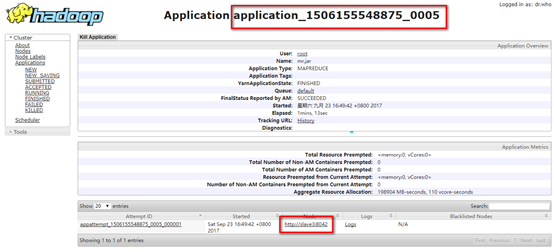
1. MapReduce的流程图(摘自马士兵老师视频),我们开发的就是其中的这两个(红框)过程。简述一下这个图,input就是我们需要处理的文件(datanode上文件的一个分块);Split就是将这个文件进行拆分,默认的就是按照行来拆分,拆分的结果是一个key-value对,key是这一行起始的位置,value就是这一行的内容;map是我们需要开发的内容,也就是对这一行数据的处理,产生的结果也是一个key-value对;shuffle是把上一步处理后的数据进行一个汇总,把同样的key合并到一起,把所有的value放到一个容器里;reduce缩减,就是将上一步容器里的值进行求和,也是一个key-value对;output就是输出。

2. 如果是在windows机器上进行开发,需要对环境进行一些配置:
a). 首先添加hadoop的环境变量HADOOP_HOME指向hadoop的安装目录:
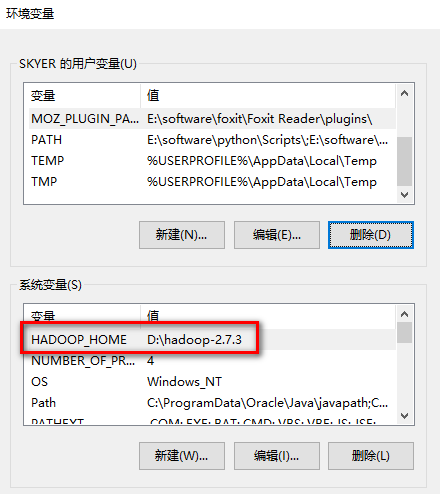
b). 把HADOOP_HOME/bin加到PATH环境变量(非必要)
c). 覆盖HADOOP_HOME/bin(到此处https://github.com/srccodes/hadoop-common-2.2.0-bin下载bin文件)
d). 将hadoop.dll复制到c:windowssystem32目录下(重启电脑)
3. 新建java项目,引入相应的jar包,jar包都位于HADOOP_HOME目录下的share/hadoop中,以下是jar清单:
a). common下hadoop-common-2.7.3.jar,已经common/lib下所有jar包。
b). hdfs下所有jar包,以及hdfs/lib下所有jar包。
c). mapreduce下所有jar包,以及mapreduce/lib下所有jar包。
d). yarn下所有jar包,以及yarn/lib下所有jar包。
4. 编写map层代码,新建WordMapper.java类:
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 9 @Override 10 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { 11 final IntWritable ONE = new IntWritable(1); 12 String s = value.toString(); 13 String[] words = s.split(" "); 14 for (String word : words) { 15 context.write(new Text(word), ONE); 16 } 17 } 18 }
5. 编写reduce层代码,新建WordReduce.java文件:
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Reducer; 7 8 public class WordReduce extends Reducer<Text, IntWritable, Text, LongWritable> { 9 @Override 10 protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context content) throws IOException, InterruptedException { 11 long count = 0; 12 for (IntWritable v : values) { 13 count += v.get(); 14 } 15 content.write(key, new LongWritable(count)); 16 } 17 }
6. 编程测试层代码,新建Test.java(程序可以在windows独立运行,不用启动hadoop服务)
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Job; 7 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 8 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 9 10 public class Test { 11 public static void main(String[] args) throws Exception { 12 Configuration conf = new Configuration(); 13 14 Job job = Job.getInstance(conf); 15 16 job.setMapperClass(WordMapper.class); 17 job.setReducerClass(WordReduce.class); 18 19 job.setMapOutputKeyClass(Text.class); 20 job.setMapOutputValueClass(IntWritable.class); 21 22 job.setOutputKeyClass(Text.class); 23 job.setOutputValueClass(LongWritable.class); 24 25 FileInputFormat.setInputPaths(job, "E:/input.txt"); 26 FileOutputFormat.setOutputPath(job, new Path("E:/out/")); 27 28 job.waitForCompletion(true); 29 } 30 }
7. 运行测试代码,去到输出目录进行查看:
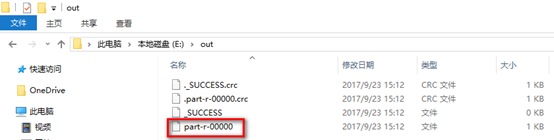
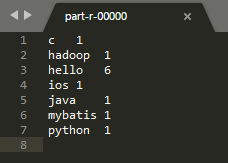
8. 打开该文件,查看运行结果:
9. 下面将这个程序扔到hadoop中运行。
10. 首先在hadoop上准备一个需要处理文件
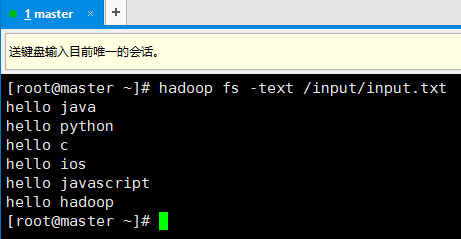
11. 修改测试代码,只要修改两行就好了,然后运行(记得启动hadoop和yarn):
FileInputFormat.setInputPaths(job, "hdfs://192.168.74.100:9000/input");
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.74.100:9000/output"));
12. 在hadoop中查看运行结果
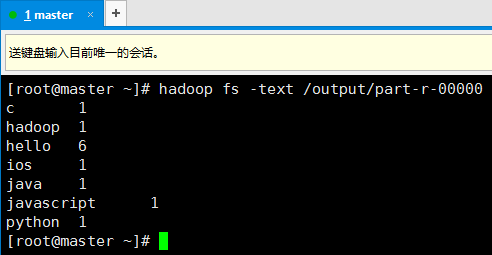
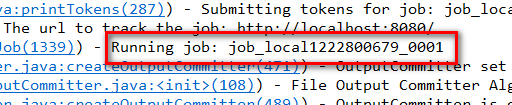
13. 需要注意的是(观看Eclipse的控制台),这个任务仍然是在本地执行的,也就是说,这个程序需要先将需要处理的文件下载的本地,然后再进行处理,显而易见,如果文件很大,这是很不合适的。
14. 我们要做的是将程序给hadoop执行,而不是将datanode的文件下载到本地,然后用本地的程序执行。修改后测试代码如下,注意,这里需要进行两个配置,在windows的host文件中添加master的ip:

