 Hadoop发展史(转自百度百科)
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop 最初只与网页索引有关,迅速发展成为分析大数据的领先平台。
目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估的软件。
1.3 Hadoop的特点
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。其优点主要有以下几个:
(1)高可靠性:因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
(2)高扩展性:集群内可以很容易地进行节点扩展,扩大集群。
(3)高效性:Hadoop是在节点之间动态地移动数据,在数据所在节点进行并发处理,并保证各个节点的动态平衡,因此处理速的非常快。
(4)高容错性:HDFS在存储文件时会在多个节点或者多台机器上存储文件的备份副本,保证程序顺利运行。如果启动的任务失败,Hadoop会重新运行该任务或启用其他任务来完成这个任务没有完成的部分。
(5)低成本:Hadoop是开源的。
(6)可构建在廉价机器上,Hadoop的基本框架是用java编写的。
2.Hadoop核心
2.1 分布式文件系统——HDFS(Hadoop Distributed File System)
2.1.1 HDFS架构及简介
HDFS是以分布式进行存储的文件系统,主要负责集群数据的存储和读取。HDFS是一个主/从(master/slave)体系结构的分布式文件系统。HDFS支持传统的层次型文件组织结构,用户或者应用程序可以创建目录,然后将文件保存在这些目录里,可以通过文件路径对文件执行创建、读取、更新、删除等操作。但是由于分布式存储的性质,他有和传统的文件系统有明显的区别。
HDFS基本架构图:
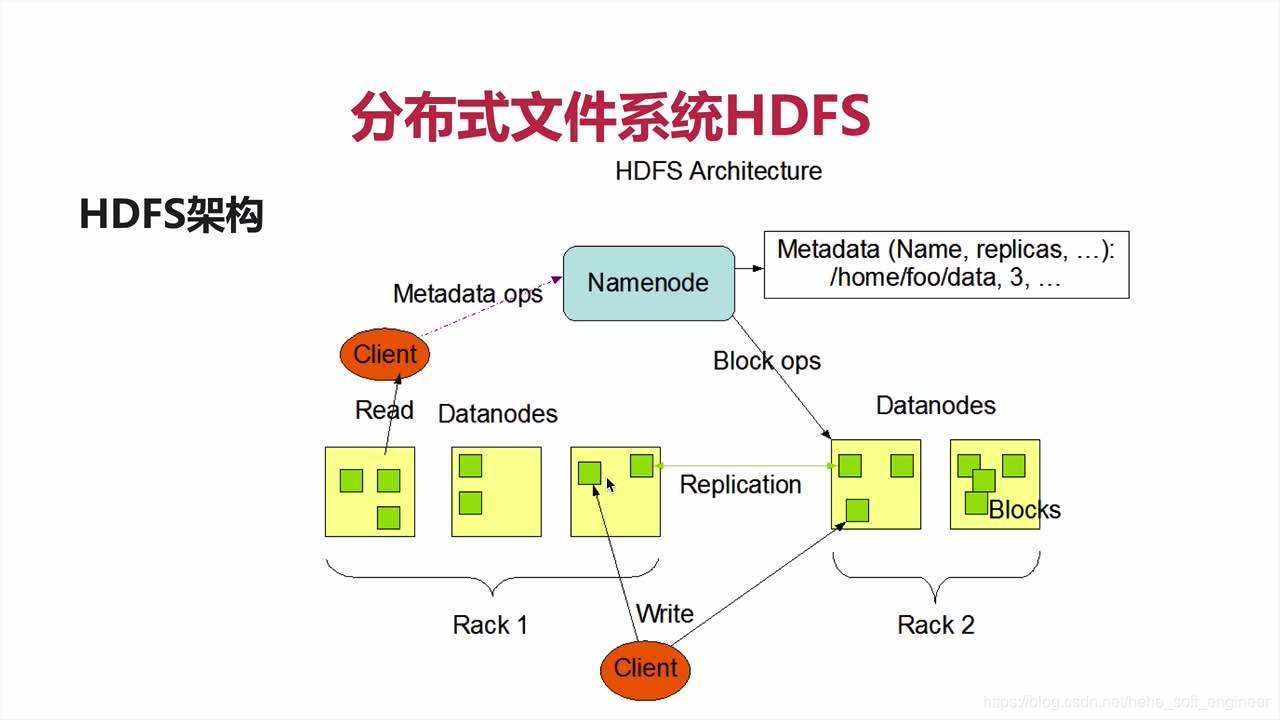
HDFS文件系统主要包括一个NameNode、一个Secondary NameNode和多个DataNode。
(1)元数据(metadata)
