目录
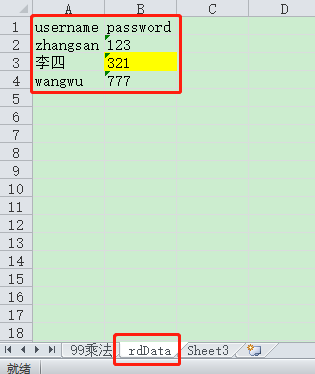
封装读取方法:
import xlrd from selenium import webdriver from selenium.webdriver.common.by import By class rdExcel(): def __init__(self,excel_dir,sheet_name): self.r = [] self.rd = xlrd.open_workbook(excel_dir) self.sh = self.rd.sheet_by_name(sheet_name) #首行设置为key self.key = self.sh.row_values(0) #获取总行数 self.rownum = self.sh.nrows #获取总列数 self.colnum = self.sh.ncols def function(self): if self.rownum<=1: print("没有获取到数值") else: r = [] j=1 #要执行的行数 for i in range(self.rownum - 1): s = {} values = self.sh.row_values(j) for x in range(self.colnum): s[self.key[x]] = values[x] r.append(s) j+=1 # print(r) return r if __name__ == '__main__': a = input("excel_dir:") b = input("sheet_name:") data = rdExcel(a,b) print(data.function())
基本操作:指定单元格读取数据
rd = xlrd.open_workbook("C:\Users\ZHANGCH\Desktop\test99.xlsx") sh = rd.sheet_by_name("rdData") value = sh.row_values(1)[0] driver = webdriver.Chrome() driver.maximize_window() driver.get("http://www.baidu.com") driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(value) driver.find_element(By.CSS_SELECTOR,"#su").click()
============================================================================
写法进行修改规整,完整获取指定数据进行百度查询:
写法①:
import xlrd import os from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep base = os.path.dirname(os.path.dirname(__file__)) base_dir = base.replace('/','\') file_dir = base_dir + os.sep + "test" + os.sep + "test99.xlsx" print(file_dir) class test(): def __init__(self,file_dir,sheet_name): self.rd = xlrd.open_workbook(file_dir) self.sh = self.rd.sheet_by_name(sheet_name) self.rows = self.sh.nrows self.cols = self.sh.ncols def ExcelRd(self): r = [] for i in range(1,self.rows): values = self.sh.row_values(i,0,self.cols) r.append(values) return r if __name__ == '__main__': #指定sheet页为:rdData file_dir = input("路径为:") sheet_name = input("sheet页为:") data = test(file_dir,sheet_name).ExcelRd() driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(10) driver.get("https://www.baidu.com") for footballStar in data: driver.find_element(By.CSS_SELECTOR,"#kw").clear() driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(footballStar[1]) driver.find_element(By.CSS_SELECTOR,"#su").click() sleep(5) driver.quit()
写法②:添加截图方法
function.py:
import os def screenshot(driver,img_name): base = os.path.dirname(os.path.dirname(__file__)) base_dir = base.replace("/","\") img_dir = base_dir + os.sep + "20180515作业" + os.sep + "image" + os.sep + img_name + ".png" driver.get_screenshot_as_file(img_dir)
Excel读取数据.py:
import xlrd import os from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep from function import screenshot class test(object): def __init__(self): self.base = os.path.dirname(os.path.dirname(__file__)) self.base_dir = self.base.replace('/', '\') def ExcelRd(self): file_dir = self.base_dir + os.sep + "20180515作业" + os.sep + "test_xlsx.xlsx" rd = xlrd.open_workbook(file_dir) sh = rd.sheet_by_name("rdData") rows = sh.nrows cols = sh.ncols r = [] for i in range(1,rows): values = sh.row_values(i,0,cols) r.append(values) return r if __name__ == '__main__': data = test().ExcelRd() driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(10) driver.get("https://www.baidu.com") for footballStar in data: fbStar = footballStar[1] driver.find_element(By.CSS_SELECTOR,"#kw").clear() driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(fbStar) driver.find_element(By.CSS_SELECTOR,"#su").click() sleep(3) fbStar_xlsx = str("xlsx_" + fbStar) screenshot(driver,fbStar_xlsx) sleep(7) driver.quit()
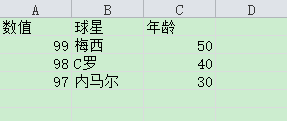
CSV读取数据.py:
import csv import os from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep from function import screenshot class test(object): def __init__(self): base = os.path.dirname(os.path.dirname(__file__)) self.base_dir = base.replace("/","\") def CSVRd(self): base_dir = self.base_dir + os.sep + "20180515作业" + os.sep + "test_csv.csv" opFile = open(base_dir,'r') rd = csv.reader(opFile) r = [] next(rd,None) for i in rd: r.append(i) return r if __name__ == '__main__': data = test().CSVRd() driver = webdriver.Chrome() driver.maximize_window() driver.get("https://www.baidu.com") driver.implicitly_wait(10) for fbStar in data: fbStar = fbStar[1] driver.find_element(By.CSS_SELECTOR,"#kw").clear() driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(fbStar) driver.find_element(By.CSS_SELECTOR,"#su").click() sleep(3) csv_fbStar = str("csv_" + fbStar) screenshot(driver,csv_fbStar) sleep(7) driver.quit()
test_xml文件:
<?xml version="1.0" encoding="utf-8"?> <info> <title>博客园登录</title> <url_dir>https://passport.cnblogs.com/user/signin</url_dir> <login username="owen_name" password="owen_pwd">登录</login> </info>
CSV读取数据.py:
import xml.dom.minidom as minidom # import xml.etree.ElementTree as ele import os from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep from function import screenshot base = os.path.dirname(os.path.dirname(__file__)) base_dir = base.replace("/","\") file_dir = base_dir + os.sep + "20180515作业" + os.sep + "test_xml.xml" #打开xml文档 dom = minidom.parse(file_dir) #得到文档元素 root = dom.documentElement #由于下面getElementsByTagName点不出来方法,手写的 tag1 = root.getElementsByTagName("login") tag2 = root.getElementsByTagName("url_dir") tag3 = root.getElementsByTagName("title") #获得标签属性值 username = tag1[0].getAttribute("username") password = tag1[0].getAttribute("password") #获得标签之间的数据 url = tag2[0].firstChild.data title = tag3[0].firstChild.data driver = webdriver.Chrome() driver.maximize_window() driver.get(url) driver.find_element(By.CSS_SELECTOR,"#input1").clear() driver.find_element(By.CSS_SELECTOR,"#input1").send_keys(username) sleep(3) driver.find_element(By.CSS_SELECTOR,"#input2").clear() driver.find_element(By.CSS_SELECTOR,"#input2").send_keys(password) sleep(3) title = str("xml_" + title) screenshot(driver,title) driver.quit()
《Python不归路_xml.etree.ElementTree模块》感谢作者:深海一尾鱼
《python读取xml文件》感谢作者:虫师