很久以前就有想过使用深度学习模型来对dota2的对局数据进行建模分析,以便在英雄选择,出装方面有所指导,帮助自己提升天梯等级,但苦于找不到数据源,该计划搁置了很长时间。直到前些日子,看到社区有老哥提到说OpenDota网站(https://www.opendota.com/)提供有一整套的接口可以获取dota数据。通过浏览该网站,发现数据比较齐全,满足建模分析的需求,那就二话不说,开始干活。
这篇文章分为两大部分,第一部分为数据获取,第二部分为建模预测。
Part 1,数据获取
1.接口分析
dota2的游戏对局数据通过OpenDota所提供的API进行获取,通过阅读API文档(https://docs.opendota.com/#),发现几个比较有意思/有用的接口:
①请求单场比赛

上面就是一条聊天记录示例,在这局游戏的第7条聊天记录中,玩家“高高兴兴把家回”发送了消息:”1指1个小朋友”。
②随机查找10场比赛https://api.opendota.com/api/findMatches
该URL会随机返回10场近期比赛的基本数据,包括游戏起始时间,对阵双方英雄ID,天辉是否胜利等数据。
③查找英雄id对应名称
https://api.opendota.com/api/heroes
该接口URL返回该英雄对应的基本信息,包括有英雄属性,近战/远程,英雄名字,英雄有几条腿等等。这里我们只对英雄名字这一条信息进行使用。
④查看数据库表
https://api.opendota.com/api/schema
这个接口URL可以返回opendota数据库的表名称和其所包含的列名,在写sql语句时会有所帮助,一般与下方的数据浏览器接口配合使用。
⑤数据浏览器
https://api.opendota.com/api/explorer?sql={查询的sql语句}
该接口用来对网站的数据库进行访问,所输入参数为sql语句,可以对所需的数据进行筛选。如下图就是在matches表中寻找ID=5080676255的比赛的调用方式。
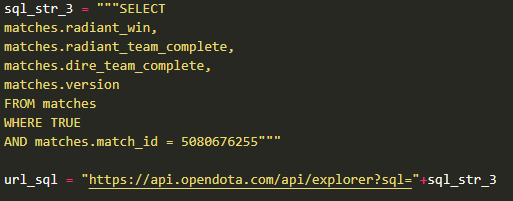
但是在实际使用中发现,这个数据浏览器接口仅能够查询到正式比赛数据,像我们平时玩的游戏情况在matches数据表里是不存在的。
⑥公开比赛查找
https://api.opendota.com/api/publicMatches?less_than_match_id={match_id}
该接口URL可以查询到我们所需要的在线游戏对局数据,其输入参数less_than_match_id指的是某局游戏的match_id,该接口会返回100条小于这个match_id的游戏对局数据,包括游戏时间,持续时间,游戏模式,大厅模式,对阵双方英雄,天辉是否获胜等信息。本次建模所需的数据都是通过这个接口来进行获取的。
2.通过爬虫获取游戏对局数据
这次实验准备建立一个通过对阵双方的英雄选择情况来对胜率进行预测的模型,因此需要获得以下数据,[天辉方英雄列表]、[夜魇方英雄列表]、[哪方获胜]。
此外,为了保证所爬取的对局质量,规定如下限制条件:平均匹配等级>4000,游戏时间>15分钟(排除掉秒退局),天梯匹配比赛(避免普通比赛中乱选英雄的现象)。
首先,完成数据爬取函数:
1 #coding:utf-8 2 3 import json 4 import requests 5 import time 6 7 base_url = 'https://api.opendota.com/api/publicMatches?less_than_match_id=' 8 session = requests.Session() 9 session.headers = { 10 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' 11 } 12 13 def crawl(input_url): 14 time.sleep(1) # 暂停一秒,防止请求过快导致网站封禁。 15 crawl_tag = 0 16 while crawl_tag==0: 17 try: 18 session.get("http://www.opendota.com/") #获取了网站的cookie 19 content = session.get(input_url) 20 crawl_tag = 1 21 except: 22 print(u"Poor internet connection. We'll have another try.") 23 json_content = json.loads(content.text) 24 return json_content
