1. 启动hadoop服务。
2. hadoop默认将数据存储带/tmp目录下,如下图:

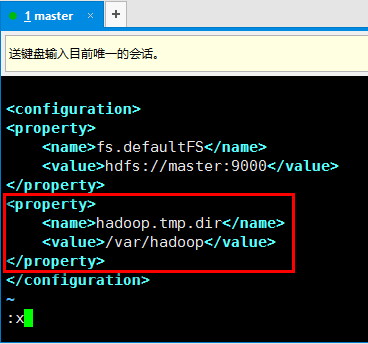
由于/tmp是linux的临时目录,linux会不定时的对该目录进行清除,因此hadoop可能就会出现意外情况。下面对这个配置进行修改。修改core-site.xml文件vim /usr/local/hadoop/etc/hadoop/core-site.xml将这个值修改到/var/hadoop目录下
3. 修改完毕后,重启hadoop服务(stop-dfs.sh、start-dfs.sh),然后重新格式化namenode
hdfs namenode -format
4. 使用java来操作hdfs
5. 新建java项目,导入如下几个包:
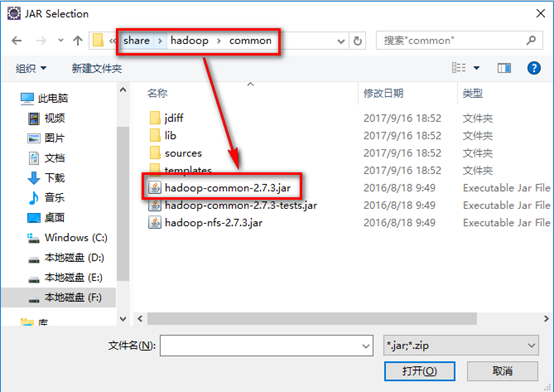
a). hadoop安装目录下share/hadoop/common下的common包
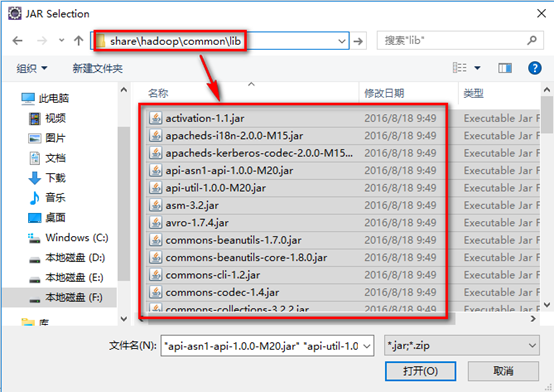
b). hadoop安装目录下share/hadoop/common/lib下的所有包
c). hadoop安装目录下share/hadoop/hdfs下的hdfs包
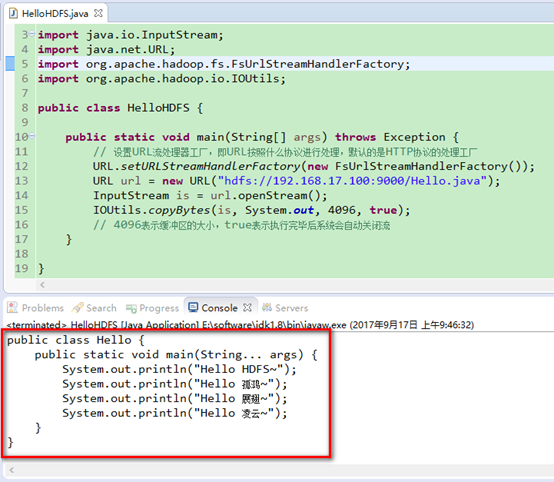
6. 新建java类HelloHDFS.java,测试java程序读取hadoop当中存储的文件。现在我的hadoop集群根目录当中有一个Hello.java文件,下面用java程序来读取它。
1 import java.io.InputStream; 2 import java.net.URL; 3 import org.apache.hadoop.fs.FsUrlStreamHandlerFactory; 4 import org.apache.hadoop.io.IOUtils; 5 6 public class HelloHDFS { 7 public static void main(String[] args) throws Exception { 8 // 设置URL流处理器工厂,即URL按照什么协议进行处理,默认的是HTTP协议的处理工厂 9 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); 10 URL url = new URL("hdfs://192.168.17.100:9000/Hello.java"); 11 InputStream is = url.openStream(); 12 IOUtils.copyBytes(is, System.out, 4096, true); 13 // 4096表示缓冲区的大小,true表示执行完毕后系统会自动关闭流 14 } 15 }
7. 运行上述程序,观察结果,发现已经读取到了hadoop当中存储文件。
8. 上述为方式一,下面介绍一种更好用的方式。
1 // 方式二: 2 Configuration conf = new Configuration(); 3 conf.set("fs.defaultFS", "hdfs://192.168.17.100:9000"); 4 FileSystem fs = FileSystem.get(conf); 5 boolean success = fs.mkdirs(new Path("/skyer")); 6 System.out.println(success);
