<更新提示>
本文的图片材料多数来自$mathrm$中详尽的$SAM$介绍,文字总结为原创内容。
<第一次更新>
<正文>
确定性有限状态自动机 DFA
首先我们要定义确定性有限状态自动机$mathrm(,一个有限状态自动机可以用一个五元组)(mathrm,Sigma,mathrm,mathrm,delta)$表示,他们的含义如下:
$1.$ (mathrm{S}) 代表自动机的状态集 $2.$ (Sigma) 代表字符集,也称字母表 $3.$ (mathrm{st}) 代表自动机的起始状态 $4.$ (mathrm{end}) 代表自动机的终止状态,也称接受状态 $5.$ (delta) 代表自动机的转移函数
例如,$mathrm(树就可以当一个自动机,)mathrm(树的点集就是自动机的状态集,小写字母集就是字符集,)mathrm(的根就是自动机的起始状态,)mathrm$的每一个叶节点就是自动机的终止状态,每一个点的出边集合就代表自动机的转移函数。
理解的有限状态自动机的定义了以后,我们就可以说$mathrm$自动机,后缀自动机都是确定性有限状态自动机。
如果一个字符串$s$由某一个自动机$T$的起始状态$mathrm$开始,根据字符串走转移边可以到达$T$的一个终止状态$mathrm$,那么我们就称自动机$T$可以识别串$s$,记为$T(s)=mathrm$。
后缀自动机的定义
定义
后缀自动机$mathrm$是一个最简有限状态自动机,识别且仅识别某个字符串$s$的所有后缀。
其中,最简的含义为状态数最少,也就是节点数最少。
例如,字符串$s=aabbabd$的后缀自动机如图所示:
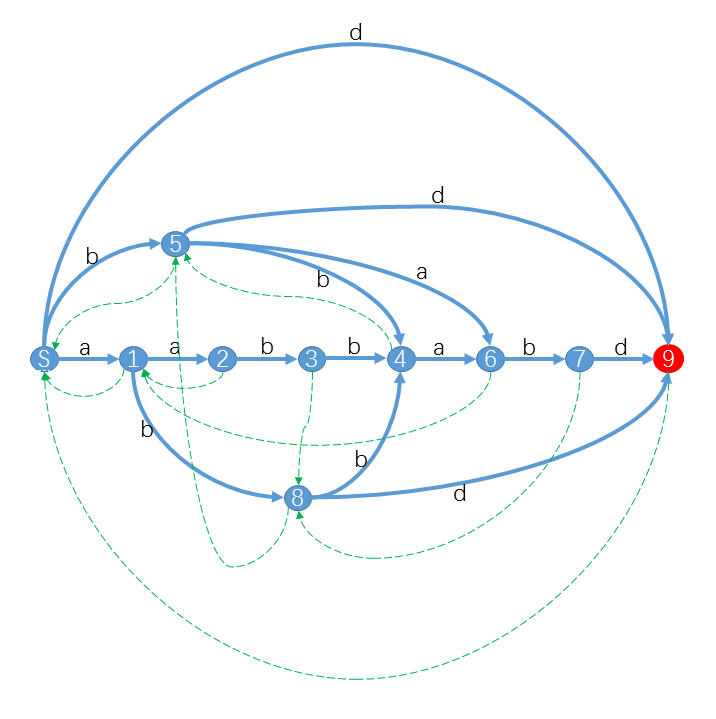
它的起始状态$mathrm=S$,终止状态$mathrm=9$,从$S$到$9$所有蓝色转移边构成的路径就代表字符串$s$的每一个后缀${aabbabd,abbabd,bbabd,babd,abd,bd,d}$。
注意,图中的绿色虚线不是自动机的转移边,是后缀自动机特有的后缀链接(mathrm{Suffix-link})。
接下来,我们将根据有限状态自动机的五个元素来介绍后缀自动机。
状态集
首先,我们称字符串$s$的一个子串在原串的所有的出现位置的右端点集合为$mathrm$集合。例如$s=aabbabd$,那么$mathrm(b)={3,4,6},mathrm(ab)={3,6}$。
对于$mathrm(**集合相等**的一些子串,我们称其为一个)mathrm(等价类,例如)mathrm(aabb)={4},mathrm(abb)={4}(,它们属于同一个)mathrm$等价类。
那么我们就可以定义后缀自动机的状态集$mathrm$为字符串$s$当中所有的$mathrm$等价类。 换句话说,我们求出$s$每一个子串的$mathrm$集合,把相同的归为一类,那么剩下的这些集合每一个分别就代表了后缀自动机上的一个状态。
所以一个$mathrm(等价类就代表了若干个字符串**,我们可以用)mathrm(p)$代表状态$p$的所有**字符串,$mathrm(p)(代表**最长**的那一个字符串,)mathrm(p)(代表**最短**的那一个字符串。例如)mathrm(4)={bb,abb,aabb} , mathrm(p)=aabb , mathrm(p)=bb$。
字符集
在后缀自动机当中字符集的定义和有限状态自动机中字符集的定义是一样的,通常有小写英文字母集,大写英文字母集,阿拉伯数字集,正整数集等等,依据具体情况确定。
起始状态和终止状态
我们定义后缀自动机有唯一的起始状态$S$和终止状态$P$,所有节点均由$S$出发可达,所有节点均可以到达$P$。
转移函数
对于一个状态$p$,我们记$mathrm{substr(p)}(中所有字符串下一个位置**可能遇到**的字符集合为)mathrm(p)(,例如)mathrm(S)={a,b,d} , mathrm(8)={b,d}$。
我们不难发现后缀自动机具有一个性质,就是对于一个状态$p$的可能后接字符$c$,所有$mathrm(p)$内的字符串加上$c$后的字符串都属于同一个状态。就比如状态$4$有$mathrm(4)={bb,abb,aabb} , mathrm(4)={a}$,他们接上$a$后得到${bba,abba,aabba}(,这些字符串都属于)mathrm(6)$。
这样我们就可以定义后缀自动机的转移函数$mathrm$了:对于状态$p$和字符$cinmathrm(p)(,)mathrm(p,c)=x , which state mathrm(p)+c belongs to.$
当然,把$mathrm(p)+c$换成$mathrm(p)+c$或者其他字符串都是可以的,因为我们知道得到的结果是一样的。
后缀自动机的性质
接下来,我们就要由后缀自动机的定义出发,发掘后缀自动机的性质,进而讲解后缀自动机的构造算法。
状态的性质
性质1 :$s_1$是$s_2$的后缀,当且仅当$mathrm(s_2)subseteq mathrm(s_1)(,反之则有)mathrm(s_1)capmathrm(s_2)=emptyset$。
证明:
首先第一条证明是显然的,随着$s_2$的出现,它的后缀$s_1$也必然跟随着出现,出现次数不会小于$s_2$的出现次数。然而,由于$s_1$比$s_2$更短,所以可能会存在$s_1$出现了$s_2$没有出现的情况,故$mathrm(s_2)subseteq mathrm(s_1)$,反之也成立。
第二条也很好理解,$s_1$不是$s_2$的后缀,他们的出现位置必然没有交集。如果存在交集,可以直接说明$s_1$是$s_2$的后缀,并且由上可知,两个字符串的$mathrm$集合是包含关系。
同时,我们也可以知道对于状态$p$,$mathrm(p)(中的字符串都是)mathrm(p)$的后缀。
性质2:对于一个状态$p$,和$mathrm(p)$的一个后缀$s$,如果满足$|mathrm(p)|leq|s|leq|mathrm(p)|$,则有$sin mathrm(p)$。
证明:
因为$|mathrm(p)|leq|s|leq|mathrm(p)|(,所以有)mathrm(mathrm(p))supseteqmathrm(s)supseteqmathrm(mathrm(p))(,又因为)mathrm(mathrm(p))=mathrm(mathrm(p))$,所以$sin mathrm(p)$。