这里我们使用request包来新建一个公共session,模拟成浏览器对服务器进行请求。接下来编辑爬取函数crawl(),其参数 input_url 代表opendota所提供的API链接地址。由于没有充值会员,每秒钟只能向服务器发送一个请求,因此用sleep函数使程序暂停一秒,防止过快调用导致异常。由于API返回的数据是json格式,我们这里使用json.loads()函数来对其进行解析。
接下来,完成数据的筛选和记录工作:
1 max_match_id = 5072713911 # 设置一个极大值作为match_id,可以查出最近的比赛(即match_id最大的比赛)。 2 target_match_num = 10000 3 lowest_mmr = 4000 # 匹配定位线,筛选该分数段以上的天梯比赛 4 5 match_list = [] 6 recurrent_times = 0 7 write_tag = 0 8 with open('../data/matches_list_ranking.csv','w',encoding='utf-8') as fout: 9 fout.write('比赛ID, 时间, 天辉英雄, 夜魇英雄, 天辉是否胜利 ') 10 while(len(match_list)<target_match_num): 11 json_content = crawl(base_url+str(max_match_id)) 12 for i in range(len(json_content)): 13 match_id = json_content[i]['match_id'] 14 radiant_win = json_content[i]['radiant_win'] 15 start_time = json_content[i]['start_time'] 16 avg_mmr = json_content[i]['avg_mmr'] 17 if avg_mmr==None: 18 avg_mmr = 0 19 lobby_type = json_content[i]['lobby_type'] 20 game_mode = json_content[i]['game_mode'] 21 radiant_team = json_content[i]['radiant_team'] 22 dire_team = json_content[i]['dire_team'] 23 duration = json_content[i]['duration'] # 比赛持续时间 24 if int(avg_mmr)<lowest_mmr: # 匹配等级过低,忽略 25 continue 26 if int(duration)<900: # 比赛时间过短,小于15min,视作有人掉线,忽略。 27 continue 28 if int(lobby_type)!=7 or (int(game_mode)!=3 and int(game_mode)!=22): 29 continue 30 x = time.localtime(int(start_time)) 31 game_time = time.strftime('%Y-%m-%d %H:%M:%S',x) 32 one_game = [game_time,radiant_team,dire_team,radiant_win,match_id] 33 match_list.append(one_game) 34 max_match_id = json_content[-1]['match_id'] 35 recurrent_times += 1 36 print(recurrent_times,len(match_list),max_match_id) 37 if len(match_list)>target_match_num: 38 