1. 安装hive:上传apache-hive-2.1.1-bin.tar.gz文件到/usr/local目录下,解压后更名为hive。
2. 配置hive环境变量,编辑/etc/profile文件(配置完后记得source /etc/profile使其生效)
3. 配置hive,进入到hive文件夹内,将hive-default.xml.template拷贝一份,命名为hive-site.xml,编辑它,将其中的hive.metastore.schema.verification属性设置为false(内容较多不方便,可是用查找命令,vim在非编辑状态下按/键,然后输入要搜索的内容,回车即可,按小写N键往后翻,按大写N键往前翻)

4. 创建/usr/local/hive/tmp目录,替换${system:java.io.tmpdir}为该目录(vim下使用替换命令,进入命令模式,输入%s#A#B#回车,即为将所有的A替换为B,按照此方式将所有的${system:java.io.tmpdir}替换为/usr/local/hive/tmp)
5. 同理,将所有${system:user.name}替换为登录用户,此处为root(共三处)
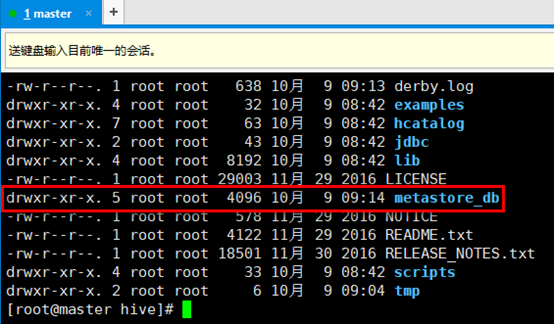
6. 进入/usr/local/hive目录下,执行schematool -initSchema -dbType derby命令。该命令会初始化derby数据库,该数据库中存放的是hive数据库的元数据,实际生产环境中可能用MySQL替换derby数据库,或者其他数据库,不过MySQL使用的较多。执行完该命令后,在hive目录下会多出一个metastore_db文件。(注意!!!下次执行hive时应该还在同一目录,derby默认会到当前目录下寻找metastore。如果遇到问题,把metastore_db删掉,重新执行命令)
7. 启动hive(此时hadoop和yarn也要启动起来),直接输入hive回车即可。
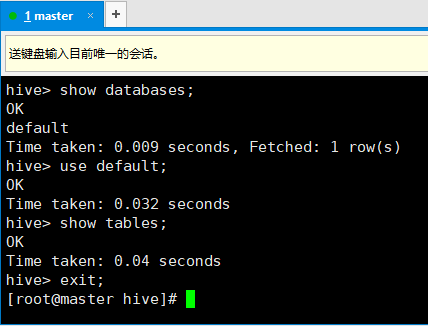
8. 此后的操作和MySQL的命令行差不多:
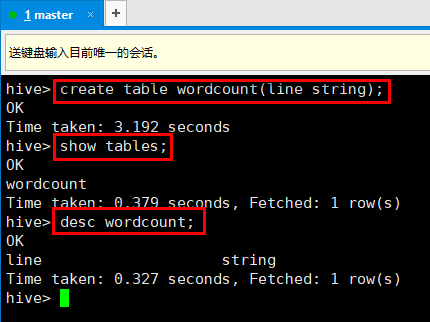
9. 使用hive创建一张表:
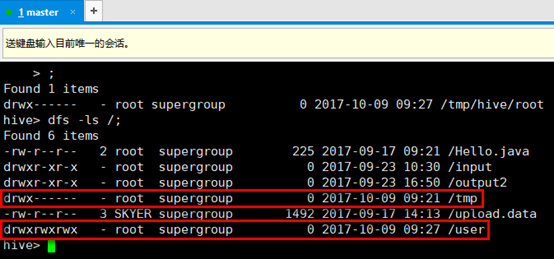
10. 可以直接在hive里执行hadoop语句,观察刚才创建的数据库,红框为刚才创建表时hive创建的目录,其中/user/hive/warehouse目录下有刚才的创建的表的信息。
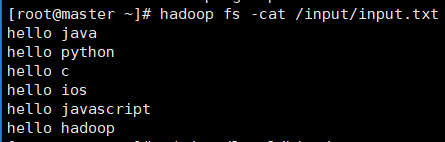
11. 往表里装数据,在hive命令模式下,输入load data inpath '/input/' overwrite into table wordcount;

其中/input/目录下有一个txt文件,内容如下:
12. 上一步操作即为将/input/input.txt这个文件和wordcount这张表建立一个关联,查询这张表的时候,就会通过hdfs查询到该文件的内容。
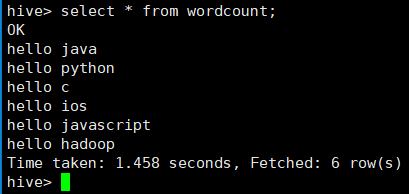