性质3:$mathrm(p)(包含的是)mathrm(p)$的一系列连续后缀。
证明:
由性质$2$不难得出,并且,这一系列后缀会在前后界的某一个位置断开,那就是比$mathrm{long(p)}(还长的字符串不属于这个状态,比)mathrm(p)(还短的后缀不属于这个状态,原因是比)mathrm{long(p)}(还长的字符串出现次数可能比)mathrm(p)(少了,它们不属于同一个)mathrm(等价类,比)mathrm{short(p)}(还短的后缀出现位置可能比)mathrm(p)(更多了,它们也不属于同一个)mathrm$等价类。
后缀链接和Parent树
我们刚才在前面提到,后缀自动机还有一个独有的结构就是后缀链接$mathrm$。根据上面的性质$3$,我们知道$mathrm(p)$包含的后缀会在某个位置断开,那么我们就可以定义后缀链接了:若状态$q$满足$mathrm(q)+1=mathrm(p)(,且)mathrm(q)(都是)mathrm(p)(的后缀,则有)mathrm(p)=q$,称$p$有一条到$q$的后缀链接。
也就是说,我们刚才提到的某个更短的后缀,因为出现位置更多而不在同一个状态里的,就由后缀链接这一结构连接起来了。并且,由状态$p$出发,一直走后缀链接,把路径上所有状态的$mathrm(集合并起来,得到的字符串集合就包含了)mathrm(p)$的每一个后缀。
根据$mathrm(集合的包含关系,后缀链接和后缀自动机的状态形成了一个内向树结构,我们称其为)mathrm$树。
由于$mathrm$树的叶子节点最多有$n$个,每个内部节点至少有两个儿子,所以后缀自动机最多有$2n-1$个状态,我们就证明了后缀自动机的状态数是线性的。这也告诉我们,写后缀自动机的时候数组要开到$2n$大小。
线性转移数
根据上面的一些结论,我们可以证明后缀自动机的转移数也是线性的。
首先,我们可以任意的求出$mathrm$的一棵生成树,它有$2n-2$条边。然后我们考虑一条非树边$(a,b)(,它对应了一个非连续转移。那么就必然有一条路径)(S ightarrow a)+(a,b)+(b ightarrow P)$对应了原串$s$的至少一个后缀。于是我们就可以说一个后缀只对应一条路径,而一条路径对应至少一个后缀,那么非树边的转移至多就只有$n$条,所以转移数也是线性的。
SAM的构造算法
根据上面的性质,我们就可以学习后缀自动机的算法了。根据证明,我们知道后缀自动机是的状态数和转移数都是线性。事实上,后缀自动机有一个$O(|s|)$的在线构造算法,可以动态加字符,就是增量法。
对于线性构造,我们不能存太多的信息,一般来说,我们储存如下几项就够了:
| (mathrm{maxlen}_p) | (mathrm{link}_p) | (mathrm{trans}_p(c)) |
|---|---|---|
| 状态$p$的最长字符串长度 | 状态$p$的后缀链接指针 | 状态$p$关于字符$c$的转移函数 |
算法流程
首先,我们假设一个得到了一个字符串$s'(的后缀自动机,)|s'|=n$,现在我们要加一个字符$c$,得到$s'c$的后缀自动机。
根据后缀自动机的定义,我们要能够识别字符串$s'c$的$n+1$个后缀,应该给之前代表字符串$s'[1,n],s'[2,n],...,s'[n,n]$的状态增加对应的转移。现在,这些字符串就是$s'c[1,n]$这一前缀的所有后缀,而$s'c[1,n]$对应的状态就是之前的终止状态$last$。如何找到它的所有后缀对应的状态呢?我们刚才已经说了,一直走后缀链接的路径就是他每一个后缀对应的状态。
由于$s'c$这整个字符串也是一个后缀,并且一定不能被之前的后缀自动机识别,所以我们先建立一个状态$cur$,代表至少$s'c$这一个后缀。
然后我们遍历状态$last$到初始状态$S$的后缀链接路径,更新后缀自动机。
以下,我们将要分三种情况讨论:
(mathrm{Case}1:) 后缀链接路径上的所有状态$p$都没有$mathrm_p(c)(这个转移,现在我们根据后缀自动机转移函数的定义,把这个转移补上去,赋值)mathrm_p(c)=cur$即可。
同时,我们也得知后缀$s'c[1,n]$没有任何一个更短后缀出现位置比$s'c[1,n](更多,那么赋值)mathrm_=1$即可。
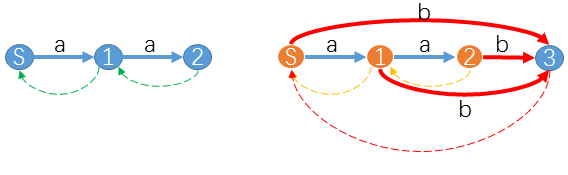
(mathrm{Example1}:)
例如我们已经得到了字符串$aa$的后缀自动机,现在要求出$aab$的后缀自动机,流程如下:
此时$last=2,cur=3$,后缀链接路径就是黄色虚线链接的$2 ightarrow 1 ightarrow S$,他们都没有$b$这个字符对应的转移,所以我们把这个转移补上,就是红色的转移。然后创建节点$3$的后缀链接即可。
(mathrm{Case2}:)
后缀链接路径上存在一个节点$p$有$mathrm_p(c)(这个转移,设)mathrm_p(c)=q$,满足$mathrm_q=mathrm_p+1$。
那么根据$mathrm$的定义,我们知道状态$q$中的字符串都是$s'c$的后缀以后,就可以链接后缀链接了,即$mathrm_=q$。此时相当于$n+1$个后缀,前一部分长度大于$mathrm_q$的由状态$cur$管辖,后一部分长度小于等于$mathrm_q$的由$q$及其后缀链接路径上的其他状态管辖。
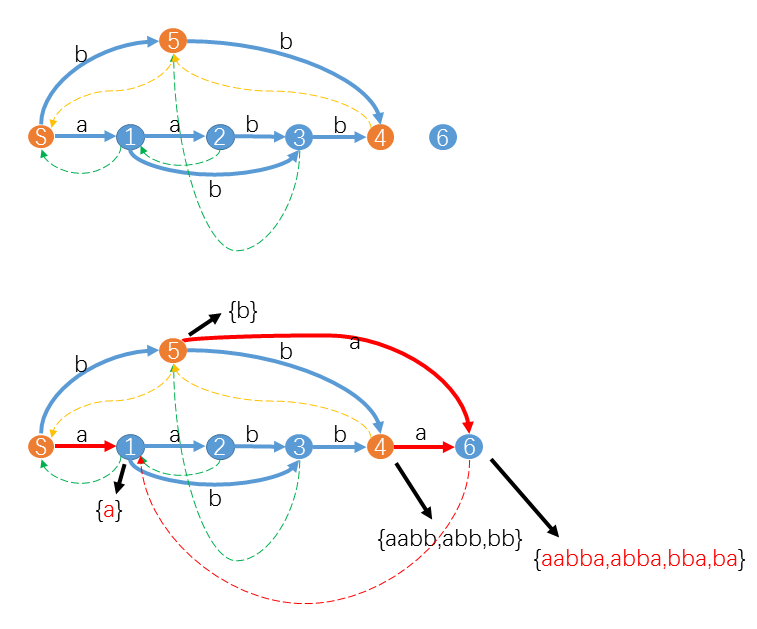
(mathrm{Example2}:)
例如我们已经得到了字符串$aabb$的后缀自动机,现在要求出$aabba$的后缀自动机,流程如下:
此时$last=4,cur=6$,后缀链接路径就是黄色虚线链接的$4 ightarrow 5 ightarrow S$,其中$4,5$都没有$a$这个字符对应的转移,所以我们把这个转移补上,就是红色的转移。然后我们发现状态$S$已经有了$a$这个转移,(q=mathrm{trans}_S(a)=1),满足$mathrm_q=mathrmp+1$,就是说明$aabba$的一个后缀$a$在$aabb$中就已经出现了,并且状态$q=1$的$mathrm(集合包含)mathrm(cur)(,所以可以顺理成章地加上后缀链接)mathrm=q=1$。
(mathrm{Case3}:)
后缀链接路径上存在一个节点$p$有$mathrm_p(c)(这个转移,设)mathrm_p(c)=q$,不满足(mathrm{maxlen}_q=mathrm{maxlen}_p+1)。