match_list = match_list[:target_match_num] 39 if write_tag<len(match_list): # 如果小于新的比赛列表长度,则将新比赛写入文件 40 for i in range(len(match_list))[write_tag:]: 41 fout.write(str(match_list[i][4])+', '+match_list[i][0]+', '+match_list[i][1]+', '+ 42 match_list[i][2]+', '+str(match_list[i][3])+' ') 43 write_tag = len(match_list)
在上述代码中,首先定义一个 max_match_id ,即表明搜索在这场比赛之前的对局数据,另外两个变量target_match_num 和 lowest_mmr 分别代表所需记录的对局数据数量、最低的匹配分数。
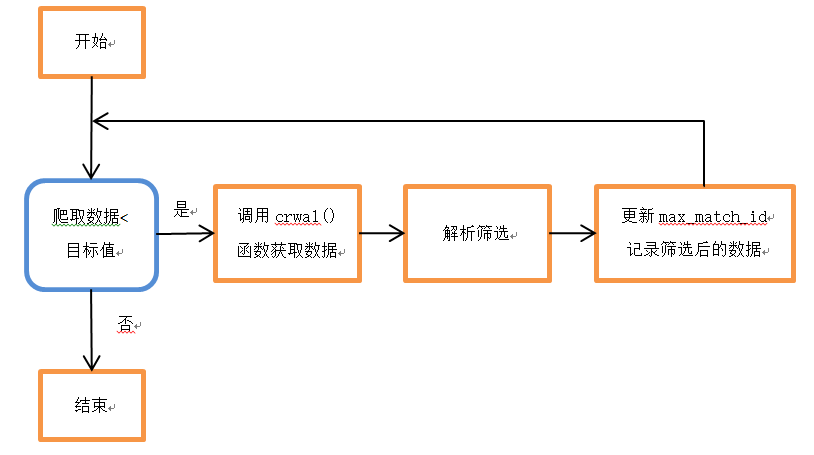
外层while循环判断已经获取的比赛数据数量是否达到目标值,未达到则继续循环;在每次while循环中,首先通过crawl()函数获取服务器返回的数据,内层for循环对每一条json数据进行解析、筛选(其中lobby_type=7是天梯匹配,game_mode=3是随机征召模式,game_mode=22是天梯全英雄选择模式)。在for循环结束后,更新max_match_id的值(使其对应到当前爬取数据的最后一条数据,下一次爬取数据时则从该位置继续向下爬取),再将新爬取的数据写入csv数据文件。工作流程如下方图示,其中蓝框表示条件判断。
最终,我们通过该爬虫爬取了10万条游戏对阵数据,其格式如下:
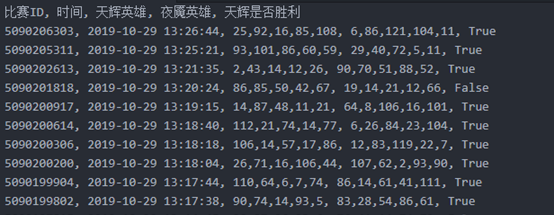
这10万条数据包含了10月16日2点到10月29日13点期间所有的高分段对局数据,每一条数据共有5个属性,分别是[比赛ID,开始时间,天辉英雄列表,夜魇英雄列表,天辉是否胜利] 下面开始用这些数据来进行建模。
Part 2,建模及预测
1.训练数据制作
一条训练(测试)样本分为输入、输出两个部分。
输入部分由一个二维矩阵组成,其形状为[2*129]其中2代表天辉、夜魇两个向量,每个向量有129位,当天辉(夜魇)中有某个英雄时,这个英雄id所对应的位置置为1,其余位置为0。因此,一条样本的输入是由两个稀疏向量组成的二维矩阵。(英雄id的取值范围为1-129,但实际只有117个英雄,有些数值没有对应任何英雄,为了方便样本制作,将向量长度设为129)
输出部分则是一个整形的标量,代表天辉方是否胜利。我们将数据文件中的True使用1来代替,False使用0来代替。
因此,10万条样本最终的输入shape为[100000,2,129],输出shape为[100000,1]。
1 # ===================TODO 读取对局数据 TODO======================== 2 with open('../data/matches_list_ranking_all.csv','r',encoding='utf-8') as fo_1: 3 line_matches = fo_1.readlines() 4 sample_in = [] 5 sample_out = [] 6 for i in range(len(line_matches))[1:]: 7 split = line_matches[i].split(', ') 8 radiant = split[2] 9 dire = split[3] 10 # print(split[4][:-1]) 11 if split[4][:-1]=='True': 12 win = 1.0 13 else: 14 win = 0.0 15 radiant = list(map(int,radiant.split(','))) 16 dire = list(map(int,dire.split(','))) 17 radiant_vector = np.zeros(hero_id_max) 18 dire_vector = np.zeros(hero_id_max) 19 for item in radiant: 20 radiant_vector[item-1] = 1 21 for item in dire: 22 dire_vector[item-1] = 1 23 sample_in.append([radiant_vector,dire_vector]) 24 sample_out.append(win)