13. 下面使用hive执行上一节中wordcount程序,直接在hive命令模式写输入:select word, count(*) num from (select explode(split(line, ' ')) as word from wordcount) w group by word;其中,split为分割,即将line字段按照空格进行分割,expode函数的作用是,将数组中每一个元素作为单独的一行进行输出。该sql语句的执行结果如下图:
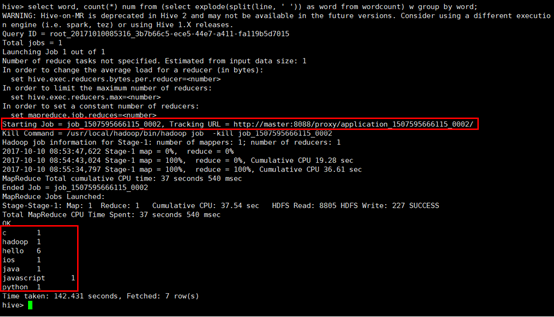
可以看出,该sql语句实际上执行MapReduce成功,开启了一个job,和上一节中编写的java代码是一个效果。
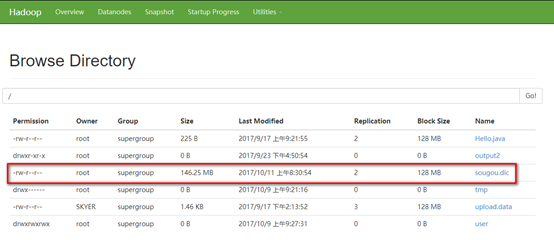
14. 下面用hive分析一个实际当中的日志文件,将该文件上传至hadoop根目录(该文件为搜狗的搜索日志文件)
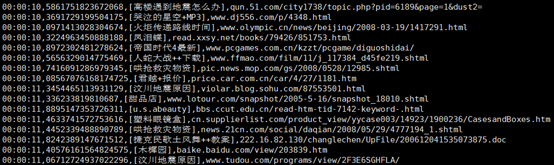
该文件的内容大致如下图,其格式为搜索时间+搜索ID+搜索内容+结果URL,期间都是用逗号隔开。
15. 创建一张表,用来装载sougou.dic的数据,然后对这张表进行操作。进入hive命令模式,输入命令:
create table sougou (qtime string, qid string, qword string, url string) row format delimited fields terminated by ',';
其中,row format delimited fields terminated by ','表示将每一行用逗号进行分割,分别作为一个字段。
16. 装载数据,将sougou.dic里的数据装载到刚才创建的表里(不是将里边的内容装载到了表里,而是在它们两者之间建立了一种联系)。输入命令:
load data inpath '/sougou.dic' into table sougou;
17. 下面就可以通过这个张表来操作这个日志文件了,先统计一下一共有多少条记录(由于这个日志文件有146M,而hadoop默认块大小为128M,因此操作这张表的时候一般会启动MapReduce程序),输入select count(*) from sougou;观察结果:
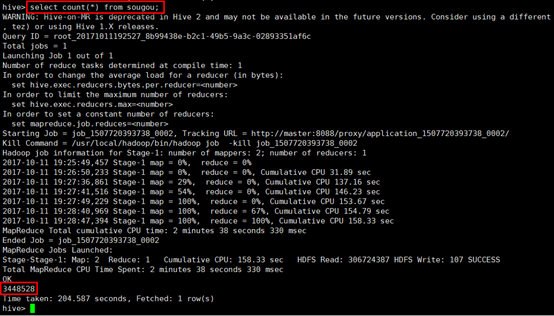
18. 下面来查询热搜榜,首先创建一张表,用来记录搜索的关键字和该关键字的搜索次数,按照由大到小排序,输入HQL语句:
create table sougou_results as select keyword, count(1) as count from (select qword as keyword from sougou) t group by keyword order by count desc;
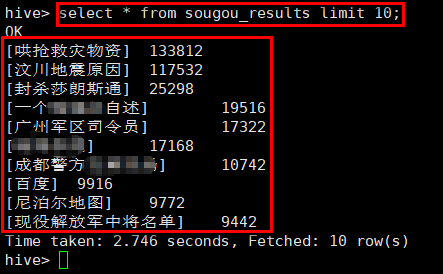
19. 接下来查询热搜榜前十名的搜索记录,输入HQL语句,并观察执行结果:
select * from sougou_results limit 10;