元数据不是具体的文件内容,有三部分重要信息:①文件和目录自身的属性信息,如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等;②记录文件内容存储的相关信息,例如文件分块情况、副本个数、每个副本所在的DataNode信息等;③用来记录HDFS中所有的DataNode的信息,用于管理DataNode
(2)NameNode
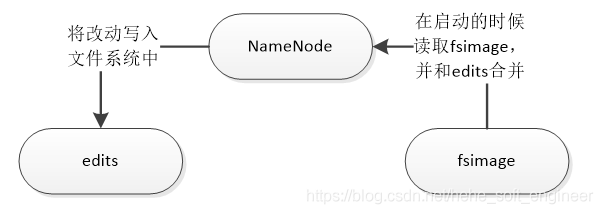
NameNode用于存储元数据以及处理客户端发出的请求。在NameNode中存放元信息的文件是fsimage文件。在系统运行期间,所有对元数据的操作都会保存在内存中,并且被持久化存储在另一个文件edits(日志)中,当NameNode启动时,fsimage会被加载到内存,然后对内存里的数据执行edits所记录的操作,以确保内存所保留的数据处于最新状态。
(3)Secondary NameNode
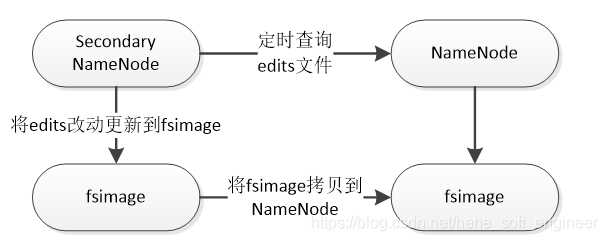
Secondary NameNode用于备份NameNode的数据,周期性将edits文件合并到fsimage文件并在本地本分,将新的fsimage文件存储到NameNode,取代原来的fsimage,删除edits文件。创建一个新的edits继续存储文件的修改操作和状态。
(4)DataNode
DataNode是真正存储数据的地方。在DataNode中,文件以数据块的形式进行存储。当文件传到HDFS端以128MB的数据块将文件进行切割,将每个数据块存到不同的或者相同的DataNode并且备份副本,一般默认3个,NameNode会负责记录文件的分块信息,确保在读取文件时可以找到并整合整个块。
(5)数据块(block)
文件在上传到HDFS时根据系统默认文件块大小把文件分成一个个数据块。Hadoop 2.x 默认128MB为一个数据块,比如存储大小为129MB的文件,则被分为两个块来存储。数据块会被存储到各个节点,每个数据块都会备份副本。
2.1.2 HDFS分布式原理
什么是分布式系统?分布式系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能。利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统。