之后,我们将样本进行分割,按照8:1:1的比例,80000条样本作为训练集,10000条样本作为测试集,10000条样本作为验证集。其中验证集的作用是模型每在训练集上训练一个轮次以后,观测模型在验证集上的效果,如果模型在验证集上的预测精度没有提升,则停止训练,以防止模型对训练集过拟合。
1 def make_samples(): 2 train_x = [] 3 train_y = [] 4 test_x = [] 5 test_y = [] 6 validate_x = [] 7 validate_y = [] 8 for i in range(len(sample_in)): 9 if i%10==8: 10 test_x.append(sample_in[i]) 11 test_y.append(sample_out[i]) 12 elif i%10==9: 13 validate_x.append(sample_in[i]) 14 validate_y.append(sample_out[i]) 15 else: 16 train_x.append(sample_in[i]) 17 train_y.append(sample_out[i]) 18 return train_x,train_y,test_x,test_y,validate_x,validate_y
2.搭建深度学习模型
考虑到一个样本的输入是由两个稀疏向量组成的二维矩阵,这里我们一共搭建了三种模型,CNN模型,LSTM模型以及CNN+LSTM模型。那为什么用这三种模型呢,我其实也做不出什么特别合理的解释~~先试试嘛,效果不行丢垃圾,效果不错真牛B。
①CNN模型
模型构建的示意图如下,使用维度为长度为3的一维卷积核对输入进行卷积操作,之后再经过池化和两次全链接操作,将维度变为[1*1],最后使用sigmoid激活函数将输出限定在[0,1]之间,即对应样本的获胜概率。下图展现了矩阵、向量的维度变化情况。
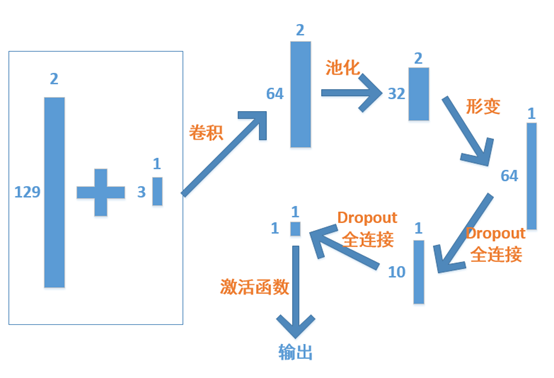
下方为模型代码,考虑到使用二维卷积时,会跨越向量,即把天辉和夜魇的英雄卷到一起,可能对预测结果没有实际帮助,这里使用Conv1D来对输入进行一维卷积。经过卷积操作后,得到维度为[2,64]的矩阵,再使用配套的MaxPooling1D()函数加入池化层。下一步使用Reshape()函数将其调整为一维向量,再加上两个Dropout和Dense层将输出转换成一个标量。
1 model = Sequential() 2 model.add(Conv1D(cnn_output_dim,kernel_size,padding='same',activation='relu',input_shape=(team_num,hero_id_max))) #(none,team_num,129) 转换为 (none,team_num,32) 3 model.add(MaxPooling1D(pool_size=pool_size,data_format='channels_first')) #(none,team_num,32)转换为 (none,team_num,16) 4 model.add(Reshape((int(team_num*cnn_output_dim/pool_size),), input_shape=(team_num,int(cnn_output_dim/pool_size)))) 5 model.add(Dropout(0.2)) 6 model.add(Dense((10),input_shape=(team_num,cnn_output_dim/pool_size))) 7 model.add(Dropout(0.2)) 8 model.add(Dense(1)) # 全连接到一个元素 9 model.add(Activation('sigmoid')) 10 model.compile(loss='mse',optimizer='adam',metrics=['accuracy'])
