最近帮一个客户搭建跨洋的合并复制,由于数据库非常大,跨洋网络条件不稳定,因此只能通过备份初始化,在初始化完成后向海外订阅端插入数据时发现报出如下错误:
Msg 548, Level 16, State 2, Line 2 The insert failed. It conflicted with an identity range check constraint in database %s, replicated table %s, column %s. If the identity column is automatically managed by replication, update the range as follows: for the Publisher, execute sp_adjustpublisheridentityrange; for the Subscriber, run the Distribution Agent or the Merge Agent.
原因?
在SQL Server中,对于自增列的定义是对于每一条新插入的行,都会自动按照顺序新生成一个递增的数字,改数字通常和业务无关且被用于作为主键。但如果该表用于可更新事务复制或者合并复制,那么该自增列的区间范围则由复制管理。
此时,复制可以保证自增列可控,因为复制代理插入行时不会导致自增列自增,只有用户显式插入时才会导致自增列自增。
让我们来做一个实验。首先创建表,表定义如下:
CREATE TABLE [dbo].[Table_1]( [c1] [int] IDENTITY(1,1), [c2] [int] NULL, [ROWGUID] [uniqueidentifier] NOT NULL, [rowguid4] [uniqueidentifier] ROWGUIDCOL NOT NULL, CONSTRAINT [PK_Table_1] PRIMARY KEY CLUSTERED ( [c1] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
此时我们对创建合并复制,并把该表包含在内,并使用快照代理初始化复制,当完成该步骤时,我们发现该表上自动多了两个约束,如图1所示。
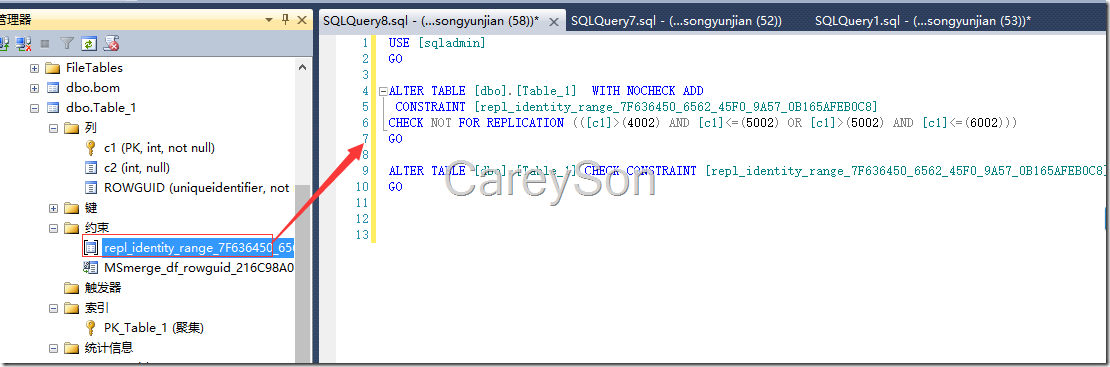
图1.合并复制所加的约束
我们看到该约束的定义只允许4002到5002以及5002到6002之间的数据被插入。
此时如果出现了一些BUG或者人为改动了该表自增列种子的值,则会报错,如图2所示。

图2.改动种子值导致插入数据出错
该约束会由合并代理自动递增,比如说我们用如下代码插入2000条数据,则发现该约束会自动递增如图3所示。
DECLARE @index INT=1 WHILE @index<2000 BEGIN INSERT INTO table_1(c2,ROWGUID) VALUES(2,NEWID()) SET @index=@index+1 END

图3.约束区间自动递增滑动
解决办法
此时我已经找出了上面报错的原因,因为是由于从备份初始化,那么备份以及备份传输期间发布库又有新的数据插入,此时发布库比如说,该表的种子大小已经增加到了6000,而备份中该表大小还是5000,而约束已经滑动到了6000,那么在订阅端插入数据时就会发生这种问题(意思就是说订阅端的备份表种子还在5000,但是备份表的约束已经到了6000,这时在订阅端的备份表中插入一条5000多的值肯定会报错,因为违反了约束)。
