kafka_2.10-0.10.0.0集群安装
|
IP |
HOST |
|
192.168.132.94 |
BDTEST05 |
|
192.168.132.95 |
BDTEST06 |
|
192.168.132.96 |
BDTEST07 |
1. 配置java环境
非常简单就不介绍了
2. 安装zookeeper集群
kafka自带有zookeeper服务,但是建议大家最好单独建立一个zookeeper集群,可以和其他应用共享,也便于管理
安装介绍见“zookeeper-3.4.6集群部署”文档
3. 准备安装介质
将下载好的介质kafka_2.10-0.10.0.0.tgz(此处下载的是已编译的)传到服务上并解压
[hduser@BDTEST05 app]$ tar -zxvf kafka_2.10-0.10.0.0.tgz

4. 更改kafka配置文件
[hduser@BDTEST05 app]$ vi /app/kafka_2.10-0.10.0.0/config/server.properties
kafka_2.10-0.10.0.0版本的这个配置文件和以前版本有些差别
需要配置的属性有:
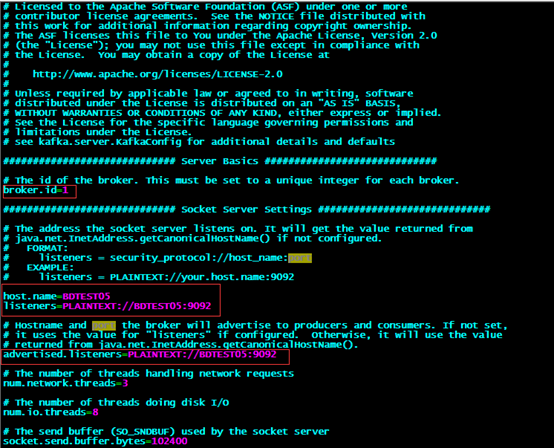
broker.id=1
host.name=BDTEST05
listeners=PLAINTEXT://BDTEST05:9092
advertised.listeners=PLAINTEXT://BDTEST05:9092
log.dirs=/app/kafka_2.10-0.10.0.0/logs
num.partitions=4
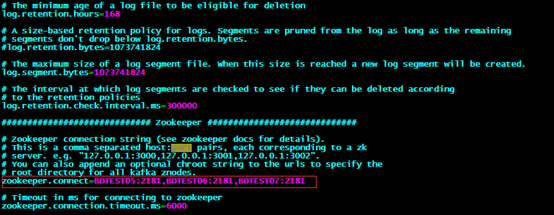
zookeeper.connect=BDTEST05:2181,BDTEST06:2181,BDTEST07:2181
broker.id(标示当前server在集群中的id,有的说从0开始,有的说从1开始),数字且唯一
log.dirs(log的存储目录,要对应的去建立这个目录)等,其他的一些配置可以看相应的注释:
其他配置暂时采取默认
zookeeper.connect(连接的zookeeper集群)
5. 拷贝kafka到另外两台机器
[hduser@BDTEST05 app]$ scp -r /app/kafka_2.10-0.10.0.0/ hduser@BDTEST06://app/
[hduser@BDTEST05 app]$ scp -r /app/kafka_2.10-0.10.0.0/ hduser@BDTEST07://app/
对应更改配置文件/app/kafka_2.10-0.10.0.0/config/server.properties中的

6. 启动kafka服务
注意:先启动zookeeper集群,再启动kakfa集群
查看zookeeper服务是否启动(这里查看一台的就可以了)
[hduser@BDTEST05 app]$ clush -g zookeeper /app/zookeeper-3.4.6/bin/zkServer.sh status

