day36
死锁现象与递归锁
死锁现象
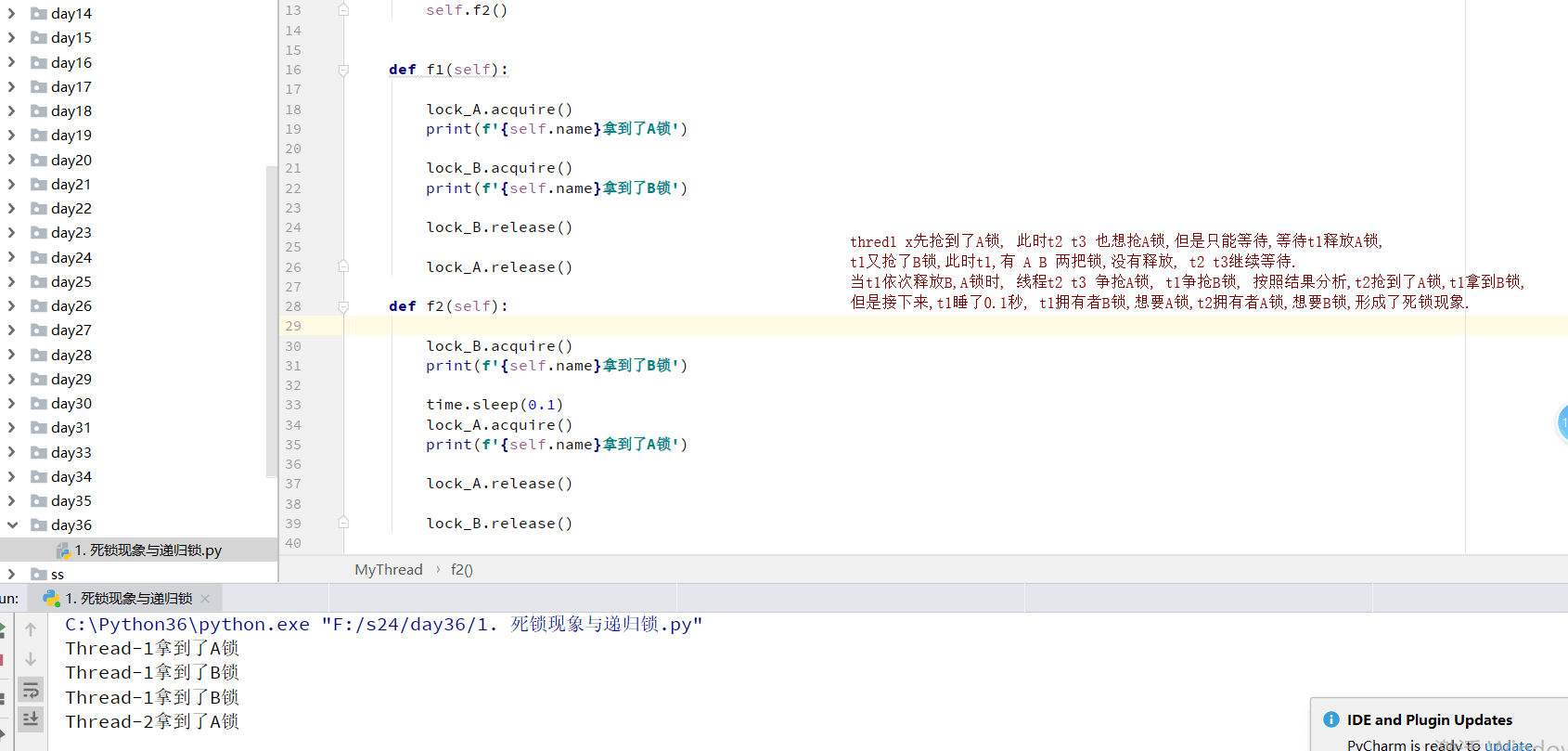
是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Thread
from threading import Lock
import time
lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f"{self.name}拿到了A锁")
lock_B.acquire()
print(f"{self.name}拿到了B锁")
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f"{self.name}拿到了B锁")
time.sleep(0.1)
lock_A.acquire()
print(f"{self.name}拿到了A锁")
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
结果:
Thread-1拿到了A锁
Thread-1拿到了B锁
Thread-1拿到了B锁
Thread-2拿到了A锁
未结束
递归锁
递归锁可以解决死锁现象,业务需要多个锁时,先要考虑递归锁
递归锁有一个计数的功能,原数字为0,上一次锁计数+1,释放一次锁计数-1
只要递归锁上面的数字不为零,其他线程就不能枪锁
