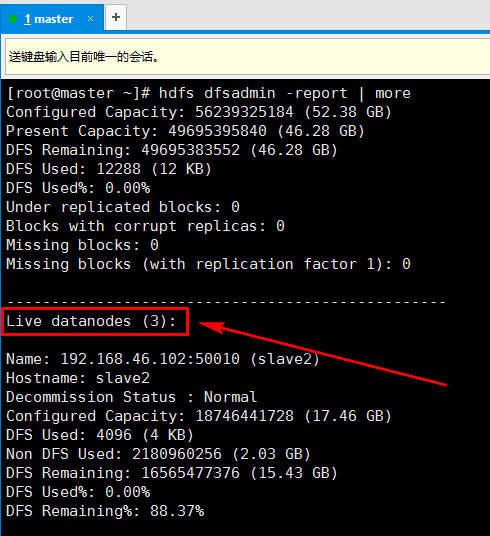
1. 启动namenode和datanode,在master上输入命令hdsf dfsadmin -report查看整个集群的运行情况(记得关闭防火墙)
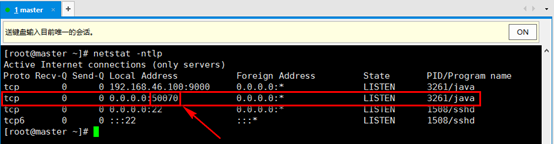
2. 输入命令查看hadoop监听的端口,netstat -ntlp
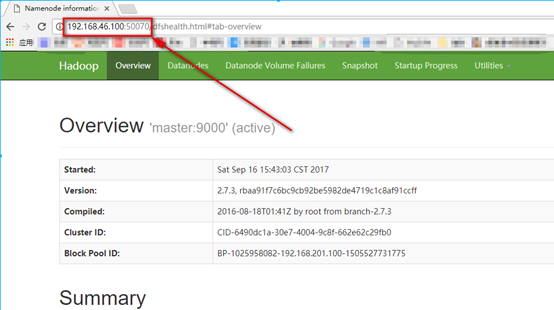
3. 在宿主机浏览器输入{masterIP}:50070进行查看
4. 关闭集群
master机器命令:hadoop-daemon.sh stop namenode
slave机器命令:hadoop-daemon.sh stop datanode
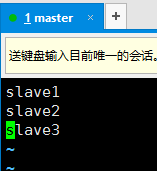
5. 创建集中式管理,在master机器上操作。输入命令
vim /usr/local/hadoop/etc/hadoop/slaves
6. 经过上一个步骤的操作后,可以在master机器上,集中的管理控制namenode和所有的datanode。在master机器上,启动所有的hadoop服务,输入命令start-dfs.sh,输入相应的密码,然后输入jps查看(该命令会默认启动SecondaryNameNode)
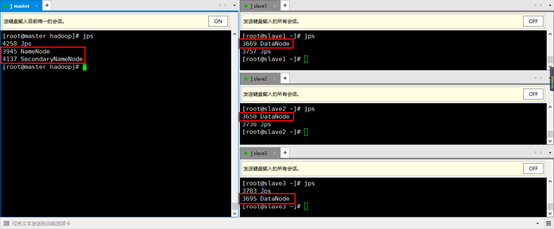
7. 步骤6的时候,需要输入很多密码,下面设置免密登录:
a). 在master机器中进入~/.ssh目录:cd ~/.ssh/
b). 输入ssh-keygen -t rsa,然后一直敲回车
c). 命令结束后,该目录下会多出两个文件

