Semi-Supervised Learning
半监督学习(一)
入门级介绍
传统的机器学习任务分为无监督学习(数据无标签,如,聚类,异常检测等)和监督学习(数据有标签,如,分类,回归等)。半监督学习针对的是只有部分数据有标签的学习任务,而其中有标签数据往往远远小于无标签数据。它是机器学习领域研究的热点,因为现实场景中标签获取往往是十分昂贵的,很多研究者发现结合少量有标签数据和大量无标签数据可以有效提升学习任务的准确率。小编最近也在学习和研究半监督学习,特开此专栏分享自己的学习心得,知识点整理,paper sharing。
统计机器学习
相信很多同学对统计机器学习已经有或深或浅的了解了,作为一个入门教程,为了后面学习的顺畅,还是要对这些基础知识进行回忆,整理。
1、数据集
一个样本x代表的是一个对象,我们通常用一个特征向量![]() ,d代表样本x的维度(特征个数),机器学习的任务往往就是学习输入的d维训练样本集中潜在的模式,而根据训练样本是否有标签,学习任务又分为有监督/无监督学习。
,d代表样本x的维度(特征个数),机器学习的任务往往就是学习输入的d维训练样本集中潜在的模式,而根据训练样本是否有标签,学习任务又分为有监督/无监督学习。
2、无监督学习
无监督学习的特点是训练样本无标签,它通常可以分为以下几个任务:
- 聚类,即将样本分到不同的组,使一个组中的样本尽量相似,不同组间的样本尽量不相似(之后会出专门写聚类的专栏,敬请期待);
- 异常检测,即检测出少量偏离主体的样本(离群点);
- 维度归约:在高维样本中很多维度对学习的作用不大而且会减弱关键维度的作用,而且,在高维空间中,相似和不相似的样本之间的距离不好区分,所以降维十分关键;
3、监督学习
监督学习针对的是带标签的训练集,根据标签的离散/连续,监督学习又分为分类/回归。我们定义样本集合为X,与X中样本一一对应的标签组成的集合记为Y,令![]() 表示样本和标签服从的联合分布(未知),监督学习的任务就是训练一个方程
表示样本和标签服从的联合分布(未知),监督学习的任务就是训练一个方程![]() ,使得f(x)可以预测出x的真实标签。
,使得f(x)可以预测出x的真实标签。
如何定义f的好坏呢?损失函数是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
4、误差
在学习的过程中,我们通常通过训练样本的误差来衡量模型的性能:
-
训练误差:
给定一个训练样本集
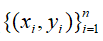 ,我们定义训练样本的误差为:
,我们定义训练样本的误差为: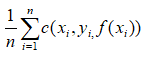 ,c()表示损失函数你可以根据不同的任务定义不同的损失函数,比如说,对于分类问题,
,c()表示损失函数你可以根据不同的任务定义不同的损失函数,比如说,对于分类问题,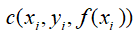 通常为0-1损失函数(
通常为0-1损失函数(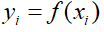 时预测正确损失为0,否则为1)。
时预测正确损失为0,否则为1)。当然,只专注于减小训练误差会造成模型过拟合,但在未来的测试数据上可能表现不好。机器学习中一有个方向叫做计算学习理论研究就是研究过拟合问题的,它在训练样本和真实误差之间建立了严格的联系,如Vapnik-Chervonenkis维数或Rademacher复杂性,根据这种理论,一种合理的策略是最小化训练误差的同时对f进行正则化,使模型不要太复杂。
-
测试误差:
为了估计模型的未来表现,我们可以划分出部分有标签数据作测试数据,这些数据不作为训练数据使用,因此提供了模型的表现的无偏估计。测试误差就是模型在测试集上的表现。
半监督学习概念
上文简单介绍了监督学习和无监督学习,那么半监督学习介于两者之间,事实上,半监督学习的策略往往都是利用额外信息,在无监督学习或者监督学习的基础上扩展的一种学习模式,这么说可能有点抽象,我们从常见的几种常见的半监督学习任务开始介绍:
1、半监督分类:
在分类任务的训练集中同时包含有标签数据和无标签数据,通常无标签数据远远多于有标签数据,半监督分类的任务就是训练一个分类器f,这个分类器的表现比只用有标签数据训练得到的分类器好;
2、半监督聚类(有约束聚类):
是无监督聚类的一种扩展,与传统的无标签训练集不同的是,约束聚类的数据集还包含一些关于聚类的“监督信息”。最常见的约束如must-link约束和cannot-link约束,分别表示两个样本点一定在一个类中或一定在不同的类中,约束聚类的目标就是提升原本无监督聚类的表现;
半监督学习的任务还有很多,比如,半监督回归,维度规约等,在之后的专栏中会又详细的介绍和相关论文导读。
半监督学习的例子
下面我们用一个简单例子带你走进半监督学习:
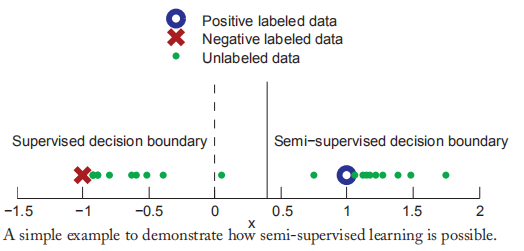
在上图中,训练样本是一维的,有两种分类(positive & negative),可以考虑以下两种情景:
-
在监督学习中,只给出两个有标签样本(-1,-)和(1,+),从图中可以看出最佳决策边界是x=0,那么所有的样本x<0,被分类为负,大于0分类为正;
-
假如我们给出大量的无标签样本(绿色点),这时问题转化为半监督学习,我们可以观察到绿色样本可以分成两组,假设每个类的实例都围绕在类中心,我们可以从无标签样本中获得更多信息。比如上图,红色点和蓝色点并不是每个类的中心点,所以我们半监督估计的决策边界是x=0.4。如果我们的假设成立,那么半监督的决策边界比监督学习和无监督学习给出的决策边界更加可靠。
-
总的来说,无标签数据的分布帮助我们定义了同类样本的边界,少量有标签样本又为类提供了标签信息。,在接下来的文章中,我们会介绍一些常用的半监督学习假设。
总结:
今天的内容只是简单地引入半监督学习的概念,也是为我们的专栏开了个头,接下来的文章会是满满的干货,敬请期待!希望大家多多支持我的公众号,扫码关注,我们一起学习,一起进步~