总结定义:RLock,同一把锁,引用一次计数+1,释放一次计数-1,只要计数不为零,其他线程进程就抢不到,他能解决死锁问题
from threading import Thread
from threading import RLock
import time
lock_B = lock_A = RLock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f"{self.name}拿到了A锁")
lock_B.acquire()
print(f"{self.name}拿到了B锁")
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f"{self.name}拿到了B锁")
time.sleep(0.1)
lock_A.acquire()
print(f"{self.name}拿到了A锁")
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(10):
t = MyThread()
t.start()
信号量
也是一种锁,控制并发数量
总结定义:同一时刻可以设置抢锁的线程或者进程数量
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread, Semaphore, current_thread
import time
import random
sem = Semaphore(5)
def task():
sem.acquire()
·
print(f"{current_thread().name} 厕所ing")
time.sleep(random.randint(1, 3))
sem.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task)
t.start()
GIL全局解释器锁
总结定义:全局解释器锁,同一时刻只能一个线程进入解释器,Cpython解释器具有的。
好多自称大神的说,GIL锁是python的致命缺陷,python不能多核,并发不行等等。。。。
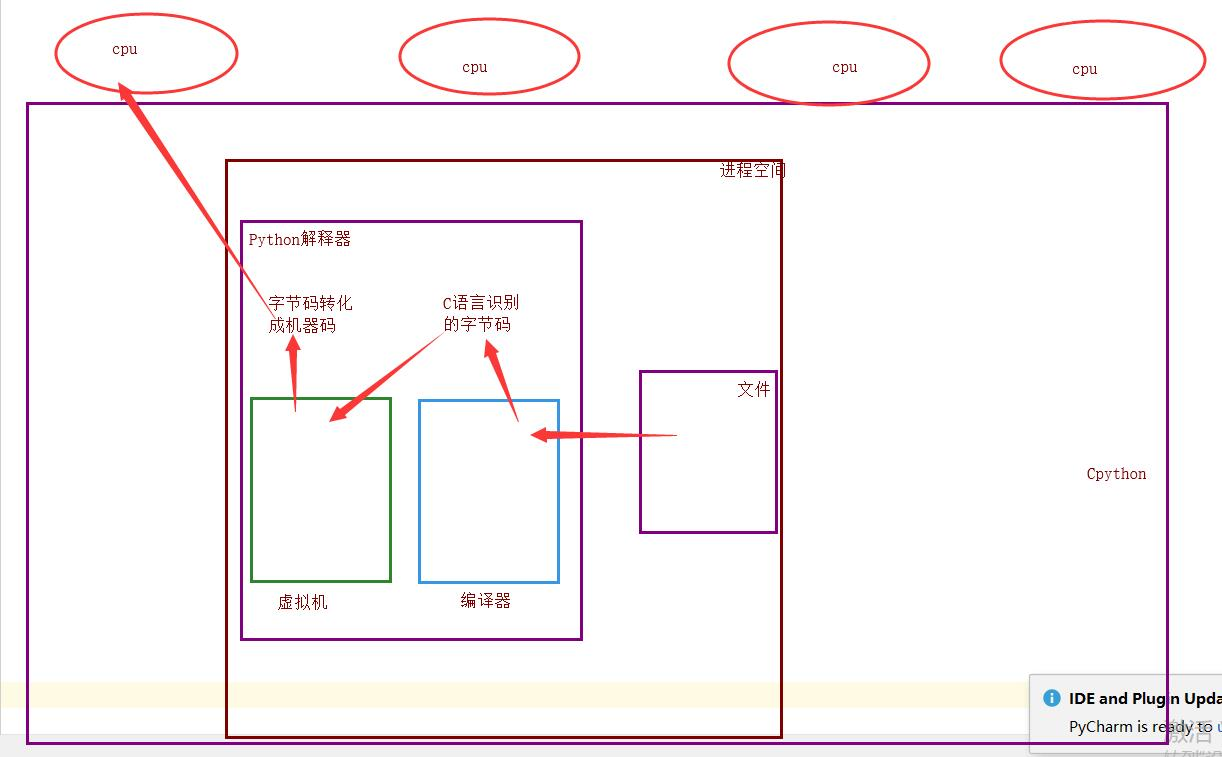
理论上来说:单个进程的多线程可以利用多核
但是开发Cpython解释器的程序员,给解释器加了锁
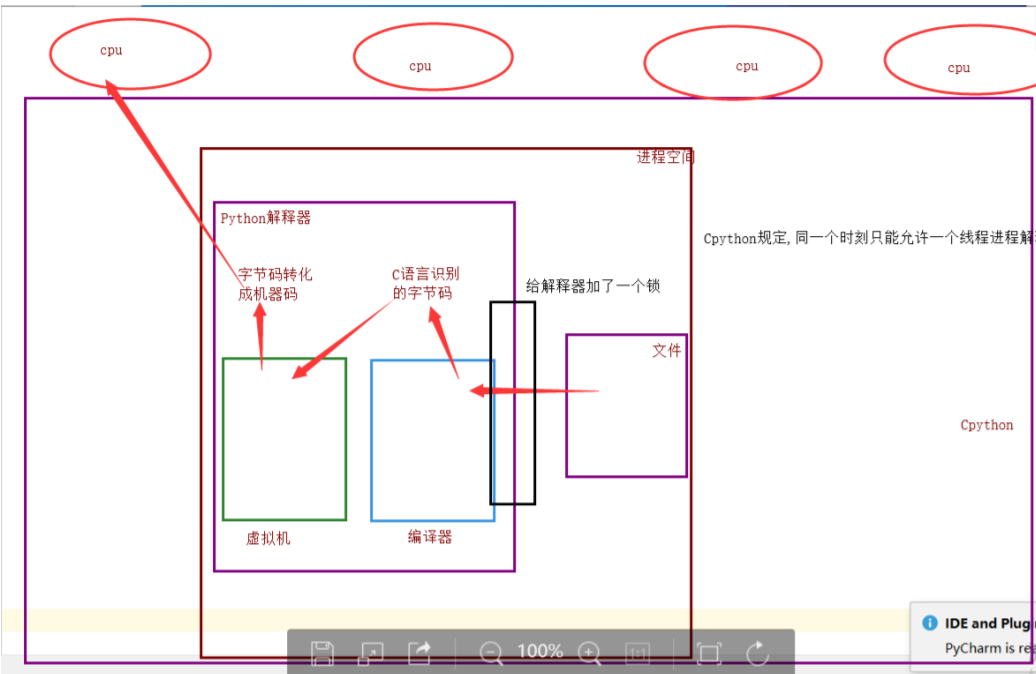
为什么加锁?
1、当时都是单核时代,而且cpu价格非常贵
2、如果不加全局解释器锁,开发Cpython解释器的程序员就会在源码内部各种主动加锁,解锁,非常麻烦,各种死锁现象等等,他为了省事就直接给解释器加了一个锁
- 优点:保证了Cpython解释器的数据资源的安全
- 缺点:单个进程的多线程不能利用多核
Jpython没有GIL锁
pypy也没有GIL锁
现在多核时代,我将Cpython的GIL去掉行不?