id_rsa为当前root用户的私钥,id_rsa.pub是公钥
d). 将公钥拷贝到所有的datanode机器上,这样,当master机器拿着经过私钥加密的登录信息发送到datanode机器的时候,datanode机器里存储的公钥可以解开,证明是该用户登录,因此就能够实现免密码登录。
e). 拷贝id_rsa.pub的方法,在master机器上输入命令ssh-copy-id slave1,输入密码,即可将公钥拷贝至slave1机器中。
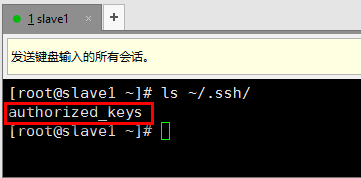
f). 去到slave1机器的~/.ssh目录下查看,有authorized_keys文件表示拷贝成功
g). 回到master机器上,输入ssh slave1进行远程登录,发现不用输入密码即可登录成功,即实现了免密登录。
h). 同理,将id_rsa.pub文件拷贝到其他datanode机器上,并且,也给自己拷贝一份,即拷贝一份到master机器上。
8. 停止集群stop-dfs.sh
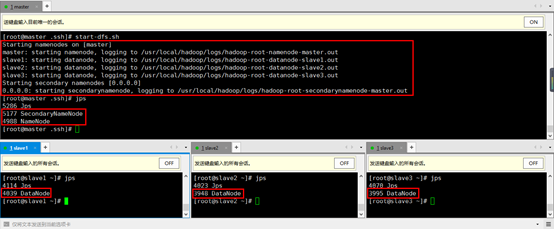
9. 再次启动集群start-dfs.sh发现不用输入密码了
10. 查看hadoop根目录下的文件hadoop fs -ls /(也可将hadoop fs替换为hdfs dfs,目前集群刚刚创建,目录为空,此外,删除等命令跟linux命令类似,例如hdfs dfs -rm -r -f /a.txt,其他hdfs命令可以去找度娘和谷老师)
11. 上传一个文件到hadoop(master机器上操作)
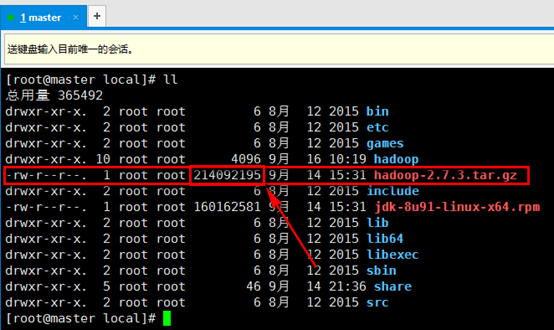
a). 上传/usr/local目录下的hadoop-2.7.3.tar.gz文件,hadoop默认的block为128M,该文件为214M,因此会被分块。
b). 输入命令hadoop fs -put ./hadoop-2.7.3.tar.gz /,前面的./hadoop-2.7.3.tar.gz为上传的文件本地的存放路径,后边的/为存放到hadoop的路径。
c). 输入hadoop fs -ls /查看刚刚上传的文件
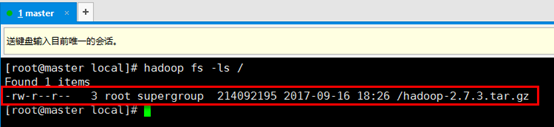
d). 通过网页查看刚才上传的文件,点击Utilsities->Borwse the file system
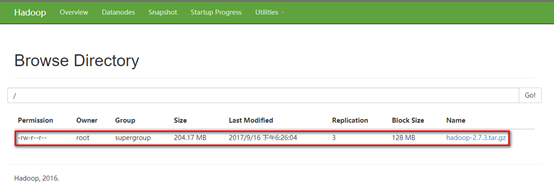
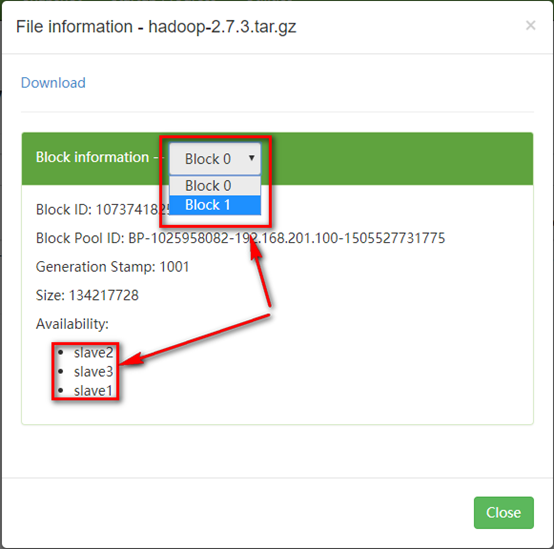
e). 点击该文件,发现该文件被分成了两个块。并且每块复制了三份保存在了datanode当中。
12. hadoop分块后,默认会把块复制三份,以便在出现特殊情况的时候进行恢复,这个数字可以修改,下面就将这个默认复制三份改成两份。(在master机器上进行修改)
a). 编辑/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件,在configuration节点中添加如下内容

