从TXT文本文档向Sql Server中批量导入数据
因为工作的需要,近期在做数据的分析和数据的迁移。在做数据迁移的时候需要将原有的数据导入到新建的数据库中。本来这个单纯的数据导入导出是没有什么问题的,但是客户原有的数据全部都是存在.dat文件中的。所以解决方案如下
一、首先用数据库查看工具Database System Utility查看客户提供的原有的.dat文件。并将该数据文件中的数据导出为.txt文件。
二、这里才是今天要将的关键部分。建设我们在数据库中的表结构是这样的
create table Test(ID int identity(1,1) primary key ,Name nvarchar(20),Sex nvarchar (2),IsWork bit)
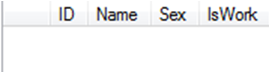
表结构如图
下面我们通过以下的简单的SQL语句即可实现数据的批量导入,代码如下:
Bulk insert test
From ‘C:\Users\Olive\Desktop\test.txt’
With
( fieldterminator=’,’,
rowterminator=’\n’
)
备注:1) bulk insert 为Sql server 中一个批量插入的操作
2)test 为上边定义的表,即我们的数据将要插入的表
3) ‘C:\Users\Olive\Desktop\test.txt’为数据源文件所在磁盘上的物理路径
4)with 相当于一些插入的附属条件,可以起这里添加一些约束限制条件等
5) fieldterminator=’,’字段的分割符为”,”一般的txt文本数据源的字段分隔都为逗号,当然也可以为其他,比如”|”
6) rowterminator=’\n’各条信息间的分割符为’\n’,一般的txt文本数据源的信息间的分割都是换行符,即一条信息占一行,也可以用其他格式如:”|\n”
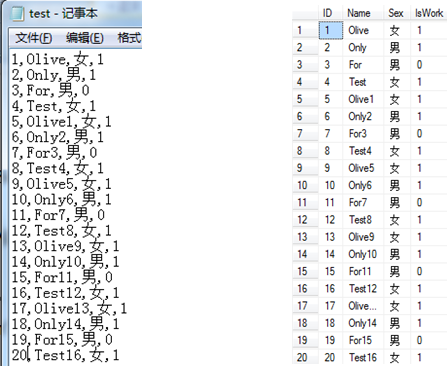
三、执行结果
1)执行前,test.txt文本文档的数据如下:执行后,sql server中数据如下
四、bulk Insert详解
这里只是大致上讲了一下bulk insert的用法,因为我们所涉及的表结构比较简单,表之间的关联也不是很大,所有就只是简单的用了下bulk insert。事实上bulk insert的功能还是比较强大的。上边讲了可以在with{}条件中加入一些参数以满足不同的需要。下面我们看一下微软官方的关于bulk insert 的用法介绍
BULK INSERT
[ database_name . [ schema_name ] . | schema_name . ] [ table_name | view_name ]
FROM 'data_file'
[ WITH
(
[ [ , ] BATCHSIZE = batch_size ]
[ [ , ] CHECK_CONSTRAINTS ]
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ [ , ] DATAFILETYPE =
{ 'char' | 'native'| 'widechar' | 'widenative' } ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] FIRSTROW = first_row ]
[ [ , ] FIRE_TRIGGERS ]
[ [ , ] FORMATFILE = 'format_file_path' ]
[ [ , ] KEEPIDENTITY ]
[ [ , ] KEEPNULLS ]
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ]
[ [ , ] LASTROW = last_row ]
[ [ , ] MAXERRORS = max_errors ]
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ]
[ [ , ] ROWS_PER_BATCH = rows_per_batch ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
[ [ , ] TABLOCK ]
[ [ , ] ERRORFILE = 'file_name' ]
)]
这里我们主要看with中的一些参数:(部分)
1) BATCHSIZE : 指定批处理中的行数
2) CHECK_CONSTRAINTS:启用约束检查,指定在大容量导入操作期间,必须检查所有对目标表或视图的约束。若没有 CHECK_CONSTRAINTS 选项,则忽略所有 CHECK 和 FOREIGN KEY 约束,并在该操作后将表的约束标记为不可信。始终强制使用 UNIQUE、PRIMARY KEY 和 NOT NULL 约束。
3) FIRE_TRIGGERS
指定将在大容量导入操作期间执行目标表中定义的所有插入触发器。如果为针对目标表的 INSERT 操作定义了触发器,则每次完成批处理操作时均激发触发器。
4) KEEPNULLS
指定空列在大容量导入操作期间应保留 Null 值,而不插入列的任何默认值
5) ORDER ( { column [ ASC | DESC ] } [ ,...n ] )
指定如何对数据文件中的数据排序。如果根据表中的聚集索引(如果有)对要导入的数据排序,则可提高大容量导入的性能
6) ERRORFILE ='file_name'
指定用于收集格式有误且不能转换为 OLE DB 行集的行的文件。这些行将按原样从数据文件复制到此错误文件中。
今天的总结就到这里了,希望可以给大家带来一些帮助,如果有不对的地方,还请大家多多指教!