这种情况最为复杂,我们可以先看看具体的例子,了解到底是出现了什么情况。
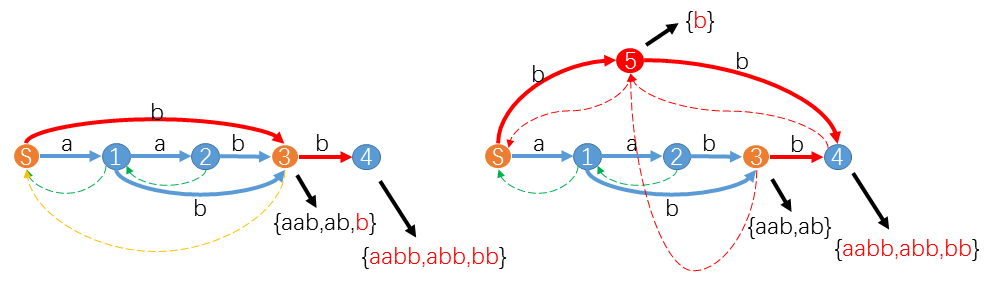
(mathrm{Example3}:)
例如我们已经得到了字符串$aab$的后缀自动机,现在要求出$aabb$的后缀自动机,具体情况如下:
此时$last=3,cur=4$,后缀链接路径就是黄色虚线链接的$3 ightarrow S$,其中$3$都没有$b$这个字符对应的转移,所以我们把这个转移补上,就是红色的转移。然后我们发现状态$S$已经有了$b$这个转移,(q=mathrm{trans}_S(b)=3),但是$mathrm(q=3)=3 ot =mathrm(p=S)+1=1$,即$mathrm{substr(3)}$除了$b$以外还存在更长的串,他们不是$aabb$的后缀,那么我们就不能直接令(mathrm{link}_{cur}=3)。
这其实表明了$b$这个子串又在新的位置出现了,它势必不能再和$aab,ab$属于同一个状态,因为他们的$mathrm$集合已经不同了,不属于同一个等价类,所以解决方案就是我们新建一个状态$cl=5$,让$cl$管辖原来$q$中长度小于等于$mathrmp+1$那一部分的子串,同时更改$S$到$q=3$的转移为$S$到$cl=5$的转移即可。当然,原来$q$的转移$cl$应该都有,也就是说要有$mathrm(b)=4$。
那么如何处理后缀链接呢?其实不难发现,原本$mathrmq=S$的字符串仍然是$mathrm(cl=5)(当中字符串的后缀,只需令)mathrm=mathrmq$即可,现在$mathrm(cl=5)(中的字符串都是)mathrm(q=3)(中字符串的后缀,只需令)mathrm=cl$即可。对于$cur$来说,就可以像第一种情况一样令$mathrm_ = cl$了。
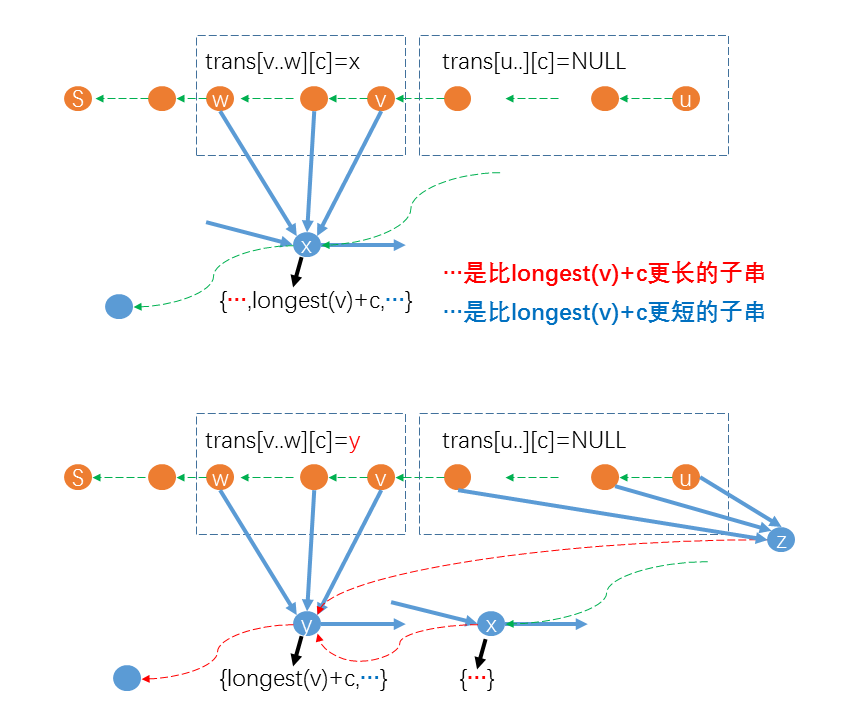
大致了解了解决方案以后,我们就可以一般性的归纳具体的解决方案了。如图:
(由于笔者没有找到很好的作图方式,用的都是$mathrm$的图,图中的$z$就是上文中的$cur$,$u$就是上文中的$last$,$x$就是上文中的$q$,$w-v$就是上文中发现$mathrm_p(c)=q$的状态$p$,$y$就是新建的状态$cl$,望读者见谅)
我们在遍历后缀链接路径时,遇到一部分连续的状态满足$mathrm_p(c)=mathrm(,只需赋值)mathrm_p(c)=cur$即可,对于存在$mathrm_p(c)=q$的点$p$,并且$mathrm_q ot =mathrm_p+1$,那么我们需要新建一个节点$cl$管辖长度小于等于$mathrm_q+1$的子串,然后将原后缀链接路径上满足$mathrm_p(c)=q$的所有状态$p$的转移改为$mathrmp(c)=cl$,并且让$cl$复刻状态$q$的所有转移,最后连接后缀链接$mathrm=mathrm_q,mathrmq=mathrm=cl$即可。
至此,构造算法结束。
时间复杂度分析
首先,对于大字符集的问题,我们可以用$mathrm$来存储转移边,这样的话时间复杂度是$O(nlog Sigma)$,空间复杂度是$O(n)$。对于小字符集的问题,我们可以用定长数组来存储转移边,这样时空复杂度均为$O(n|Sigma|)$。如果用链表来优化遍历的话,那么时间复杂度就是$O(n)$。
代码实现
如下代码用结构体封装了后缀自动机的实现,字符集大小默认$26$,$mathrm$即为拓展字符函数。
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],tot,last;
// trans为转移函数,link为后缀链接,maxlen为状态内的最长后缀长度
// tot为总结点数,last为终止状态编号
SuffixAutomaton () { last = tot = 1; } // 初始化:1号节点为S
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
// 创建节点cur
for ( p = last; p && !trans[p][c]; p = link[p] ) // 遍历后缀链接路径
trans[p][c] = cur; // 没有字符c转移边的链接转移边
if ( p == 0 ) link[cur] = 1; // 情况1
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q; // 情况2
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1; // 情况3
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
last = cur;
}
};
后缀自动机的基础操作
利用基数排序求拓扑序
根据后缀自动机的定义和构造过程,我们不难发现后缀自动机的状态和转移构成了一张有向无环图,我们称之为$mathrm(。在后缀自动机上,)mathrm(的拓扑序可以方便的实现动态规划。现在,我们将用一种很简单的基数排序方式求出)mathrm$的拓扑序。
不难发现,一个状态$p$在$mathrm(中的层数就是)mathrm_p$,所以我们可以用一个桶统计出层数为$i$的节点有几个,然后求一遍前缀和,就可以得到层数小于等于$i$的节点有几个,然后就可以直接取出编号得到拓扑序列了。
inline void Topsort(int n)
{
for (int i = 1; i <= tot; i++) ++buc[ maxlen[i] ];
for (int i = 1; i <= n; i++) buc[i] += buc[i-1];
for (int i = 1; i <= tot; i++) ord[ buc[maxlen[i]]-- ] = i;
// ord[i] 代表拓扑序列中第i个点的编号
}
求endpos集合的大小
设节点$p$的$mathrm$等价类大小为$size_p$,则有:
由于一个节点$mathrm(链接的点的拓扑序位置一定小于这个点的拓扑序位置,所以可以用拓扑序逆序更新,不需要建出)mathrm$树。
for (int i = tot; i >= 1; i--)