具体的配置说明,可查看hadoop安装目录下hadoop-2.7.3/share/doc/hadoop/index.html文件

b). 关闭集群stop-dfs.sh,启动集群start-dfs.sh(重启hadoop)
c). 根据上述,将jdk的安装文件上传到集群当中,登录网页观察。

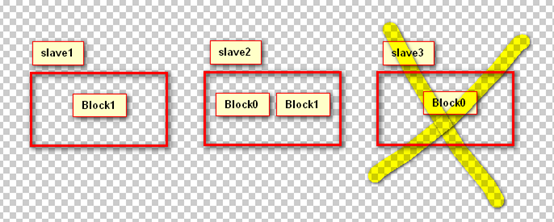
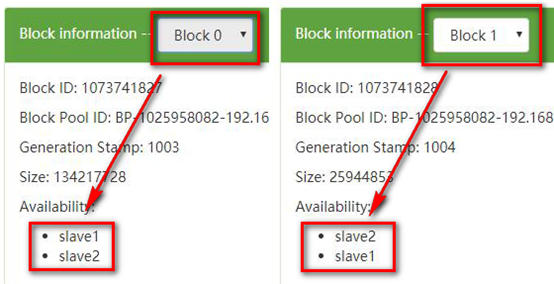
通过上图发现,上传的文件被分割成了两个block块,其中Block0放在了slave2和slave3上边,Block1放在了slave1和slave2上边,此时,如果我们干掉slave3,即如下图所示,那么Block0就只剩下一份了,而我们的配置文件当中设置的是两份,我们测试一下hadoop会不会再帮我们复制一份出来(答案是会,这就是自动冗余)。
d). 在进行上述实验之前,我们还要配置一个选项

该属性表示,hadoop在多少时间间隔后对datanode进行一次检测,检测它们是否宕机,单位是毫秒,默认为300000,也就是5分钟,我们修改成小一点的值,不然还要等待漫长的5分钟。同样修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件,将值改为10000,即10秒钟,然后重新启动hadoop。
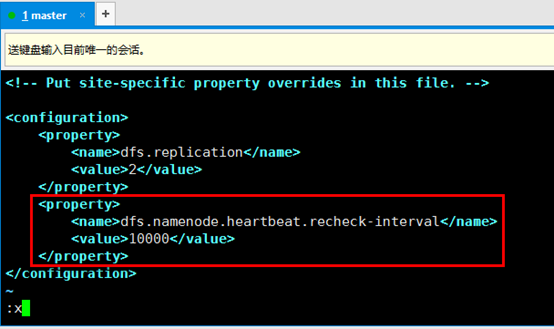
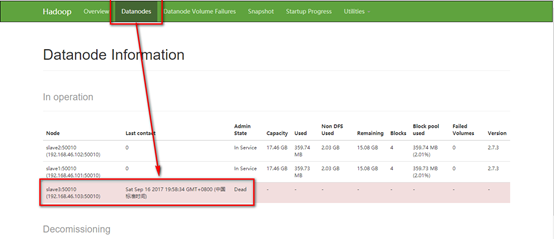
e). 在slave3机器上,关闭hadoop服务:hadoop-daemon.sh stop datanode,默默的等待10秒钟,9、8、7、6。。。
f). 去到网页观察slave3确认已经死亡
g). 再次查看jdk文件的情况,发现Block0又在slave1当中被复制了一份,验证了上述的结果。
13. 思考:此时再次启动slave3,而slave3里有一份Block0备份,那么这样的话Block0就一共有三份备份了,而我们配置的是两个备份,考虑这个时候启动slave3,会不会删掉一份Block0呢?