一、前言
在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。

(Figure0:索引与基表对齐)
二、解读
“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:
1) 分区函数的参数具有相同的数据类型;
2) 分区函数定义了相同数目的分区;
3) 分区函数为分区定义了相同的边界值。”
下面我们进行测试:
--1.创建文件组 ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_Id_01] ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_Id_02] ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_Id_03] --2.创建文件 ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_Id_01_data',FILENAME = N'E:DataBaseFG_TestUnique_Id_01_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_Id_01]; ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_Id_02_data',FILENAME = N'E:DataBaseFG_TestUnique_Id_02_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_Id_02]; ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_Id_03_data',FILENAME = N'E:DataBaseFG_TestUnique_Id_03_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_Id_03]; --3.创建分区函数 CREATE PARTITION FUNCTION Fun_TestUnique_Id(INT) AS RANGE RIGHT FOR VALUES(10000000,20000000) --4.创建分区方案 CREATE PARTITION SCHEME Sch_TestUnique_Id AS PARTITION Fun_TestUnique_Id TO([FG_TestUnique_Id_01],[FG_TestUnique_Id_02],[FG_TestUnique_Id_03])
上面的SQL脚本创建了分区函数:Fun_TestUnique_Id(INT)和分区方案:[Sch_TestUnique_Id]。下面我们创建类似的分区函数:Fun_TestUnique_SiteId(INT)和分区方案:[Sch_TestUnique_SiteId]。这两个函数完全符合上面提到的3个条件:
1) 分区函数的参数具有相同的数据类型;(都是Int类型)
2) 分区函数定义了相同数目的分区;(都是3个分区)
3) 分区函数为分区定义了相同的边界值。”(边界值都是10000000,20000000)
--1.创建文件组 ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_SiteId_01] ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_SiteId_02] ALTER DATABASE [Test] ADD FILEGROUP [FG_TestUnique_SiteId_03] --2.创建文件 ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_SiteId_01_data',FILENAME = N'E:DataBaseFG_TestUnique_SiteId_01_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_SiteId_01]; ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_SiteId_02_data',FILENAME = N'E:DataBaseFG_TestUnique_SiteId_02_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_SiteId_02]; ALTER DATABASE [Test] ADD FILE (NAME = N'FG_TestUnique_SiteId_03_data',FILENAME = N'E:DataBaseFG_TestUnique_SiteId_03_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_TestUnique_SiteId_03]; --3.创建分区函数 CREATE PARTITION FUNCTION Fun_TestUnique_SiteId(INT) AS RANGE RIGHT FOR VALUES(10000000,20000000) --4.创建分区方案 CREATE PARTITION SCHEME Sch_TestUnique_SiteId AS PARTITION Fun_TestUnique_SiteId TO([FG_TestUnique_SiteId_01],[FG_TestUnique_SiteId_02],[FG_TestUnique_SiteId_03])
接下来创建一个以这个分区方案进行分区的表[TestUnique];这个表的聚集索引是创建在分区方案:[Sch_TestUnique_Id]上的。接着创建一个唯一索引:[IX_TestUnique_SiteIdUrl]是创建在分区方案[Sch_TestUnique_SiteId]上的。那么这个唯一索引跟基表是对齐的嘛?
--5.创建分区表 CREATE TABLE [dbo].[TestUnique]( [Id] [int] IDENTITY(600000000,1) NOT FOR REPLICATION NOT NULL, [SiteId] [int] NULL, [Url] [nvarchar](420) NULL, [PublishOn] [datetime] NULL, [AddOn] [datetime] NULL, CONSTRAINT [PK_Archive] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = ON, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 100) ON [Sch_TestUnique_Id]([Id]) ) ON [Sch_TestUnique_Id]([Id]) GO --6.创建唯一索引 CREATE NONCLUSTERED INDEX [IX_TestUnique_SiteIdUrl] ON [dbo].[TestUnique] ( [SiteId] ASC, [Url] ASC )WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [Sch_TestUnique_SiteId]([SiteId]) GO
其实很明细,这个唯一索引[IX_TestUnique_SiteIdUrl]与基表是不对齐的,因为他们使用了不同的字段,一个是Id值,一个是SiteId值,很简单,因为Id为10000000的时候SiteId不一定也是10000000,所以他们没有办法对齐的;只要你进行一些切换分区就知道:
--插入测试数据 SET IDENTITY_INSERT [TestUnique] ON INSERT INTO [TestDB].[dbo].[TestUnique] ([Id],[SiteId],[Url] ,[PublishOn] ,[AddOn]) VALUES (10000010,10000009,'http://baidu.com',getdate(),getdate()) INSERT INTO [TestDB].[dbo].[TestUnique] ([Id],[SiteId],[Url] ,[PublishOn] ,[AddOn]) VALUES (20000010,20000008,'http://baidu.com',getdate(),getdate()) SET IDENTITY_INSERT [TestUnique] OFF --创建切换分区临时表 CREATE TABLE [dbo].[Temp_TestUnique]( [Id] [int] IDENTITY(600000000,1) NOT FOR REPLICATION NOT NULL, [SiteId] [int] NULL, [Url] [nvarchar](420) NULL, [PublishOn] [datetime] NULL, [AddOn] [datetime] NULL, CONSTRAINT [PK_TempArchive] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = ON, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 100) ON [Sch_TestUnique_Id]([Id]) ) ON [Sch_TestUnique_Id]([Id]) GO CREATE NONCLUSTERED INDEX [IX_TestUnique_SiteIdUrl] ON [dbo].[Temp_TestUnique] ( [SiteId] ASC, [Url] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_TestUnique_SiteId]([SiteId]) GO --切换分区 ALTER TABLE [dbo].[TestUnique] SWITCH PARTITION 2 TO [dbo].[Temp_TestUnique] PARTITION 2
执行上面的切换分区SQL会报下面的错误:
消息4912,级别16,状态1,第2 行
'ALTER TABLE SWITCH' 语句失败。用于对表'Test.dbo.TestUnique' 进行分区的列集与用于对索引'IX_TestUnique_SiteIdUrl' 进行分区的列集不同。
[Sch_TestUnique_Id]([Id])与[Sch_TestUnique_SiteId]([SiteId])是属于不同的字段分区,如果换成[Sch_TestUnique_Id]([Id])与[Sch_TestUnique_SiteId]([Id]),虽然分区方案的名称不同,但是实质是一样的(参考上面3个条件的描述),这种情况我们也说索引与基表对齐了,可以进行切换分区了。下面是执行切换分区的效果图:

(Figure1:交换分区前)
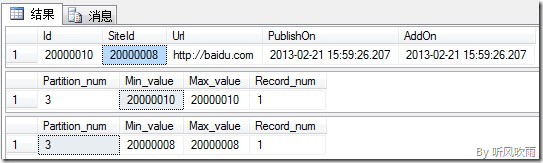
(Figure2:交换分区后)
(Figure3:分区文件)
总结:使用不同的分区方案进行对齐的好处是让数据与索引分开存储,存储到不同的文件,但是它又是符合基表与索引是对齐,同时方便使用切换分区进行历史数据归档;
“先设计一个已分区表,然后为该表创建索引。执行此操作时,SQL Server 将使用与该表相同的分区方案和分区依据列自动对索引进行分区。因此,索引的分区方式实质上与表的分区方式相同。这将使索引与表“对齐”。
如果在创建时指定了不同的分区方案或单独的文件组来存储索引,则 SQL Server 不会将索引与表对齐。“
不同的分区方案并不是指不同的分区方案名,而是指不一样的分区方案结构。
三、参考文献