在实际的调参过程中,卷积核长度,卷积输出向量维度,Dropout的比例等参数都不是固定不变的,可以根据模型训练效果灵活的进行调整。
②LSTM模型
模型构建的示意图如下,LSTM层直接以[2,129]的样本矩阵作为输入,生成一个长度为256的特征向量,该特征向量经过两次Dropout和全连接,成为一个标量,再使用sigmoid激活函数将输出限定在[0,1]之间。
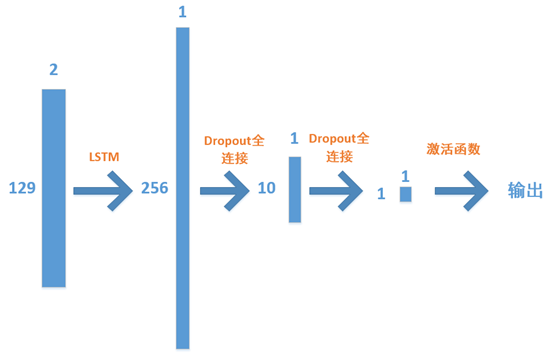
下方为构建LSTM模型的代码,要注意hidden_size参数即为输出特征向量的长度,在进行调参时,也是一个可以调节的变量。
1 model = Sequential() 2 model.add(LSTM(hidden_size, input_shape=(team_num,hero_id_max), return_sequences=False)) # 输入(none,team_num,129) 输出向量 (hidden_size,) 3 model.add(Dropout(0.2)) 4 model.add(Dense(10)) 5 model.add(Dropout(0.2)) 6 model.add(Dense(1)) # 全连接到一个元素 7 model.add(Activation('sigmoid')) 8 model.compile(loss='mse',optimizer='adam',metrics=['accuracy'])
③CNN+LSTM模型
模型构建的示意图如下,与CNN模型很像,唯一区别是将reshape操作由LSTM层进行替换,进而生成一个长度为256的特征向量。
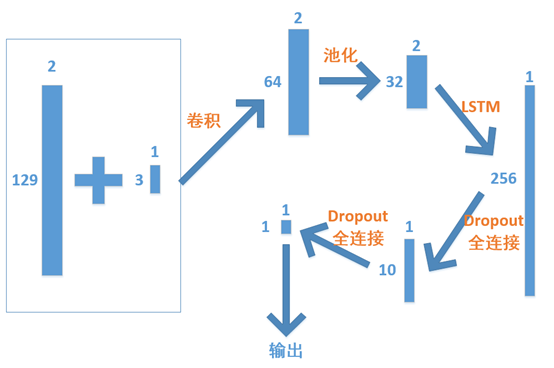
CNN+LSTM模型的代码如下,与前两个模型方法类似,这里不再详细解说。
1 model = Sequential() 2 model.add(Conv1D(cnn_output_dim,kernel_size,padding='same',input_shape=(team_num,hero_id_max))) #(none,team_num,9) 转换为 (none,team_num,32) 3 model.add(MaxPooling1D(pool_size=pool_size,data_format='channels_first')) #(none,team_num,32)转换为 (none,team_num,16) 4 model.add(LSTM(hidden_size, input_shape=(team_num,(cnn_output_dim/pool_size)), return_sequences=False)) # 输入(none,team_num,129) 输出向量 (hidden_size,) 5 model.add(Dropout(0.2)) 6 model.add(Dense(10)) 7 model.add(Dropout(0.2)) 8 model.add(Dense(1)) # 全连接到一个元素 9 model.add(Activation('sigmoid')) 10 model.compile(loss='mse',optimizer='adam',metrics=['accuracy'])
3.设置回调函数(callbacks)
回调函数是在每一轮训练之后,检查模型在验证集上的效果,如经过本轮训练,模型验证集上的预测效果比上一轮要差,则回调函数可以做出调整学习率或停止训练的操作。
1 callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss', patience=2, verbose=0, mode='min'), 2 keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=1, verbose=0, mode='min', 3 epsilon=0.0001, cooldown=0, min_lr=0)] 4 hist = model.fit(tx,ty,batch_size=batch_size,epochs=epochs,shuffle=True, 5 validation_data=(validate_x, validate_y),callbacks=callbacks) 6 model.save(model_saved_path+model_name+'.h5')