然后,将项目打成jar包放到项目根目录下:
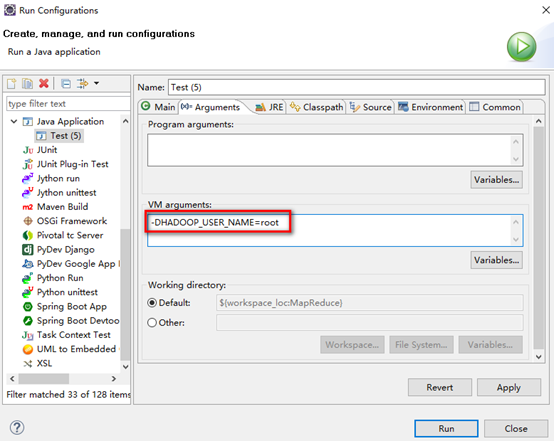
运行的时候,右击测试文件,选择Run Configurations,在Arguments的VM arguments中输入-DHADOOP_USER_NAME=root,然后点击Run
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Job; 7 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 8 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 9 10 public class Test { 11 public static void main(String[] args) throws Exception { 12 Configuration conf = new Configuration(); 13 14 conf.set("fs.defaultFS", "hdfs://192.168.74.100:9000/"); 15 conf.set("mapreduce.job.jar", "mr.jar"); 16 conf.set("mapreduce.framework.name", "yarn"); 17 conf.set("yarn.resourcemanager.hostname", "master"); 18 conf.set("mapreduce.app-submission.cross-platform", "true"); 19 20 Job job = Job.getInstance(conf); 21 22 job.setMapperClass(WordMapper.class); 23 job.setReducerClass(WordReduce.class); 24 25 job.setMapOutputKeyClass(Text.class); 26 job.setMapOutputValueClass(IntWritable.class); 27 28 job.setOutputKeyClass(Text.class); 29 job.setOutputValueClass(LongWritable.class); 30 31 FileInputFormat.setInputPaths(job, "/input/"); 32 FileOutputFormat.setOutputPath(job, new Path("/output2/")); 33 34 job.waitForCompletion(true); 35 } 36 }
15. 查看该任务ID

16. 运行完上述代码,查看测试结果(自行查看),宿主机浏览器查看刚才的任务,发现刚才的任务是在slave3上执行的。