分布式文件系统是分布式系统的一个子集,其解决的问题就是数据存储。换句话说,它是横跨在多台计算机上的存储系统。存储在分布式文件上的数据自动分布在不同的节点上。
HDFS作为分布式文件系统,主要体现在以下三个方面:
(1)HDFS并不是一个单机文件系统,它是分布在多个集群节点上的文件系统。节点之间通过网络通信进行协作,提供多个节点的文件信息,让每个用户都可以看到文件系统的文件。让多台机器上的多用户分享文件和存储空间。
(2)文件存储时被分布在多个节点上,这里涉及一个数据块的概念,数据存储不是按一个文件存储的,而是把一个文件分成一个或多个数据块存储。数据块存储时并不是都存储在一个节点上,而是被分布存储在各个节点上,并且数据块会在其他节点上存储副本。
(3)数据从多个节点读取。读取一个文件时,从多个节点中找到该文件的数据块,分布读取所有数据块,直到最后一个数据块读取完毕。
2.1.3 HDFS宕机处理
数据存储在文件系统中,如果某个节点宕机了,就很容易造成数据流失,HDFS针对这个问题提供了保护措施:
(1)冗余备份
数据存储过程中对每个数据块都做了冗余处理,副本个数可以自行设置。
(2)副本存放
使用的策略:以dfs.replication为例,在同一个机器的两个节点上各备份一个副本,然后在另一个机器的某个节点上再放一个副本,前者是为了防止节点宕机,后者则是为了防止整个机器宕机而使数据丢失。
(3)宕机处理
①DataNode会周期性地发送心跳信息给NameNode(默认3s一次)。如果NameNode在预定时间内没有收到心跳信息(默认10min),他会认为DataNode出问题了,把他从集群中移除。然后HDFS会检测到硬盘上的数据块副本数量低于要求,然后对副本数量不符合要求的数据块创建需要的副本,以达到预设的要求。DataNode可能会因为硬件故障、主板故障、电源老化和网络故障等问题脱离集群。
②当HDFS读取某个数据块时,如果该节点正处于宕机,客户端就会到存储该数据块的其他节点读取,HDFS也会检测到数据块副本个数不符合要求而重新补全副本。