size[ link[ord[i]] ] += size[ ord[i] ];
例题:(Luogu P3804)
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 2e6+20;
struct SuffixAutomaton
{
int link[N],maxlen[N],trans[N][26],cnt[N],ord[N],size[N],tot,last;
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[cur] = link[q] = cl;
}
}
size[ last = cur ] = 1;
}
inline void Topsort(int n)
{
for (int i = 1; i <= tot; i++) ++ cnt[maxlen[i]];
for (int i = 1; i <= n; i++ ) cnt[i] += cnt[i-1];
for (int i = 1; i <= tot; i++) ord[ cnt[maxlen[i]]-- ] = i;
for (int i = tot; i >= 1; i--) size[link[ord[i]]] += size[ord[i]];
}
};
SuffixAutomaton T; char s[N];
int main(void)
{
scanf( "%s" , s+1 );
int n = strlen( s+1 );
for (int i = 1; i <= n; i++) T.Extend( s[i] - 'a' );
T.Topsort( n );
long long ans = 0;
for (int i = 1; i <= T.tot; i++)
if ( T.size[i] > 1 )
ans = max( ans , 1LL * T.size[i] * T.maxlen[i] );
printf( "%lld
" , ans );
return 0;
}
求本质不同的子串数
节点$p$的$|mathrm(p)|$就是其代表的字符串数量,容易得知:
于是直接对每一个状态的字符串数量求和即可。
for (int i = 1; i <= tot; i++)
ans += maxlen[cur] - maxlen[link[cur]];
例题:([SDOI2016]) 生成魔咒
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5+20;
struct SuffixAutomaton
{
map <int,int> trans[N]; long long ans;
int link[N],maxlen[N],tot,last;
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p].count(c); p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
trans[cl] = trans[q];
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
last = cur , ans += maxlen[cur] - maxlen[link[cur]];
}
};
SuffixAutomaton T; int a[N],n;
int main(void)
{
scanf( "%d" , &n );
for (int i = 1; i <= n; i++)
{
scanf( "%d" , &a[i] );
T.Extend( a[i] );
printf( "%lld
" , T.ans );
}
return 0;
}
匹配子串
可以直接把一个字符串放在后缀自动机上遍历,如果恰好匹配到了终止节点就说明该串是原串的一个后缀。如果匹配到了某个内部节点就说明是原串的一个子串。这样的话,就可以实现$mathrm$自动机的基本内容了。
inline bool Check(string t)
{
int now = 1 , len = t.size();
for (int i = 0; i < len; i++)
if ( trans[now][t[i]-'a'] )
now = trans[now][t[i]-'a'];
else return false;
return true;
}
例题:([JSOI2012]) 玄武密码
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 2e7+20; int id[200];
struct SuffixAutomaton
{
int trans[N][4],link[N],maxlen[N],tot,last;
SuffixAutomaton () { last = tot = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
last = cur;
}
inline int Query(char *s)
{
int n = strlen( s+1 ) , p = 1 , res = 0;
for (int i = 1; i <= n; i++)
if ( trans[p][id[s[i]]] )
p = trans[p][id[s[i]]] , res++;
else return res;
return res;
}
};
SuffixAutomaton T;
int n,m; char s[N];
int main(void)
{
freopen( "symbol.in" , "r" , stdin );
freopen( "symbol.out" , "w" , stdout );
id['E'] = 0 , id['S'] = 1 , id['W'] = 2 , id['N'] = 3;
scanf( "%d%d" , &n , &m );
scanf( "%s" , s+1 );
for (int i = 1; i <= n; i++)
T.Extend( id[s[i]] );
for (int i = 1; i <= m; i++)
{
scanf( "%s" , s+1 );
printf( "%d
" , T.Query(s) );
}