上述代码为在hadoop根目录下创建一个skyer目录(如果原来就有该目录,会覆盖),并打印创建结果,结果为true。若出现下图错误:
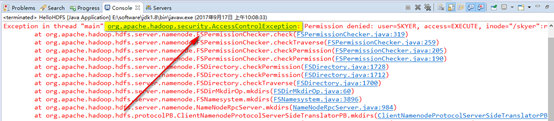
在core-site.xml文件中将dfs.permissions.enabled配置为false,或者输入以下命令hadoop fs -chmod 777 /修改hadoop根目录的权限(危险,不推荐),还有一个方法是在windows机器上配置一个环境变量HADOOP-USER_NAME,还有一种方法是将
FileSystem fs = FileSystem.get(conf);
替换成
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.17.100:9000"),conf,"root");
9. 其他操作hadoop的示例,直接看代码:
1 public class HelloHDFS { 2 public static void main(String[] args) throws Exception { 3 // 方式二: 4 Configuration conf = new Configuration(); 5 conf.set("fs.defaultFS", "hdfs://192.168.17.100:9000"); 6 FileSystem fs = FileSystem.get(conf); 7 boolean success = fs.mkdirs(new Path("/skyer")); // 创建目录 8 System.out.println(success); 9 success = fs.exists(new Path("/skyer")); // 判断文件或者目录是否存在 10 System.out.println(success); 11 12 success = fs.delete(new Path("/skyer"), true); 13 // 删除,第二个参数为true的话会真正的删除文件,为false的话是将该文件放到垃圾桶里 14 System.out.println(success); 15 16 // 上传文件到hadoop 17 FSDataOutputStream out = fs.create(new Path("/upload.data"), true); 18 FileInputStream fis = new FileInputStream("E://HelloHDFS.java"); 19 IOUtils.copyBytes(fis, out, 4096, true); 20 21 // 列取目录下所有文件和目录的信息 22 FileStatus[] statuses = fs.listStatus(new Path("/")); 23 for (FileStatus status : statuses) { 24 System.out.println(status.getPath()); 25 System.out.println(status.getPermission()); 26 System.out.println(status.getReplication()); 27 } 28 } 29 }
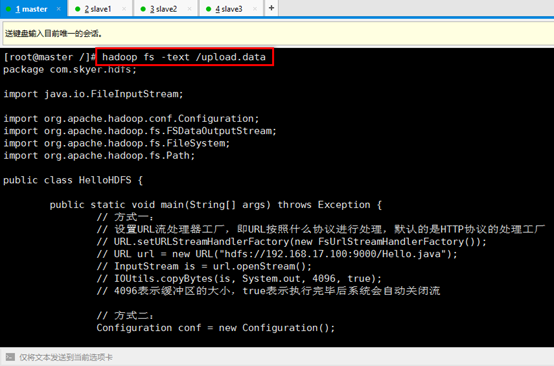
10. 在master机器上输入命令hadoop fs -text /upload.data进行查看示例中上传的文件,类似linux里的cat命令