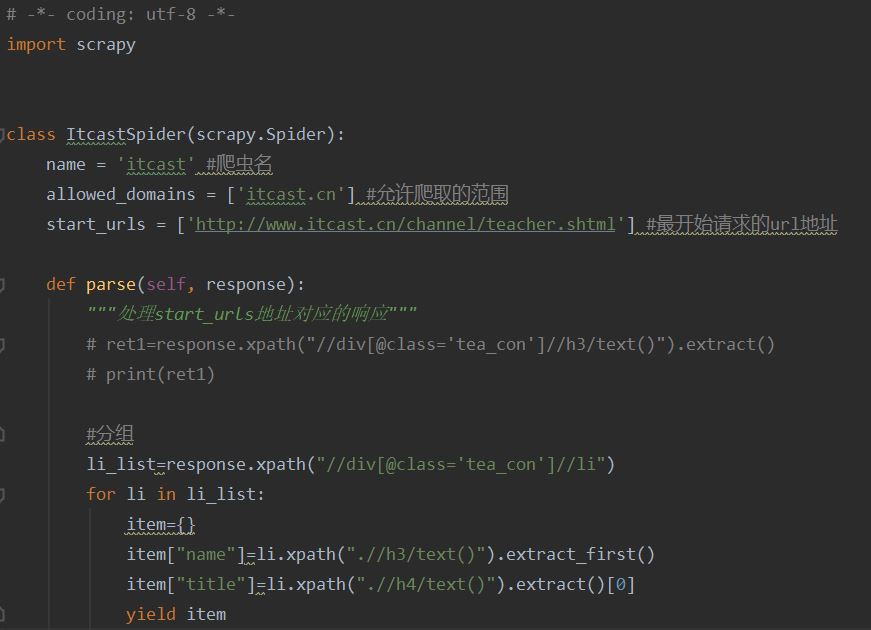
在Pycharm中新建一个基于Scrapy框架的爬虫项目(Scrapy库已经导入)
在终端中输入:

''itcast.cn''是为爬虫限定爬取范围
创建完成后的目录
将生成的itcast.py文件移动到spiders文件夹
在setting.py文件中添加: LOG_LEVEL = 'WARNING' 来限定日志
运行爬虫项目:
1.在终端中将路径移动到mySpider目录
2.终端输入 scrapy crawl itcast
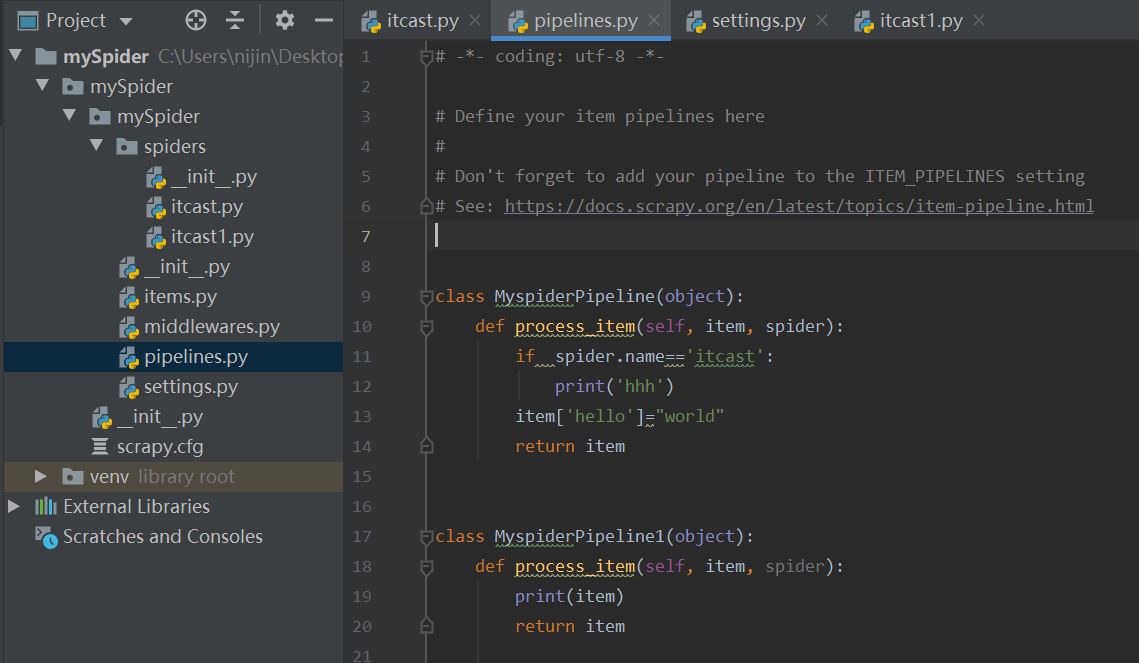
设置多个爬虫,多个pipeline函数:
(第一张图: 爬虫文件会传递item参数给pipelines文件的函数)
(第二张图: 根据setting文件内的优先级高低依次进行处理然后传递)
爬虫itcast传递item给MyspiderPipeline处理后,再继续传递给MyspiderPipeline1(当然在传递的过程中要写上return item)
pipelines可以通过传递的spider对象的name属性 ,
判断item参数是从哪个爬虫py文件传递过来的,
spider.name属性值可自行设定