③当HDFS存储数据时,如果要存放的节点宕机,HDFS会重新分配一个节点给数据块,然后备份宕机节点的数据。
2.1.4 HDFS的特点
(1)优点:
高容错性、适合大数据的处理、流式数据访问(一次写入,多次读取;文件一旦写入,不能修改,只能增加,这样可以保证数据的一致性)
(2)缺点:
不适合低延迟数据的访问、无法高效存储大量小文件、不支持多用户写入以及任意修改文件(写操作只能在文件末尾完成,只能执行追加操作)
2.2 分布式计算框架——MapReduce
2.2.1 MapReduce简介
MapReduce是Hadoop的核心计算框架,是用于大规模数据集(大于1TB)并行计算的编程模型,主要包括Map(映射)和Reduce(归约)两部分。当启动一个MapReduce任务时,Map端会读取HDFS上的数据,将数据映射成所需要的键值对类型并传到Reduce端。Reduce端会接收Map端传过来的键值对类型的数据,根据不同的分组,对每一组键相同的数据进行处理,得到新的键值对并输出到HDFS,这就是MapReduce的核心思想。
2.2.2 MapReduce工作原理
(1)MapReduce执行流程(输入、切片、Map阶段数据处理、Reduce阶段数据处理、数据输出等阶段)
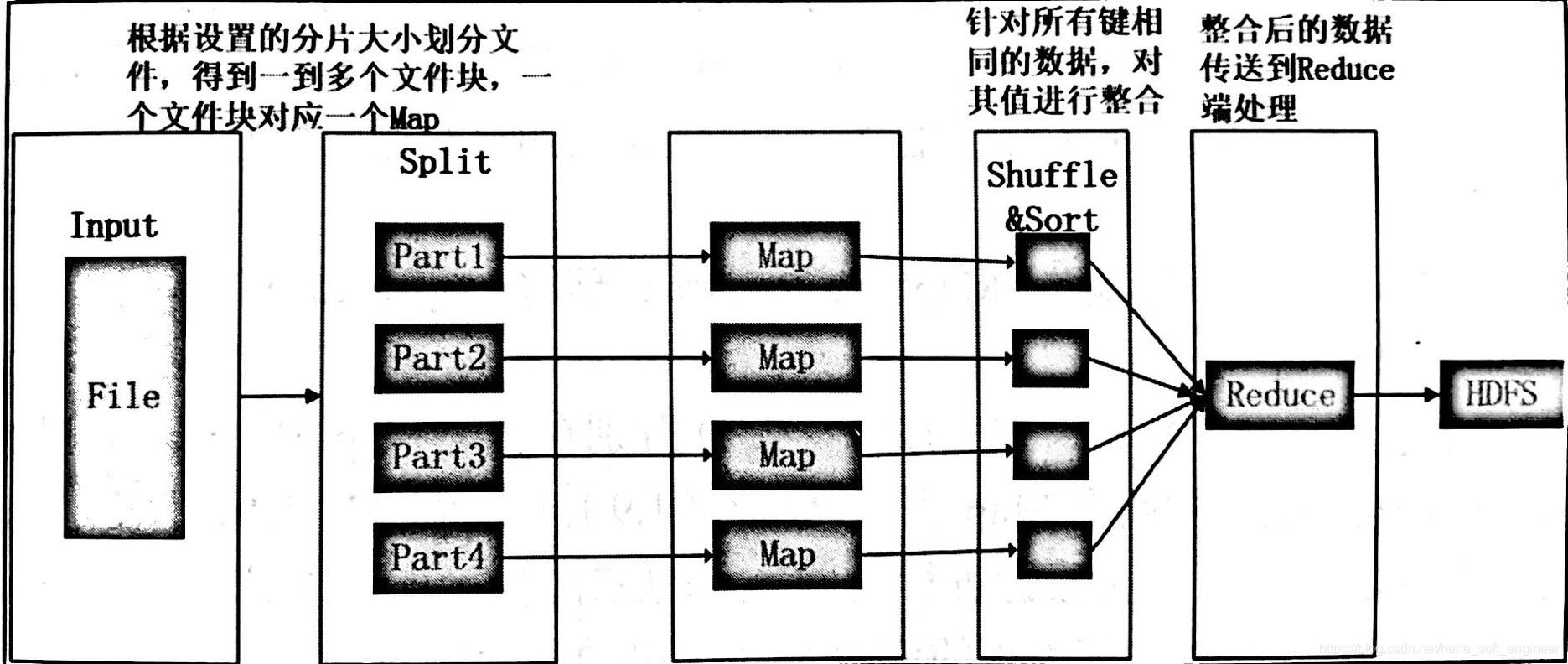
着重说一下Reduce阶段:Reduce任务也可以有多个,按照Map阶段设置的数据分区决定(数据划分的键的种类),一个分区数据被一个Reduce处理。针对每一个Reduce任务,Reduce会接收到不同的Map任务传来的数据,并且每一个Map传来的数据都是有序的。一个Reduce任务的每一次处理都是针对所有键相同的数据,对数据进行归约,以新的键值对输出到HDFS。
(2)MapReduce的本质:
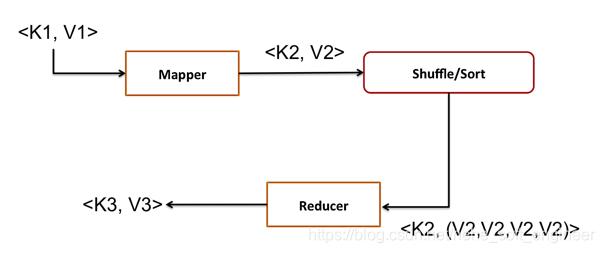
(3)帮助理解map和reduce过程的小例子:

2.3 集群资源管理器——YARN
2.3.1 YARN简介
