基础:查找的基本概念
查找表:由同一类数据元素构成的集合。(线性表、数表、散列表)
关键字:是数据元素中某个数据项的值,用它可以表示一个数据元素。(主关键字:唯一地标识;次关键字:不唯一地标识)
查找:根据制定的某个值,在查找表中确定一个其关键字等于给定的这个值的数据元素
动态/静态查找:查表的同时改表成为动态查找,反之为静态查找
平均查找长度:ASL=∑PiCi (i=1,2,3,…,n),Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
*线性表的查找*
(1)顺序查找
(2)二分查找(折半查找)
(3)分块查找
(1)顺序查找
从表的一端开始,依次将记录的关键字与给定的值进行比较。
顺序查找既适用于顺序存储结构(数组),又适用于链式存储结构(链表),以下介绍顺序存储结构:
数据元素的类型:
1 typedef struct{
2 KeyType key;
3 InfoType otherinfo
4 }ElemType
1 typedef struct {
2 ElemType *R; //表基址
3 int length; //表长
4 }SSTable;
代码:
1 int LocateELem(SqList L,ElemType e)
2 { for (i=0;i< L.length;i++)
3 if (L.elem[i]==e) return i+1;
4 return 0;
5 }
改进:把待查关键字key存入表头(“哨兵”),从后向前逐个比较,可免去查找过程中每一步都要检测是否查找完毕,加快速度。
1 int Search_Seq( SSTable ST , KeyType key ){
2 //若成功返回其位置信息,否则返回0
3 ST.R[0].key =key;
4 for( i=ST.length; ST.R[ i ].key!=key; - - i );
5 //不用for(i=n; i>0; - -i) 或 for(i=1; i<=n; i++)
6 return i;
7 }
顺序查找的性能分析:
空间复杂度:一个辅助空间。
时间复杂度:
1) 查找成功时的平均查找长度 设表中各记录查找概率相等 ASLs(n)=(1+2+ ... +n)/n =(n+1)/2
2)查找不成功时的平均查找长度 ASLf =n+1
(2)二分查找
例:找“21”:

若k==R[mid].key,查找成功
若k<R[mid].key,则high=mid-1
若k>R[mid].key,则low=mid+1
代码:(迭代)
1 int Search_Bin(SSTable ST,KeyType key){ 2 low=1;high=ST.length;//若找到,则函数值为该元素在表中的位置,否则为0 3 while(low<=high){ 4 mid=(low+high)/2; 5 if(key==ST.R[mid].key) return mid; 6 else if(key<ST.R[mid].key) high=mid-1;//前一子表查找 7 else low=mid+1; //后一子表查找 8 } 9 return 0; //表中不存在待查元素 10 }
*需要特别注意的是循环执行的条件是:low<=high,而不是low<high,因为low=high时,还要比较最后一个元素。
代码:(递归)
1 int Search_Bin (SSTable ST, keyType key, int low, int high)
2 {
3 if(low>high) return 0; //查找不到时返回0
4 mid=(low+high)/2;
5 if(key等于ST.elem[mid].key) return mid;
6 else if(key小于ST.elem[mid].key)
7 ……..//递归
8 else……. //递归
9 }
二分查找的性能分析——判定树

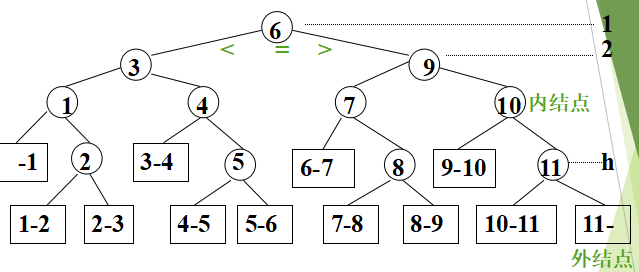
若所有结点的空指针域设置为一个指向一个方形结点的指针,称方形结点为判定树的外部结点;对应的,圆形结点为内部结点。
查找成功时的平均查找长度:ASL=1/11*(1*1+2×2+4×3+4*4 )=33/11=3
查找成功时比较次数:为该结点在判定树上的层次数,不超过树的深度 d = [log2n] + 1 查找不成功的过程就是走了一条从根结点到外部结点的路径d或d-1。
二分查找的性能分析:
查找过程:每次将待查记录所在区间缩小一半,比顺序查找效率高,时间复杂度O(log2 n)
适用条件:采用顺序存储结构的有序表,不宜用于链式结构
(3)分块查找
分块有序,即分成若干子表,要求每个子表中的数值都比后一块中数值小(但子表内部未必有序)。 然后将各子表中的最大关键字构成一个索引表,表中还要包含每个子表的起始地址(即头指针)。
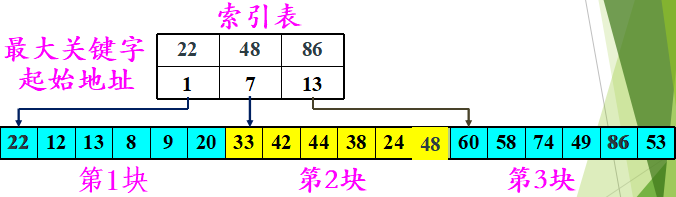
① 对索引表使用折半查找法(因为索引表是有序表);
② 确定了待查关键字所在的子表后,在子表内采用顺序查找法(因为各子表内部是无序表);
查找效率:ASL=Lb+Lw(Lb:对索引表查找的ASL;Lw:对块内查找的ASL)
分块查找的性能分析:
优点:插入和删除比较容易,无需进行大量移动。
缺点:要增加一个索引表的存储空间并对初始索引表进行排序运算。
适用情况:如果线性表既要快速查找又经常动态变化,则可采用分块查找。