转自http://www.cnblogs.com/ngnetboy/archive/2013/03/13/2949188.html
我们来看看这个矩阵,五行五列,可以包含二十五个元素,但是此矩阵只有七个元素。但是我们在存放数据的时候分配了二十五块int单元。这样是不是有点太 浪费了。如果我们只存储这七个元素我想会节省一部分内存空间。但是如果我们只存储矩阵中的元素还是不行的,因为只有元素我们就无法还原矩阵,我们还需要此 元素的行列值。这样就好办了。我们声明一个结构体来表示一个元素。就像这样:
1 typedef struct juzhen 2 { 3 int row; //行 4 int col; //列 5 int value; //元素值 6 };
然后可以开始矩阵转置:
我们需要定义一个数组来表示稀疏矩阵,并赋值;
1 #define MAX_TERM 15 2 3 struct juzhen a[MAX_TERM]; //存放矩阵中元素数值不为零的元素 4 5 int chushi(struct juzhen a[MAX_TERM]) //初始化稀疏矩阵 6 { 7 int count_value = 0; //统计矩阵中元素数值不为零的元素的总和 8 int i,j; 9 int count_a = 1; 10 for(i = 0;i < N;i++) 11 { 12 for(j = 0;j < N;j++) 13 { 14 if(text[i][j] != 0) 15 { 16 a[count_a].row = i; 17 a[count_a].col = j; 18 a[count_a].value = text[i][j]; 19 count_a++; 20 } 21 } 22 } 23 a[0].col = 5; //矩阵的总列数 24 a[0].row = 5; //矩阵的总行数 25 a[0].value = --count_a; //矩阵中的元素个数 26 27 return count_a; 28 }
我们在转置矩阵的时候会需要一个数组来保存转置后的矩阵,定义为:
struct juzhenb[MAX_TERM];
主要思想,两层循环,第一层循环控制矩阵的行,第二层循环控制数组a的行。由于转置矩阵即把矩阵中元素的列行对换一下,并且按照行排序;所以我们在第二层循环中做一个判断,if(a[j].col == i) 【i控制第一层循环,j控制第二层循环】 如果为真值则执行:
1 b[count_b].row = a[j].col;
2 b[count_b].col = a[j].row;
3 b[count_b].value = a[j].value;
整个函数如下:
1 void zhuanzhi_1(struct juzhen a[MAX_TERM],struct juzhen b[MAX_TERM]) //转置矩阵方法一 2 { 3 int i,j; 4 int count_b = 1; //b的当前元素下标 5 b[0].row = a[0].col; 6 b[0].col = a[0].row; 7 b[0].value = a[0].value; 8 for(i = 0;i < a[0].col;i++) 9 { 10 for(j = 1;j <= a[0].value;j++) 11 { 12 if(a[j].col == i) //有种排序效果 13 { 14 b[count_b].row = a[j].col; 15 b[count_b].col = a[j].row; 16 b[count_b].value = a[j].value; 17 count_b++; 18 } 19 } 20 } 21 }
用此方法可以有效的转置矩阵,我们来看一下此函数的时间复杂度:O(cols * elements)——矩阵的列*矩阵的元素总和;
如果元素很多就会浪费很多的时间。有没有办法让两层循环变成一层循环呢?付出空间上的代价,换取时间效率;
我们只用一层循环来遍历数组a中所有元素,并把该元素放到指定的位置。这样我们就需要一个数组star来存放第i个元素所在位置。在定义这个数组之前,我们还需要一个数组term来实现统计矩阵第i行元素的数量。这样我们才能更方便的知道第i个元素应该存放的位置。
1 int term[N],star[N]; //保存转置矩阵第i行元素的数量 保存第i行开始位置 2 int n = a[0].value; 3 int i,j,k; 4 int b_star; 5 6 for(i = 0;i < N;i++) 7 term[i] = 0; 8 9 for(j = 0;j <= n;j++) 10 term[a[j].col]++; 11 12 star[0] = 1; 13 for(k = 1;k < N;k++) 14 star[k] = star[k - 1] + term[k - 1];
第一个循环初始化term,每个元素都为零。第二个循环是为了统计第i行元素的数量。第三个循环是设置第i个元素所在的位置。因为数组a的第一个元素是存放行列和元素的总数,因此第三个循环要从k = 1开始。此时两个数组的元素为:
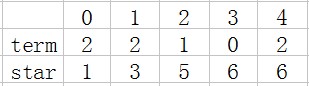
下一步就是遍历a中的所有元素,然后根据a[i].col的值来把a[i].value放到指定的位置。
1 b[0].col = a[0].col; 2 b[0].row = a[0].row; 3 b[0].value = a[0].value; 4 for(i = 1;i <= n;i++) 5 { 6 b_star = star[a[i].col]++; 7 b[b_star].col = a[i].row; 8 b[b_star].row = a[i].col; 9 b[b_star].value = a[i].value; 10 }
需要注意的是b的第一个元素与a中的第一个元素是同样的。b_star = star[a[i].col]++;因为当term[1] = 2;而star[1] = 3;就是a[i].col = 1时有两个元素,第一个元素的位置是star[a[i].col];而第二个元素的位置就是star[a[i].col] + 1所以在此用star[a[i].col]++。为下一个元素设置相应的位置;
完整函数:
1 void zhuanhuan_2(struct juzhen a[MAX_TERM],struct juzhen b[MAX_TERM]) 2 { 3 int term[N],star[N]; //保存转置矩阵第i行元素的数量 保存第i行开始位置 4 int n = a[0].value; 5 int i,j,k; 6 int b_star; 7 8 for(i = 0;i < N;i++) 9 term[i] = 0; 10 11 for(j = 1;j <= n;j++) 12 term[a[j].col]++; 13 14 star[0] = 1; 15 for(k = 1;k < N;k++) 16 star[k] = star[k - 1] + term[k - 1]; 17 18 b[0].col = a[0].col; 19 b[0].row = a[0].row; 20 b[0].value = a[0].value; 21 for(i = 1;i <= n;i++) 22 { 23 b_star = star[a[i].col]++; 24 b[b_star].col = a[i].row; 25 b[b_star].row = a[i].col; 26 b[b_star].value = a[i].value; 27 } 28 29 }