再举一个例子,如本文前面所述,实际上合并复制中订阅端的自增列是由复制管理来控制的,复制代理在订阅端插入行时,自增列都是设置"SET IDENTITY_INSERT [表名] ON"后,通过指定值来插入的。而实际上订阅端表自增列的种子会是一个比较大的值,例如下面这个Person表是订阅端的一张表(ID列是自增列),我们可以看到其内部只有5条数据,是通过合并复制从发布端同步过来的:
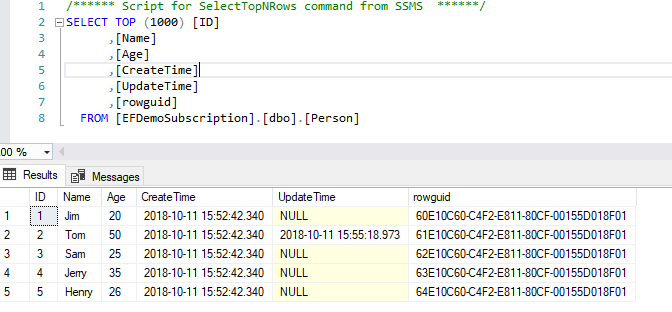
但是我们可以看到其自增列ID的种子已经高达2006:
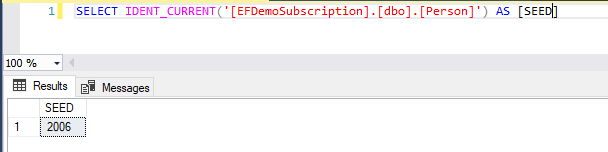
这就是因为Replication的复制管理将订阅端Person表的种子设置为了2006,所有由用户显式插入订阅端Person表的数据,其ID列都会从2006开始。
这时我们在发布端的Person表中插入10000多行数据,然后启动复制代理将其同步到订阅端的Person表,可以看到订阅端的Person表ID已经增长到35103:
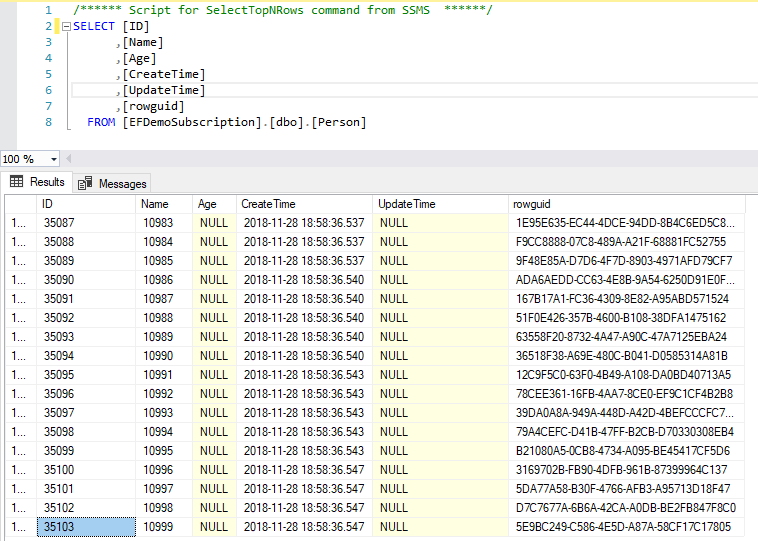
但是合并复制同步发布端和订阅端数据后,不会更新订阅端Person表的种子值,导致订阅端Person表的种子值还是2006:
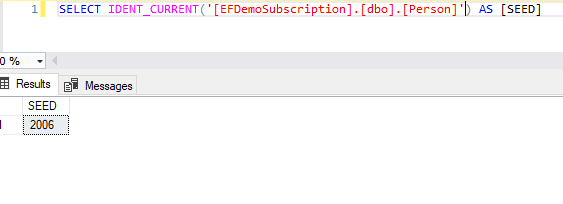
最关键的问题是订阅端Person表的约束也没有更新,还是在10000以下的(合并复制会给表的自增列预留一段ID值,所以10000以下的ID值在发布端和订阅端的Person表中都是没有使用的)。
那么这时用户显式插入大量数据(假如100000行)到订阅端Person表中,其ID列还是会从2006开始,会导致违反订阅端Person表的约束(因为约束值在10000以下,100000行数据会使ID列自增超过约束值),所以就会产生本文最上面所述的错误。
但是在合并复制的发布端没有这个问题,因为发布端Person表的约束值会随着数据的插入自动向后滑动,但是订阅端Person表的约束值就不会滑动,除非和发布端进行一次同步。
此外如果取消合并复制订阅端数据库的订阅,订阅端数据库中所有合并复制的约束会被删除,所有表中合并复制创建的RowGuid列也会被删除,并且Person表的种子值会被设置为当前ID列的最大值35103,这时随便怎么往订阅端数据库的Person表中插入数据都是没有问题的了。
解决办法1
在发布端使用sp_adjustpublisheridentityrange 存储过程使得约束范围自动向后滑动,比如从6000-8000滑动到8000-10000。缺点自增值之间会有一个GAP。如果业务允许,推荐使用该做法。
sp_adjustpublisheridentityrange @table_name='表名称'
解决办法2
在发布端运行SELECT IDENT_CURRENT('表名称'),找到发布表的种子值。在订阅端通过DBCC CHECKIDENT (表名称,RESEED, 设置为上面值)命令将两端种子值设置为一致。
解决办法3
在订阅端运行合并代理,即可修复数据。如果此方法不行,则再次尝试上述方法。
解决办法4
不用自增列,而使用GUID列,但这涉及到表结构以及程序的修改,而且需要重新初始化复制,因此不是每一个环境都有条件这么做。
这里个人建议在Replication的合并复制中,如果数据库表中有自增列(IDENTITY),这种情况下,最好不要让用户显式更改订阅端的数据库数据,所有的数据更新都来自发布端是最安全的。
另外顺便补充下,如果在Replication的合并复制中,发布端数据库新建了表或其它对象,将其添加到合并复制的发布后,需要重新在发布端生成新的快照后,才能将新加的表或对象同步到订阅端数据库中。