return 0;
}
- 6
求最长公共子串
对于两个串的最长公共子串,有$O(n^2)$的$dp$方法,用后缀自动机可以实现$O(n)$。
我们可以对于一个串先建立$SAM$,然后把第二个串放到$SAM$上去匹配,如果可以走转移边,那就走转移边,匹配长度加一,相当于匹配右端点,反之则跳$mathrm$,回到当前匹配串的一个后缀,相当于移动左端点。每次更新完毕后对答案取一个最大值即可。
例题:(SPOJ 1811)
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 2000020;
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],tot,last;
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
last = cur;
}
inline int LCS(char *s)
{
int n = strlen( s+1 ) , p = 1 , ans = 0 , Ans = 0;
for (int i = 1; i <= n; i++)
{
if ( trans[p][s[i]-'a'] )
p = trans[p][s[i]-'a'] , ans++;
else {
while ( p && !trans[p][s[i]-'a'] ) p = link[p];
if ( p == 0 ) ans = 0 , p = 1;
else ans = maxlen[p] + 1 , p = trans[p][s[i]-'a'];
}
Ans = max( Ans , ans );
}
return Ans;
}
};
SuffixAutomaton T;
int n; char a[N],b[N];
int main(void)
{
freopen( "lcs.in" , "r" , stdin );
freopen( "lcs.out" , "w" , stdout );
scanf( "%s%s" , a+1 , b+1 );
n = strlen( a+1 );
for (int i = 1; i <= n; i++)
T.Extend( a[i] - 'a' );
int ans = T.LCS( b );
printf( "%d
" , ans );
return 0;
}
对于$n$个串的最长公共子串,$SAM$仍然可以在$O(n)(的时间内求解。对于任意一个串,我们先建立后缀自动机,然后把其余的串放在上面一次匹配,对每一个节点记录一下能够匹配的最大长度。然后利用拓扑顺序更新一下)mathrm(树上祖先的最大匹配长度(一个点能够匹配成功,它的后缀也一定能够被匹配),每个节点得到该串的最大匹配长度,再对于不同的串之间取)min$即可。
例题:(SPOJ 1812)
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 200020 , INF = 0x3f3f3f3f;
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],ans[N],mat[N],cnt[N],ord[N],tot,last;
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[cur] = link[q] = cl;
}
}
last = cur;
}
inline void Topsort(int n)
{
memset( ans , 0x3f , sizeof ans );
for (int i = 1; i <= tot; i++) ++cnt[ maxlen[i] ];
for (int i = 1; i <= n; i++) cnt[i] += cnt[i-1];
for (int i = 1; i <= tot; i++) ord[ cnt[maxlen[i]]-- ] = i;
}
inline void LCS(char *s)
{
int len = strlen( s+1 ) , p = 1 , Ans = 0;
for (int i = 1; i <= len; i++)
{
if ( trans[p][s[i]-'a'] )
p = trans[p][s[i]-'a'] , ++Ans;
else {
while ( p && !trans[p][s[i]-'a'] ) p = link[p];
if ( p == 0 ) p = 1 , Ans = 0;
else Ans = maxlen[p] + 1 , p = trans[p][s[i]-'a'];
}
mat[p] = max( mat[p] , Ans );
}
for (int i = tot; i >= 1; i--)
{
int u = ord[i] , fa = link[u];
mat[fa] = max( mat[fa] , min( mat[u] , maxlen[fa] ) );
ans[u] = min( ans[u] , mat[u] ) , mat[u] = 0;
}
}
inline int Getans(void)
{
int Ans = 0;
for (int i = 1; i <= tot; i++)
if ( ans[i] != INF ) Ans = max( Ans , ans[i] );
return Ans;
}
};
SuffixAutomaton T; char s[N];
int main(void)
{
scanf( "%s" , s+1 );
int n = strlen( s+1 );
for (int i = 1; i <= n; i++)
T.Extend( s[i] - 'a' );
T.Topsort(n);
while ( ~scanf( "%s" , s+1 ) ) T.LCS(s);
printf( "%d
" , T.Getans() );
return 0;
}
求最小循环串
对于字符串$s$,我们可以复制一遍$s$然后接在原串后面,得到$ss$,然后对于$ss$建立后缀自动机。不难发现,在这个后缀自动机上走$|s|$步可以得到的所有字符串就是$s$的所有循环串,只要走字典序最小的转移边即可。
例题:(POJ 1509)
(mathrm{Code}:)