YARN提供了一个更加通用的资源管理和分布式应用框架,目的是使得Hadoop的数据处理能力更强。在这个框架上,用户可以根据自己的需求实现定制化的数据处理应用。MapReduce也是YARN上的一个应用。YARN的另一个目标是拓展Hadoop,使得它不仅支持MapReduce计算,还能方便的管理如Hive、HBase、Pig、Spark等应用。通过YARN,各种应用就可以互不干扰地运行在同一个Hadoop系统中,共享整个集群资源。
2.3.2 YARN的基本架构和任务流程
(1)YARN的基本组成结构
总体上,YARN还是Master/Slave结构,ResourceManager为Mater,NodeManager是Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用于跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此他们之间不会互相影响(即可以并发执行一些应用)。
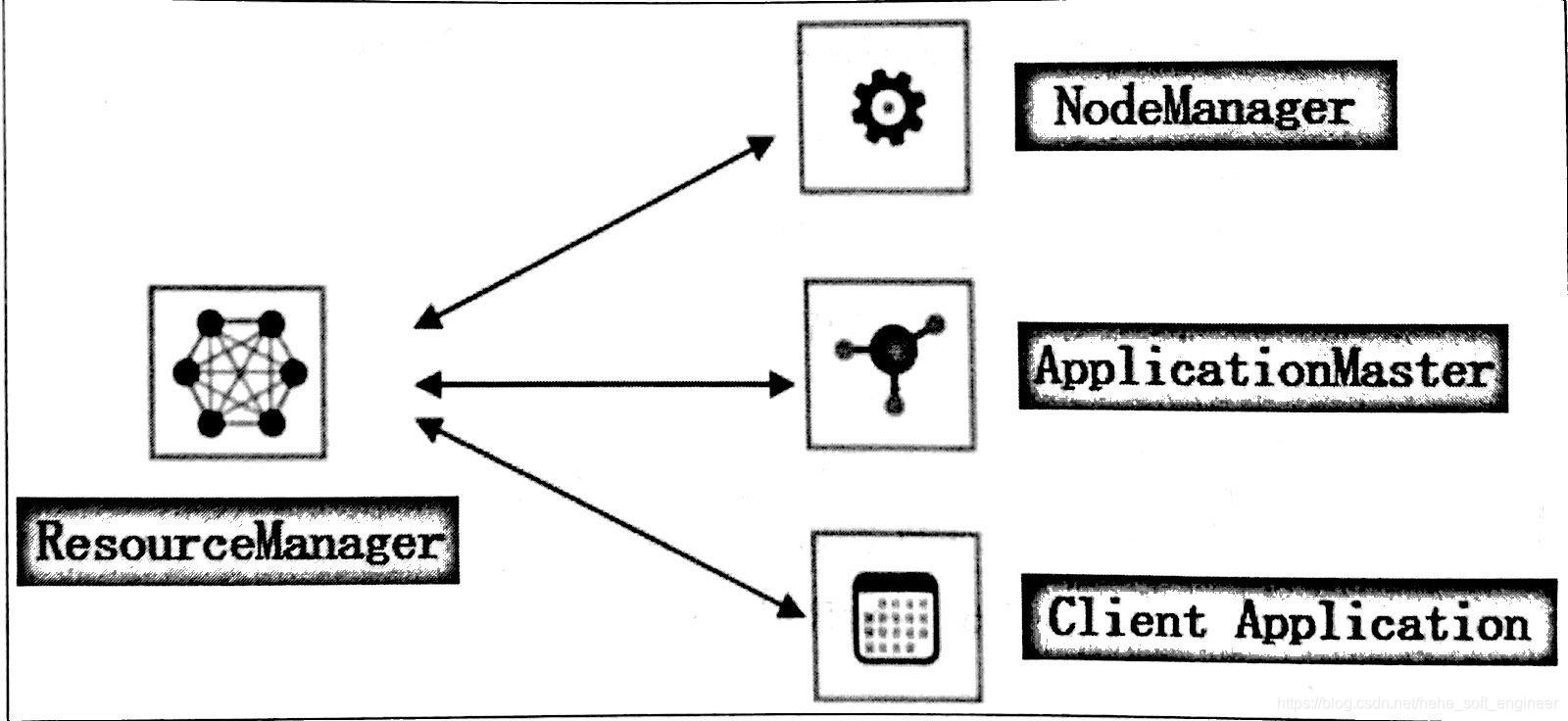
①RM(ResourceManager):由两个组件构成(调度器,scheduler;应用程序管理器 ASM)
ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
调度器负责给正在运行的应用程序分配资源,它不从事任何与具体应用程序相关的工作。
ASM负责处理客户端提交的job以及协商第一个Container(包装资源的对象)以供ApplicationMaster运行,并且在ApplicationMaster失败的时候将其重新启动。
②NM(NodeManager):
是每个节点上的资源和任务管理器。一方面,他会定时地向RM节点汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自ApplicationMaster的Container启动/停止等请求。
container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当ApplicationMaster向RM请求资源时,RM返回的资源便是用Container封装的。YARN为每一个任务分配一个Container,且该任务只能使用该Container中描述的资源。
