CF算法分为两大类,一类为基于memory的(Memory-based),也叫基于用户的(User-based), 另一类为基于Model的(Model-based),也叫基于物品的(Item-based)。 User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c, 那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。 该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合, 该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。 User-based算法存在两个重大问题: 1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品, 不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居, 即偏好相似的用户。 2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加, 不适合数据量大的情况使用。 Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性, 然后把与用户喜欢的物品相类似的物品推荐给用户。还是以之前的例子为例, 可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。 因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中, 当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题
User-based就是把与你有相同爱好的用户所喜欢的物品(并且你还没有评过分)推荐给你:
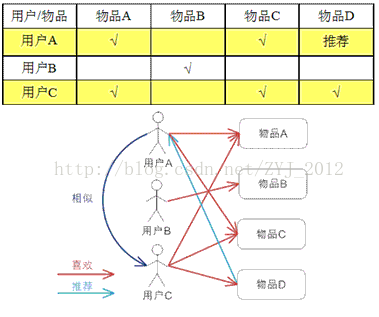
Item-based则与之相反,把和你之前喜欢的物品近似的物品推荐给你:

原文:https://blog.csdn.net/zyj_2012/article/details/53781253