因为Cpython解释器所有的业务逻辑都是围绕着单个线程实现的,去掉这个GIL锁,几乎不可能
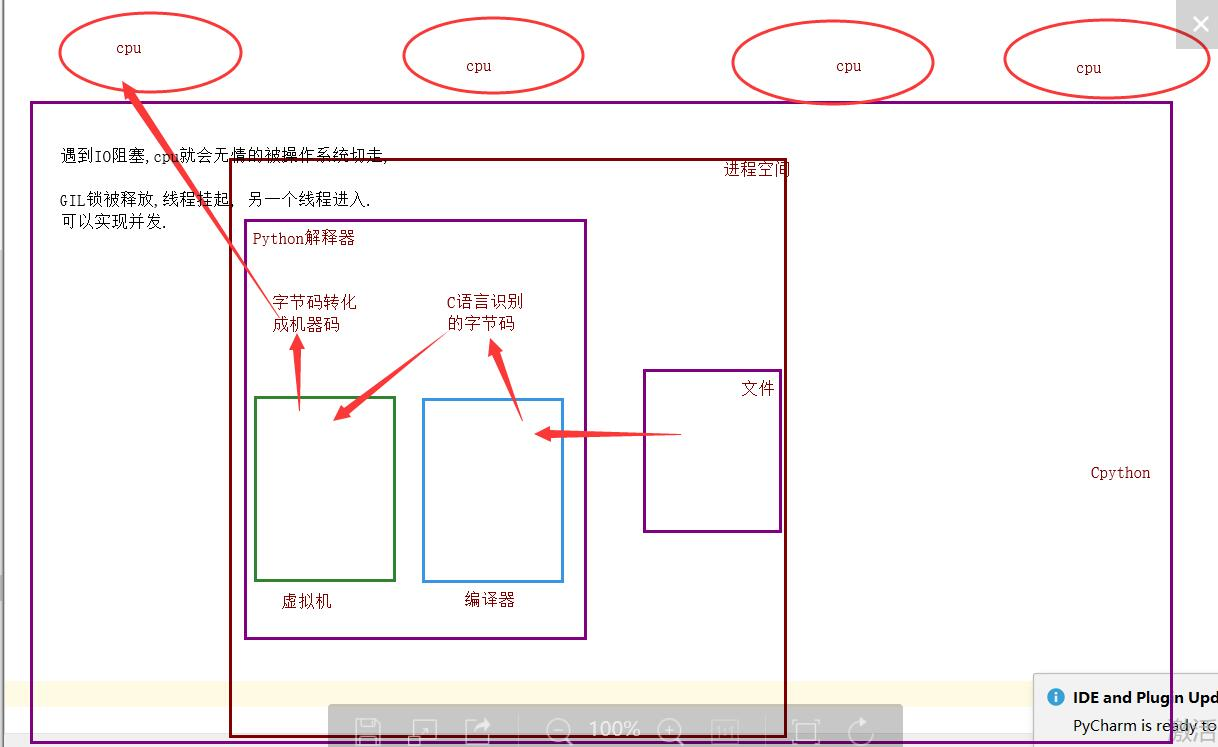
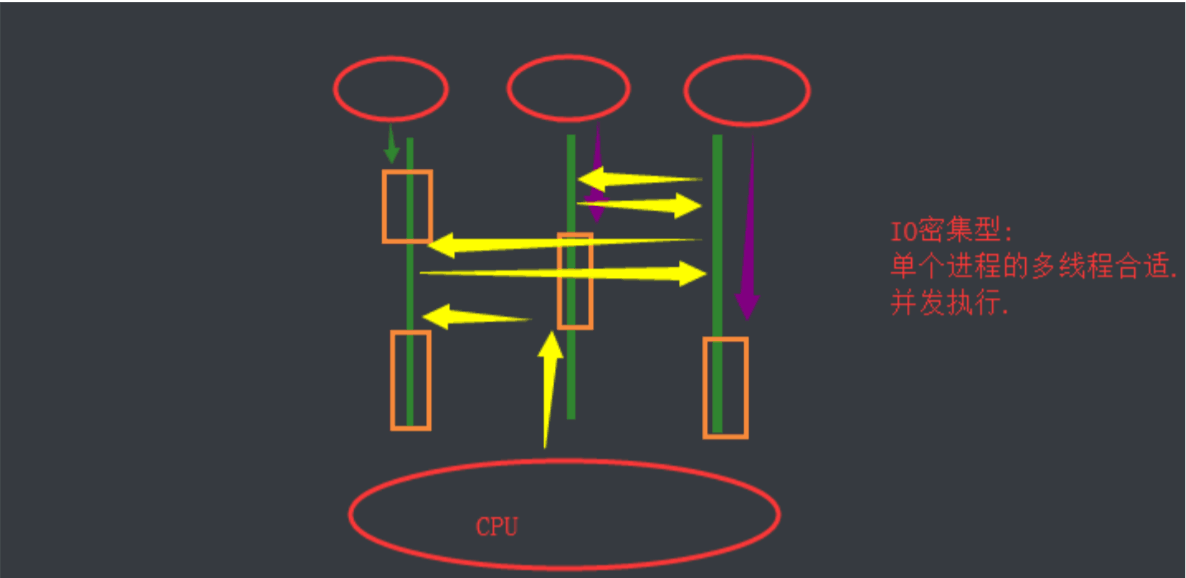
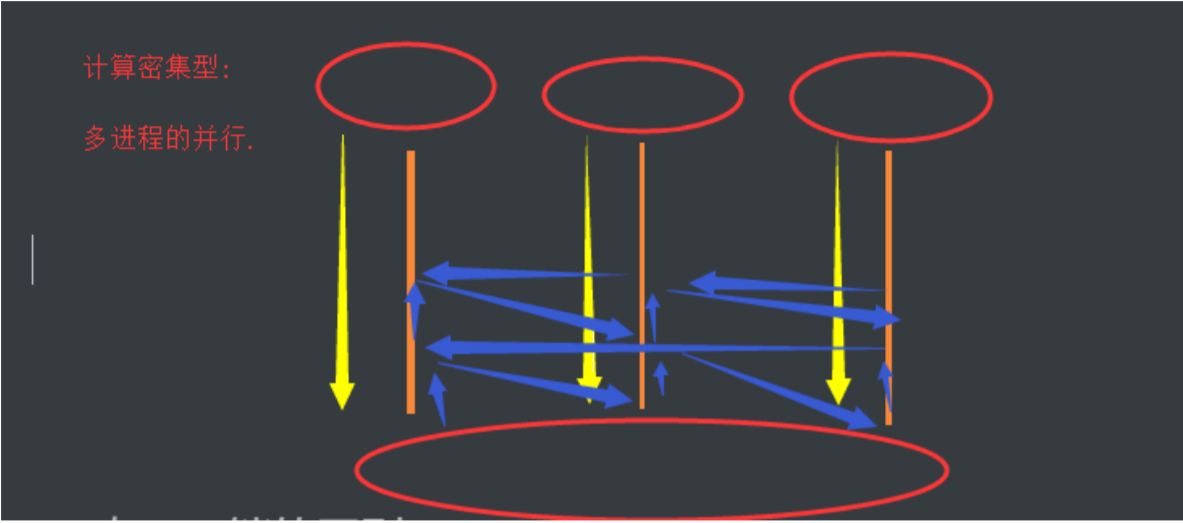
单个进程的多线程可以并发,但是不能利用多核进行并行
多个进程可以并发,并行
IO密集型
计算密集型
GIL与lock锁的区别
相同点
都是同种锁,互斥锁
不同点
- GIL锁是全局解释器锁,保护解释器内部的资源数据的安全
- GIL锁,上锁,释放无需手动操作
- 自己代码中定义的互斥锁保护进程中的资源数据的安全
- 自己定义的互斥锁必须自己手动上锁,释放锁
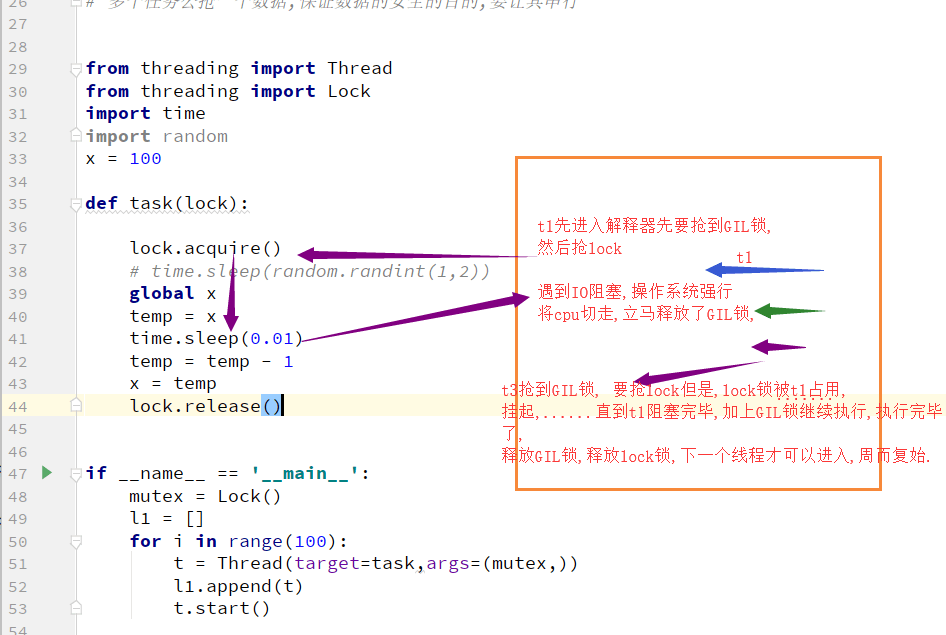
验证计算密集型IO密集型的效率
计算密集型
单个进程的多线程并发 vs 多个进程的并发并行
总结:计算密集型:多进程的并发并行效率高
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
for i in range(10000000):
count += 1
if __name__ == '__main__':
# 多进程的并发,并行
start_time = time.time()
l1 = []
for i in range(4):
p = Process(target=task)
l1.append(p)
p.start()
for j in l1:
j.join()
print(f"执行效率:{time.time() - start_time}") # 1.5881953239440918
# 多线程的并发
start_time = time.time()
l1 = []
for i in range(4):
p = Thread(target=task)
l1.append(p)
p.start()
for j in l1:
j.join()
print(f"执行效率:{time.time() - start_time}") # 5.415819883346558
IO密集型
IO密集型:单个进程的多线程并发 vs 多个进程的并发进行
对于IO密集型:单个进程的多线程的并发效率高