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int N = 100020;
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],tot,last;
SuffixAutomaton () { tot = last = 1; }
inline void Reset(void)
{
for (int i = 1; i <= tot; i++)
link[i] = maxlen[i] = 0 ,
memset( trans[i] , 0 , sizeof trans[i] );
tot = last = 1;
}
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c] ; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[cur] = link[q] = cl;
}
}
last = cur;
}
inline int Ergodic(int n)
{
int p = 1;
for (int i = 1; i <= n; i++)
for (int j = 0; j < 26; j++)
if ( trans[p][j] ) { p = trans[p][j]; break; }
return maxlen[p] - n + 1;
}
};
SuffixAutomaton T; char s[N];
int main(void)
{
int n; scanf( "%d" , &n );
for (int i = 1; i <= n; i++)
{
scanf( "%s" , s+1 );
int len = strlen( s+1 );
T.Reset();
for (int j = 1; j <= len; j++) T.Extend(s[j]-'a');
for (int j = 1; j < len; j++) T.Extend(s[j]-'a');
printf( "%d
" , T.Ergodic(len) );
}
return 0;
}
求本质相同或不同的第k小子串
上文我们已经提到过如何求每个点的$mathrm(集合大小,也就是对应字符串的出现次数。进一步地,我们可以在)mathrm$上$dp$,求出经过每一个点的子串数量。然后我们从初始状态开始$dfs$,按字典序访问转移边,如果访问下一个节点的子串总数都不到当前的$k$的话,就把$k$减掉子串数,然后跳过这条转移边,反之则向下访问即可。每到一个节点记得减掉当前节点的子串数。
如果本质相同也可以,那么$dp$数组的初值就是$mathrm$集合的大小,如果求本质不同,那么$dp$数组的初值是$1$。
例题:([TJOI2015]) 弦论
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6+20;
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],tot,last;
long long f[N]; int buc[N],ord[N],size[N];
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c)
{
int cur = ++tot , p;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
size[ last = cur ] = 1;
}
inline void Topsort(int n)
{
for (int i = 1; i <= tot; i++) ++buc[ maxlen[i] ];
for (int i = 1; i <= n; i++) buc[i] += buc[i-1];
for (int i = 1; i <= tot; i++) ord[ buc[maxlen[i]]-- ] = i;
for (int i = tot; i >= 1; i--) size[ link[ord[i]] ] += size[ ord[i] ];
}
inline void DynamicProgram(int t)
{
for (int i = 1; i <= tot; i++)
f[i] = ( size[i] = ( t ? size[i] : 1 ) );
f[1] = size[1] = 0;
for (int i = tot; i >= 1; i--)
for (int j = 0; j < 26; j++)
f[ord[i]] += f[ trans[ord[i]][j] ];
}
inline void Dfs(int x,long long k)
{
if ( k <= size[x] ) return void();
k -= size[x];
for (int i = 0 , y; i < 26; i++)
if ( y = trans[x][i] )
if ( k > f[y] ) k -= f[y];
else return putchar(i+'a') , Dfs(y,k);
}
};
SuffixAutomaton T;
char s[N]; long long t,k;
int main(void)
{
freopen( "string.in" , "r" , stdin );
freopen( "string.out" , "w" , stdout );
scanf( "%s" , s+1 );
scanf( "%lld%lld" , &t , &k );
int n = strlen( s+1 );
for (int i = 1; i <= n; i++)
T.Extend( s[i] - 'a' );
T.Topsort(n);
T.DynamicProgram(t);
if ( T.f[1] < k ) puts("-1");
else T.Dfs( 1 , k );
return 0;
}
后缀树和后缀数组
定义
后缀树指的是将一个字符串的所有后缀插入到一个$mathrm$树中,把没有分叉的边压缩后得到的树。后缀树的节点数和边数仍然是线性的,如下图所示:
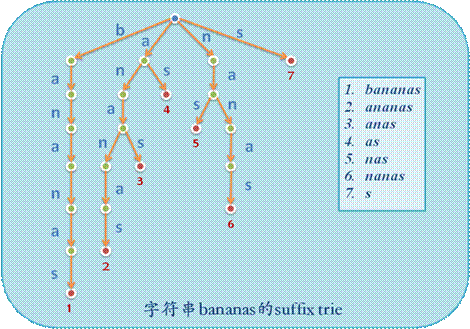
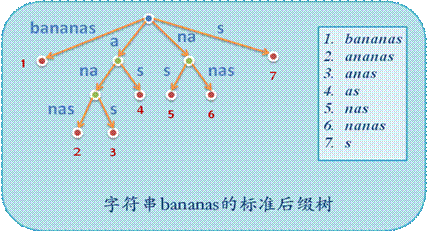