③AM(ApplicationMaster):相当于给一个应用配置了一个小管家
在用户提交的每个应用程序时,系统都会生成一个AM并包含到提交的程序里,主要功能有:与RM中的调度器协商以获取资源(用Container表示);将得到的任务进一步细分给内部的程序;与NM通信以启动/停止服务;监控所有任务的运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
④CA(Client Application):客户端应用程序
客户端将应用程序提交到RM,首先会创建一个Application上下文件对象,并设置AM必需的资源请求信息,然后提交到RM。
(2)YARN的工作流程
详细描述YARN从提交任务到完成任务的整个工作流程:
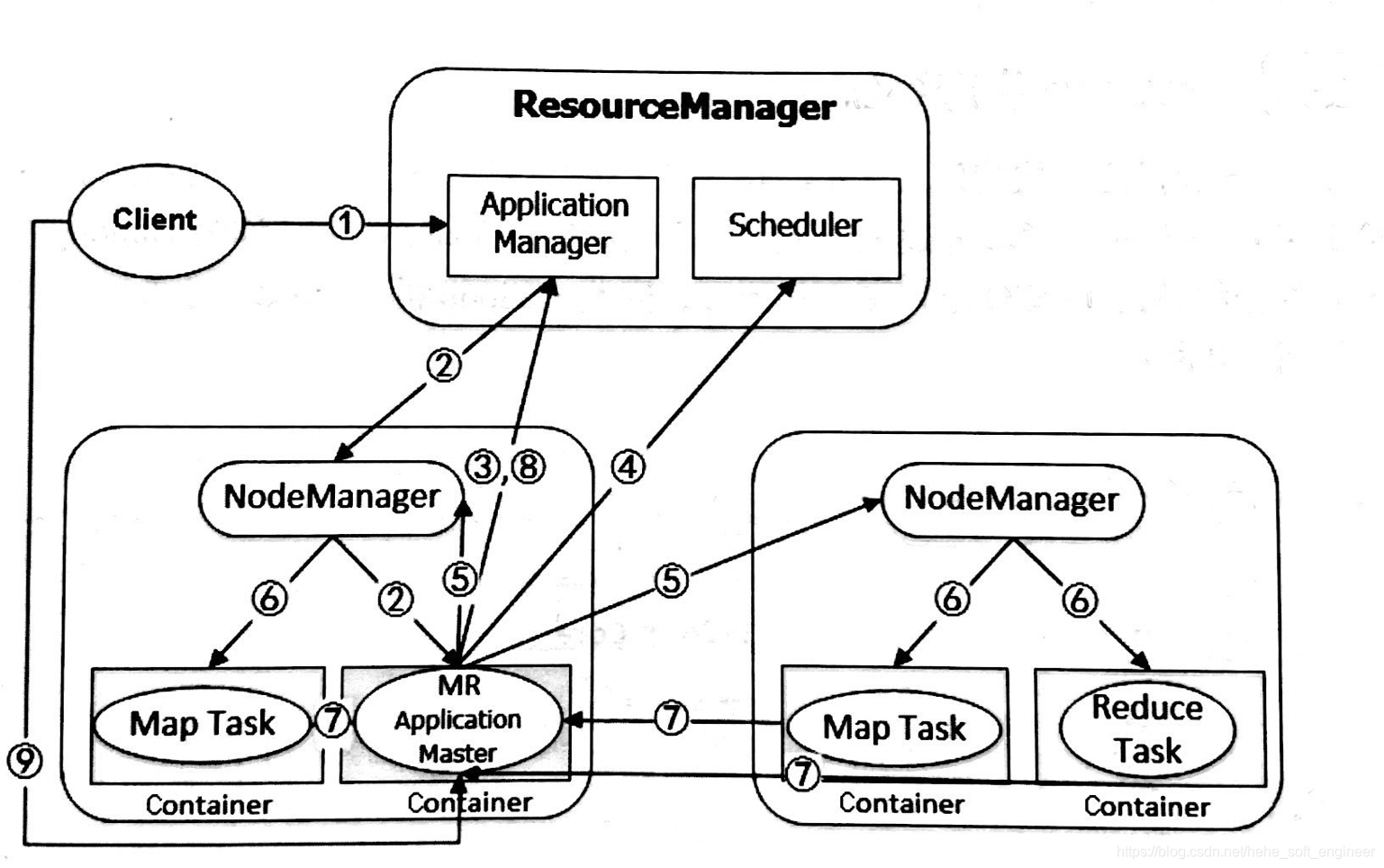
①用户通过Client提交一个应用程序到YARN进行处理,其中包括AM程序、启动AM的命令、用户程序等。
②RM为该应用程序分配第一个Container,并与分配的Container所在位置的NodeManager进行通信,要求它在这个Container中启动应用程序的AM。该Container用于启动AM和AM后续命令。
③AM启动后先向RM注册,这样用户可以直接通过RM查看应用程序的运行状态,然后开始为提交的应用程序所需要执行的各个任务申请资源,并监控它的运行状态,知道运行结束。(即重复执行④——⑦)
④AM采用轮流询问的方式通过RPC协议向RM申请和领取资源,并监控它的运行状态,所以多个应用程序提交时,不一定是第一个先执行。
⑤一旦AM申请到资源,便与资源对应的NM通信,要求它在分配的资源中启动任务。
⑥NM为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
⑦被启动的任务开始执行,各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可以随时通过RPC向AM查询应用程序的当前运行状态。
⑧应用程序运行完成后,ApplicationMaster向RM注销自己。
⑨关闭客户端和AM。
3.Hadoop生态系统
Hadoop面世之后,相继开发出了很多组件,这些组件共同提供服务给Hadoop相关工程,并逐步形成了系列化的组件系统,称为Hadoop生态系统
(1)HBase
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储
(2)Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
(3)Pig
Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
(4)Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。

(5)Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
(6)Oozie
Oozie是基于hadoop的调度器,以xml的形式写调度流程,可以调度mr,pig,hive,shell,jar任务等等。
主要的功能有
* Workflow: 顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)
* Coordinator,定时触发workflow
* Bundle Job,绑定多个coordinator
(7)ZooKeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。

(8)Mahout
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
4.Hadoop应用场景
十大应用场景:(1) 在线旅游 (2) 移动数据 (3) 电子商务 (4) 图像处理 (5) 能源开采
(6) 诈骗检测 (7) IT安全 (8) 医疗保健 (9) 搜索引擎 (10) 社交平台
5.小结
本文从理论方面介绍了Hadoop的基本概念、Hadoop的特点,了解了Hadoop的核心思想;了解了HDFS、MapReduce、YARN三大主要的核心框架,深入了解了Hadoop的整体结构;简单地了解了Hadoop的生态系统和一些应用场景。
6.参考
本文主要参考《Hadoop大数据开发基础》一书,作者余明辉、张良钧