此函数每个循环体的执行次数分别为cols cols elements elements 时间复杂度为O(cols + elements)和O(cols * elements)相差好多,尤其是clos 和 elements很大的时候;
完整的测试程序:
1 完整代码 2 #include<stdio.h> 3 #define N 5 4 #define MAX_TERM 15 5 6 typedef struct juzhen 7 { 8 int row; //行 9 int col; //列 10 int value; //元素值 11 }; 12 13 int text[][5] = {{0,5,6,0,4},{0,0,0,0,0},{1,0,0,0,0},{1,0,0,0,0},{0,2,0,0,1}}; 14 struct juzhen a[MAX_TERM]; //存放矩阵中元素数值不为零的元素 15 struct juzhen b[MAX_TERM]; //转置后的矩阵 16 17 int chushi(struct juzhen a[MAX_TERM]) //初始化稀疏矩阵 18 { 19 int count_value = 0; //统计矩阵中元素数值不为零的元素的总和 20 int i,j; 21 int count_a = 1; 22 for(i = 0;i < N;i++) 23 { 24 for(j = 0;j < N;j++) 25 { 26 if(text[i][j] != 0) 27 { 28 a[count_a].row = i; 29 a[count_a].col = j; 30 a[count_a].value = text[i][j]; 31 count_a++; 32 } 33 } 34 } 35 a[0].col = 5; //矩阵的总列数 36 a[0].row = 5; //矩阵的总行数 37 a[0].value = --count_a; //矩阵中的元素个数 38 39 return count_a; 40 } 41 42 void showjuzhen(struct juzhen a[MAX_TERM],int count_a) //显示稀疏矩阵 43 { 44 int i,j; 45 int text = 1; 46 for(i = 0;i < N;i++) 47 { 48 for(j = 0;j < N;j++) 49 { 50 if(a[text].row == i && a[text].col == j) 51 { 52 printf(" %d ",a[text].value); 53 text++; 54 } 55 else 56 printf(" 0 "); 57 } 58 printf(" "); 59 } 60 61 } 62 63 void showjuzhen_2(struct juzhen a[MAX_TERM],int count_a) //显示稀疏矩阵方法二 64 { 65 int i; 66 printf(" i row col val "); 67 for(i = 0;i < count_a + 1;i++) 68 { 69 printf(" %d| %d %d %d ",i,a[i].row,a[i].col,a[i].value); 70 } 71 } 72 73 74 void zhuanzhi_1(struct juzhen a[MAX_TERM],struct juzhen b[MAX_TERM]) //转置矩阵方法一 75 { 76 int i,j; 77 int count_b = 1; //b的当前元素下标 78 b[0].row = a[0].col; 79 b[0].col = a[0].row; 80 b[0].value = a[0].value; 81 for(i = 0;i < a[0].col;i++) 82 { 83 for(j = 1;j <= a[0].value;j++) 84 { 85 if(a[j].col == i) 86 { 87 b[count_b].row = a[j].col; 88 b[count_b].col = a[j].row; 89 b[count_b].value = a[j].value; 90 count_b++; 91 } 92 } 93 } 94 } 95 96 97 void zhuanhuan_2(struct juzhen a[MAX_TERM],struct juzhen b[MAX_TERM]) 98 { 99 int term[N],star[N]; 100 int n = a[0].value; 101 int i,j,k; 102 int b_star; 103 104 for(i = 0;i < N;i++) 105 term[i] = 0; 106 107 for(j = 0;j <= a[0].value;j++) 108 term[a[j].col]++; 109 110 star[0] = 1; 111 for(k = 1;k < N;k++) 112 star[k] = star[k - 1] + term[k - 1]; 113 114 b[0].col = a[0].col; 115 b[0].row = a[0].row; 116 b[0].value = a[0].value; 117 for(i = 1;i <= n;i++) 118 { 119 b_star = star[a[i].col]++; 120 b[b_star].col = a[i].row; 121 b[b_star].row = a[i].col; 122 b[b_star].value = a[i].value; 123 } 124 125 126 for(i = 0;i < a[0].value + 1;i++) 127 printf(" %d| %d %d %d ",i,b[i].row,b[i].col,b[i].value); 128 129 } 130 131 int main(void) 132 { 133 int count_a; 134 count_a = chushi(a); 135 showjuzhen(a,count_a); 136 showjuzhen_2(a,count_a); 137 printf(" "); 138 zhuanhuan_2(a,b); 139 //zhuanzhi_1(a,b); 140 //showjuzhen(b,count_a); 141 //showjuzhen_2(b,count_a); 142 //return 0; 143 }