后缀数组则是两个线性数组$mathrm{sa,rank}$,分别表示将字符串$s$的$n$个后缀,按照字典序排序后排名为$i$的后缀和后缀$i$的排名。
后缀自动机转后缀树
我们当然不会从头开始介绍后缀树,但是,我们可以通过我们已经学会的后缀自动机来构造一棵后缀树。
定理: 反串后缀自动机的$mathrm$树和原串的后缀树同构。
我们当然可以直接记住这个定理,也可以通过后缀自动机和后缀树的性质来理解它。上文一直提到,后缀自动机上的一个节点代表了原字符串上的一个$mathrm$等价类,也叫$Right$等价类。而从后缀树的压缩过程来看,压缩的都是左端点相同的子串。事实上,后缀树的每一个节点都代表了一个$Left$等价类。那么这样看来,反串的$mathrm$树就是后缀树是不是极其自然呢?
至于代码实现,我们只要倒序将字符串插入后缀自动机即可。
但是还有一个问题,我们要处理后缀树边上的字符串。我们不妨画一个图来看看:
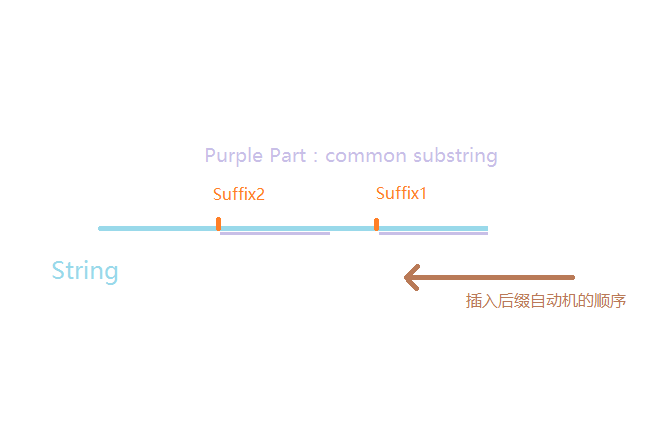
对于字符串$s$的两个后缀,我们不妨假设他们有一段公共部分,并且得知在$mathrm(当中)mathrm(对应的状态的)mathrm(树父亲是)mathrm(对应的状态()mathrm(是)mathrm(的一个前缀,它的出现位置比)mathrm(更多了)。那么,在后缀树里,我们知道浅紫色部分是要被压缩掉的边,而这两个节点所连接的边代表的字符串的首字符就是)mathrm(浅紫色部分后的第一个字符,不妨假设)mathrm$对应节点插入时的位置为$pos$,那么我们刚才所说的首字符就应该是$s[pos+mathrm_{mathrm_i}](。当然,这个字符串的长度就是)mathrmi-mathrm{mathrm_i}$。
尽管图中的情况是较为特殊的,$mathrm(这个后缀是)mathrm$这个后缀的前缀,但是比较容易理解,并且一般情况下其实也是一样的,这不过这时后缀树上链接的父亲不是真实的后缀节点,而是后缀自动机上的虚点$cl$罢了。
这样建立后缀树的时间复杂度和建立后缀自动机的时间复杂度是一样的。
后缀树转后缀数组
仔细思考一下,后缀树本质上还是一颗$mathrm(树的"压缩版本",那么如何求得)mathrm(数组呢?直接按照字典序在后缀树上)mathrm(一遍就可以了,这就相当于了后缀排序。既然)mathrm(数组已经求得了,那么)mathrm$数组也可以轻松得到,时间复杂度为$O(n|Sigma|)$。
例题:(UOJ 35)
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5+20;
struct SuffixAutomaton
{
int trans[N][26],link[N],maxlen[N],tot,last;
int id[N],flag[N],trie[N][26],sa[N],rk[N],hei[N],cnt;
// id 代表这个状态是几号后缀 , flag 代表这个状态是否对应了一个真实存在的后缀
SuffixAutomaton () { tot = last = 1; }
inline void Extend(int c,int pos)
{
int cur = ++tot , p;
id[cur] = pos , flag[cur] = true;
maxlen[cur] = maxlen[last] + 1;
for ( p = last; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , id[cl] = id[q] , link[q] = link[cur] = cl;
}
}
last = cur;
}
inline void insert(int x,int y,char c) { trie[x][c-'a'] = y; }
inline void Build(char *s,int n)
{
for (int i = n; i >= 1; i--)
Extend( s[i]-'a' , i );
for (int i = 2; i <= tot; i++)
insert( link[i] , i , s[ id[i] + maxlen[link[i]] ] );
}
inline void Dfs(int x)
{
if ( flag[x] ) sa[ rk[id[x]] = ++cnt ] = id[x];
for (int i = 0 , y; i < 26; i++)
if ( y = trie[x][i] ) Dfs(y);
}
inline void Calcheight(char *s,int n)
{
for (int i = 1 , k = 0 , j; i <= n; i++)
{
if (k) --k; j = sa[ rk[i]-1 ];
while ( s[ i+k ] == s[ j+k ] ) ++k;
hei[ rk[i] ] = k;
}
}
};
SuffixAutomaton T; char s[N];
int main(void)
{
scanf( "%s" , s+1 );
int n = strlen( s+1 );
T.Build( s , n ) , T.Dfs(1);
T.Calcheight( s , n );
for (int i = 1; i <= n; i++)
printf( "%d%c" , T.sa[i] , "
"[ i == n ] );
for (int i = 2; i <= n; i++)
printf( "%d%c" , T.hei[i] , "
"[ i == n ] );
return 0;
}
广义后缀自动机
上文中提到的后缀自动机都是针对一个字符串建立的后缀自动机,事实上,我们还可以针对多个字符串建立以构后缀自动机,识别且仅识别每一个串的后缀,这样的后缀自动机被称为广义后缀自动机。
构建方法
网络上流传着$4$种广义后缀自动机的构建方法,我们逐个分析:
$1.$ 把每个字符串用一个不在字符集里的字符链接起来(类似于后缀数组的方法),然后把整个串建立后缀自动机。
正确性基本可以保证,复杂度正确但是时间常数较大,并且要特殊处理链接字符的节点统计等问题,适用范围有限,代码实现简单。
$2.$ 每次插入完一个字符串后将$last$指针重置到初始节点,然后继续插入字符串。