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1, 3))
count += 1
if __name__ == '__main__':
# 多进程的并发,并行
start_time = time.time()
l1 = []
for i in range(50):
p = Process(target=task)
l1.append(p)
p.start()
for j in l1:
j.join()
print(f"执行效率:{time.time() - start_time}") # 4.230581283569336
# 多线程的并发
start_time = time.time()
l1 = []
for i in range(50):
p = Thread(target=task)
l1.append(p)
p.start()
for j in l1:
j.join()
print(f"执行效率:{time.time() - start_time}") # 3.011176347732544
多线程实现socket通信
server
import socket
from threading import Thread
def _accept():
server = socket.socket()
server.bind(("127.0.0.1", 8848))
server.listen(5)
while 1:
conn, addr = server.accept()
t = Thread(target=communicate, args=(conn, addr))
t.start()
def communicate(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f"来自客户端{addr[1]}的消息:{from_client_data.decode('utf-8')}")
to_client_data = input(">>>").strip()
conn.send(to_client_data.encode("utf-8"))
except Exception:
break
conn.close()
if __name__ == '__main__':
_accept()
client
import socket
client = socket.socket()
client.connect(("127.0.0.1", 8848))
while 1:
try:
to_server_data = input(">>>").strip()
client.send(to_server_data.encode("utf-8"))
from_server_data = client.recv(1024)
print(f"来自服务端的消息:{from_server_data.decode('utf-8')}")
except Exception:
break
client.close()
进程池、线程池
无论是多线程还是多进程,如果按照上面的写法,来一个客户端请求,我就开一个线程,来一个请求开一个线程
应该是这样:你的计算机允许范围内,开启的线程进程数量越多越好
线程池:一个容器,这个容器限制住你开启线程的数量,比如4个,第一次肯定只能并发的处理4个任务,只要有任务完成,线程马上就会接着执行下一个任务
进程池:一个容器,这个容器限制住你开启进程的数量,比如4个,第一次并行的处理4个任务,只要有任务完成,进程马上就会接着执行下一个任务
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
# print(os.cpu_count())
def task(n):
print(f"{os.getpid()}接客")
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
# 开启进程池(并行+并发)
p = ProcessPoolExecutor(4) # 默认不写,进程池里面的进程数与cpu里面的内核个数相等
#
# # p.submit(task,1)
# # p.submit(task,1)
# # p.submit(task,1)
# # p.submit(task,1)
# # p.submit(task,1)
# # p.submit(task,1)
for i in range(22):
p.submit(task, 1)
# 开启线程池 (并发)
# t = ThreadPoolExecutor() # 默认不写,cpu内核个数*5=线程数
t = ThreadPoolExecutor(8) # 100个线程
for i in range(50):
t.submit(task, i)