先设定回调函数callbacks,其中monitor=’val_loss’是指对验证集的损失进行监控,如果这个loss经过一轮训练没有继续变小,则进行回调;patience参数指的是等待轮次,在上述代码中,如果连续1轮训练’val_loss’没有变小,则调整学习率(ReduceLROnPlateau),如果连续2轮训练’val_loss’没有变小,则终止训练(EarlyStopping)。
最后使用model.fit()函数开始训练,tx,ty是训练集的输入与输出,在validation_data参数中需要传入我们的验证集,而在callbacks参数中,需要传入我们设置好的回调函数。
4.预测效果
我们将训练后的模型来对测试集进行预测,经过这一天的反复调参,得到了多个预测效果不错的模型,最高的模型预测准确度可以达到58%。即,对于“看阵容猜胜负”这个任务,模型可以达到58%的准确率。为了更全面的了解模型的预测效果,我们分别计算模型在测试集、训练集、验证集上的预测准确度,并计算模型在打分较高的情况下的预测精度。以下面这个模型为例:
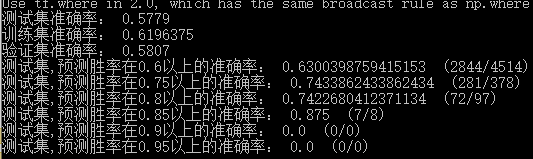
可以看出,模型在训练集上的预测效果稍好,超过61%,而在训练集和验证集上的预测准确度在58%附近,没有出现特别明显的过拟合现象。
此外对于测试中的10000个样本,有4514个被模型判断为拥有60%以上的胜率,其中2844个预测正确,准确率达到63%;
有378场比赛被模型判断为拥有75%以上的胜率,其中281场预测正确,准确率74.3%;
有97场比赛被模型判断为拥有80%以上的胜率(阵容选出来就八二开),其中72场预测正确,准确率74.2%;
还有8场被模型认定为接近九一开的比赛,预测对了7场,准确率87.5%。
可以看出,模型给出的预测结果具有一定的参考价值。
为了对预测效果有些直观的感受,修改代码让模型对预测胜率大于0.85的比赛阵容进行展示。

这8场比赛,模型全部预测天辉胜率,胜率从85%~87%不等。如果让我来看阵容猜胜负的话,我是没有信心给到这么高的概率的。这8场比赛中,帕吉的出现次数很多,达到了5次,我在max+上查询了一下帕吉的克制指数:
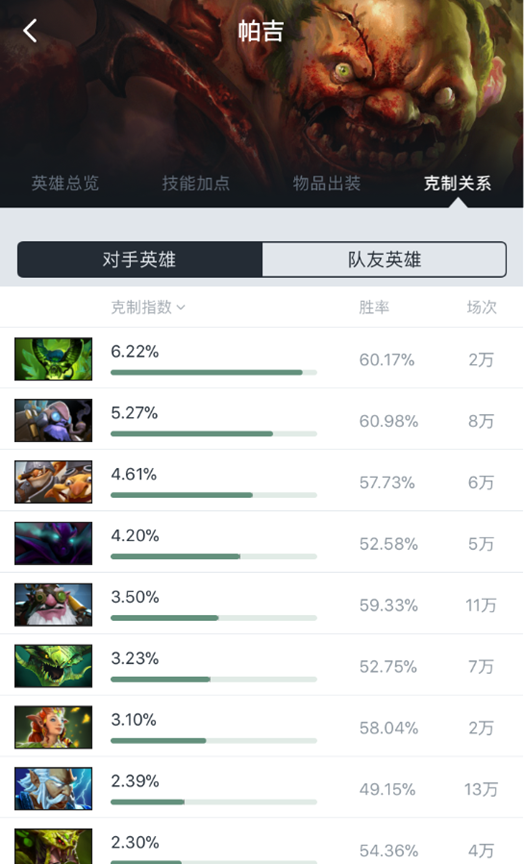
从上图可以看出,在上面的8场比赛中,修补匠、炸弹人(工程师)、幽鬼、狙击手、魅惑魔女这些英雄确实出现在了帕吉的对面。这也说明我们模型的预测结果与统计层面上所展示出来的结论是较为一致的。
写在最后:
1.代码已经上传到GitHub上,有兴趣的同学可以去玩一玩。https://github.com/NosenLiu/Dota2_data_analysis
2.展望一下应用场景。
①选好阵容以后,用模型预测一下,阵容82开或91开的话,直接秒退吧,省的打完了不开心。╮( ̄﹏ ̄)╭
②对方已经选好阵容,我方还差一个英雄没选的情况下,使用模型对剩下来的英雄进行预测,选出胜率最高的英雄开战。实现起来较为困难,估计程序还没跑完,选英雄的时间就已经到了。
③参与电竞比赛博彩,根据预测结果下注。这个嘛,鉴于天梯单排和职业战队比赛观感上完全不一样,估计模型不能做出较为准确的预测。
3.可能会有同学会问这次的10万条样本能不能包含所有的对阵可能性,结论是否定的。我也是在开展本次实验之前计算了一下,真是不算不知道,一算吓一跳。游戏一共有117个英雄,天辉选择5个,夜魇在剩余的112个里面选5个,一共能选出来
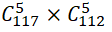 种不同的对阵,大概是2*1016!10万条样本完全只是九牛一毛而已。
种不同的对阵,大概是2*1016!10万条样本完全只是九牛一毛而已。
4.最后吐槽一下V社的平衡性吧,这次爬取的10万条比赛记录,天辉胜利的有54814条,夜魇胜利的有45186条。说明当前版本地图的平衡性也太差了,天辉胜率比夜魇胜率高了9.6%。