正确性得不到保证,当加入的字符串可能重复的时候,会存在覆盖原来状态的问题,不建议使用。
$3.$ 将所有字符串建立一棵$mathrm(树,然后以)mathrm$上的父亲节点作为$last$节点,$mathrm$或$Dfs$建立后缀自动机。
正确性可以保证,但是当用$Dfs$建立时,时间复杂度不正确,最坏可达$O(|s|^2)(,用)mathrm$建立时间复杂度正确,但是必须离线建立,并且时间常数较大。
$4.$ 采用建立狭义后缀自动机时$mathrm$的拆点处理方法,直接建立广义后缀自动机。
正确性可以保证,时间复杂度正确,常数较小,可以在线处理。
那么,我们重点来看一下第四种方法。
我们还是把若干字符串当作一棵$mathrm(来看,那么)mathrm(的概念就扩展到)mathrm(树上的)mathrm$。那么,当我们逐个插入字符串的字符时,还需额外考虑一种情况:插入的上一个结点$last$后已经有了字符$c$这个转移,假设转移到$q$。
仍然需要分两种情况,第一种就是$mathrmq=mathrm+1$,也就是说某两个字符串存在相同的前缀,那么就表明这次插入确实是没有必要的,直接跳过即可。第二种和狭义后缀自动机的$mathrm(是同理的,就表明在)mathrm$树上这个字符串已经不属于$q$的$mathrm$集合了,因为他在其他分叉上又出现了。那么,处理方式还是一样的,只需建立一个虚点$cl$管理长度小于等于$mathrm_+1$的子串即可,剩下的归还原节点处理,代码实现是一模一样的,相信理解了$mathrm(的本质以后读者应该不难理解,**这只不过是把)mathrm(集合的概念拓展到了)mathrm$树上而已**。
例题:([ZJOI2015]) 诸神眷顾的幻想乡
(mathrm{Code}:)
#include <bits/stdc++.h>
using namespace std;
const int N = 4000020;
struct SuffixAutomaton
{
int trans[N][10],link[N],maxlen[N],tot;
SuffixAutomaton () { tot = 1; }
inline int Extend(int c,int pre)
{
if ( trans[pre][c] == 0 )
{
int cur = ++tot , p;
maxlen[cur] = maxlen[pre] + 1;
for ( p = pre; p && !trans[p][c]; p = link[p] )
trans[p][c] = cur;
if ( p == 0 ) link[cur] = 1;
else {
int q = trans[p][c];
if ( maxlen[q] == maxlen[p] + 1 ) link[cur] = q;
else {
int cl = ++tot; maxlen[cl] = maxlen[p] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( p && trans[p][c] == q )
trans[p][c] = cl , p = link[p];
link[cl] = link[q] , link[q] = link[cur] = cl;
}
}
return cur;
}
else {
int q = trans[pre][c];
if ( maxlen[q] == maxlen[pre] + 1 ) return q;
else {
int cl = ++tot; maxlen[cl] = maxlen[pre] + 1;
memcpy( trans[cl] , trans[q] , sizeof trans[q] );
while ( pre && trans[pre][c] == q )
trans[pre][c] = cl , pre = link[pre];
return link[cl] = link[q] , link[q] = cl;
}
}
}
inline long long Query(void)
{
long long res = 0;
for (int i = 1; i <= tot; i++)
res += maxlen[i] - maxlen[link[i]];
return res;
}
};
struct edge { int ver,next; } e[N];
SuffixAutomaton T;
int n,c,t,col[N],id[N],Head[N],deg[N];
inline void insert(int x,int y) { e[++t] = (edge){y,Head[x]} , Head[x] = t; }
inline void input(void)
{
scanf( "%d%d" , &n , &c );
for (int i = 1; i <= n; i++)
scanf( "%d" , &col[i] );
for (int i = 1 , u , v; i < n; i++)
scanf( "%d%d" , &u , &v ),
insert( u , v ) , insert( v , u ),
++deg[u] , ++deg[v];
}
inline void Dfs(int x,int fa)
{
id[x] = T.Extend( col[x] , id[fa] );
for (int i = Head[x]; i; i = e[i].next)
{
int y = e[i].ver;
if ( y == fa ) continue;
Dfs( y , x );
}
}
int main(void)
{
freopen( "substring.in" , "r" , stdin );
freopen( "substring.out" , "w" , stdout );
input() , id[0] = 1;
for (int i = 1; i <= n; i++)
if ( deg[i] == 1 ) Dfs(i,0);
printf( "%lld
" , T.Query() );
return 0;
}
后记
后缀自动机的入门和基本运用方法到这里为止就已经讲完了,剩下的就是后缀自动机的高级运用,例如结合线段树合并等数据结构方法维护更多的信息,结合动态规划方法进行更多的统计,以及广义后缀自动机的深入理解等,后续博客可能还会总结。
<后记>