在每台机器上启动kafka服务
[hduser@BDTEST05 app]$ nohup /app/kafka_2.10-0.10.0.0/bin/kafka-server-start.sh /app/kafka_2.10-0.10.0.0/config/server.properties &
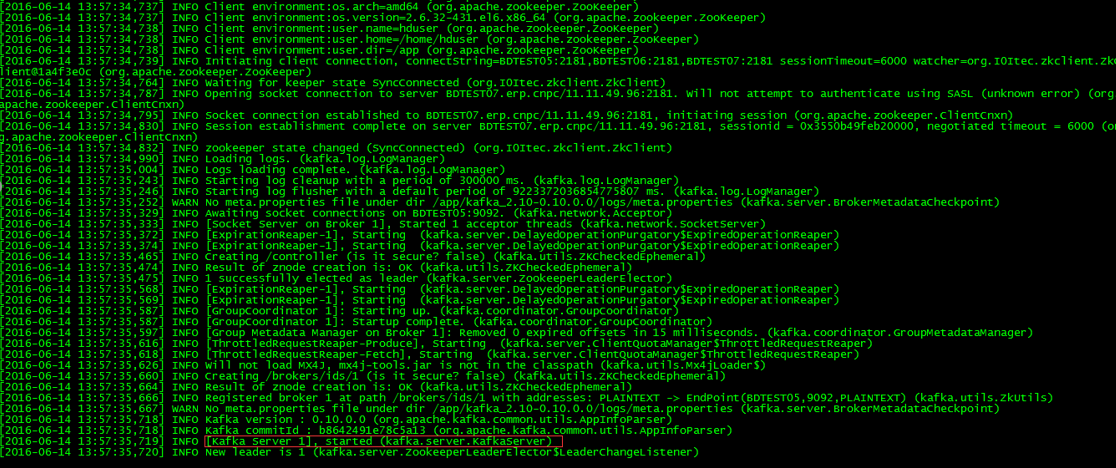
&表示后台运行,否则一旦终端关闭服务立刻停止 配合nohup使用,这样不会看到如下图日志
7. 简单测试kafka
(1)任意一台机器上面(此测试在BDTEST05上),测试:在kafka中创建名为“cmy_nbd_topic1”的topic,该topic切分为4份,每一份备份数为3
[hduser@BDTEST05 bin]$ ./kafka-topics.sh --create --zookeeper BDTEST05:2181 --replication-factor 3 --partitions 4 --topic cmy_nbd_topic1
(2)列出所有topic :
[hduser@BDTEST05 bin]$ ./kafka-topics.sh --list --zookeeper BDTEST05:2181,BDTEST06:2181,BDTEST07:2181

一个完整测试
(1)单机连通性测试:
(a)运行producer:
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
(b)运行consumer:
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
在producer端输入字符串并回车,查看consumer端是否显示。
(2) 分布式连通性测试
Zookeeper Server, Kafka Server, Producer都放在服务器BDTEST05上
Consumer放在服务器BDTEST06上
修改Kafka Server的配置文件,将这行修改成这样:
advertised.listeners=PLAINTEXT://BDTEST05:9092
(a)运行BDTEST05上面的producer:
[hduser@BDTEST05 bin]$ ./kafka-console-producer.sh --broker-list BDTEST05:9092 --topic test
(b)运行BDTEST06上面的consumer:
[hduser@BDTEST06 bin]$ ./kafka-console-consumer.sh --zookeeper BDTEST06:2181 --topic test --from-beginning
在producer端输入字符串并回车,查看consumer端是否显示。






8. 关闭kafka服务
/app/kafka_2.10-0.10.0.0/bin/kafka-server-stop.sh
9. 设置集群启动、关闭脚本
之前安装zookeeper时已经配置clush工具,添加了zookeeper组

(1)创建关闭kafka服务器组脚本
[hduser@BDTEST05 service]$ vi stopKafka.sh
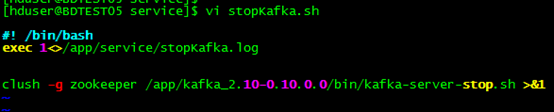
(2)创建启动kafka服务器组脚本

执行脚本
[hduser@BDTEST05 service]$ sh stopKafka.sh
[hduser@BDTEST05 service]$ sh startKafka.sh
问题
使用/app/kafka_2.10-0.10.0.0/bin/kafka-server-stop.sh停止服务停不掉,查看该停止脚本内容如下,使用jps 或者 ps -ef | grep kafka确实能够查到PID
但是脚本中ps ax | grep -i 'kafka.Kafka'就是查不到PID,这其中使用正则 如果单独使用ps ax | grep -i 'kafka'或者ps ax | grep -i '.Kafka'都能够查到
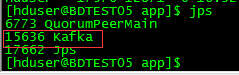
PIDS=$(ps ax | grep -i 'kafka.Kafka' | grep java | grep -v grep | awk '{print $1}')
if [ -z "$PIDS" ]; then
echo "No kafka server to stop"
exit 1
else
kill -s TERM $PIDS
fi
解决办法:更改脚本
