★PART1:32位的x86处理器执行方式和架构
1. 寄存器的拓展(IA-32)
从80386开始,处理器内的寄存器从16位拓展到32位,命名其实就是在前面加上e(Extend)就好了,8个通用寄存器被命名为EAX,EBX,ECX,EDX,ESI,EDI,ESP和EBP,同样的,操作的时候必须要和寄存器的长匹配,比如下面的操作就是错的。

32位通用寄存器的高16位不可以单独使用,但是他们的低16位依然可以按照8086的使用方法一样使用。处理器在32位保护模式下可以使用全部的32条地址线,访问4GB内存。同时,EIP变成了32位的,当然在实模式下也可以只使用实模式下的16位。标志寄存器FLAGS也拓展到16位,其前各个16位和16位模式下各个标志一样。
在32位模式下对内存的访问理论上是不需要分段的,但是IA-32也是基于分段模型的,当然也可以只分一个段,基地址是0x00000000,段的长度是4GB,在这种情况下,可以视为不分段,也就是平坦模式(Flat Mode)。
在32位模式下,处理器要求在加载程序的时候,先定义该程序拥有的段,然后允许使用这些段,定义段的时候,除了基地址(起始地址)外,还附加了段界限,特权级别,类型等属性。当程序访问一个段时候处理器将用固件实施各种检查工作,以防对内存的违规访问,如图,32位模式下,传统的段位寄存器,如CS,SS,DS,ES,保存的不再是16位的段基地址,而是段的选择子(选择要访问的段,段的定义在GDT或者LDT上),除了段选择子,每个段寄存器还包括了一个不可见的部分,称位描述符高速缓存器,里面有段的基地址和各种访问属性,这部分内容程序不可访问,由处理器自动使用,另外32位模式还多加了两个段位寄存器FS和GS。

2. x86的32位处理器的基本工作模式
①:16位保护模式(80286)
80286是一款16位的处理器,在实模式下和8086一样,只能使用最大为64KB的段,虽然他有24根地址线,理论上可以访问224的内存(16MB),但是还是只能分成多个段来访问。但是80286访问内存的时候,不需将段地址左移,因为在段寄存器的描述符高速缓存中有24位的段物理基地址,这样一来,段可以位于16MB内存空间中的任何位置,而不再限于1MB的范围内,也不必非得对齐16字节,但是80286的通用寄存器是16位的,只能提供16位的偏移地址,所以和8086一样,即使运行在16位保护模式下,段的长度也不能超过64KB。
②:32位保护模式(80836和以后的x86 32位处理器)
80386处理器的寄存器是32位的,而且拥有32根地址线,可以访问232,即4GB的内存,80386以及后续的所有32位处理器,都有兼容模式,可以运行实模式下的8086,且刚加电的时候,这些处理器都自动处于实模式下,可以运行8086的程序,这个时候它相当于一个非常快的8086处理器,在实模式下经过一定的设定就可以进入保护模式。32位保护模式下,段的基地址是32位的,偏移地址也是32位的。32位保护模式兼容80286的16位保护模式。
3. 线性地址(Liner Address)
IA-32处理器编程,需要在程序中给出段地址和偏移地址,因为分段是IA-32的基本特征之一,传统上,段地址和偏移地址称为逻辑地址,偏移地址被叫做有效地址(Effective Address,EA),在指令中给出有效的地址叫做寻址方式(Addressing Mode),比如:
![]()
段的管理是由处理器的段部件负责产生的,段部件将段地址和偏移地址相加,得到访问内存的地址。一般来说,段部件产生的地址就是物理地址。IA-32处理器支持多任务,在多任务环境下,任务的创建需要分配内存,当任务终止后,还要回收他所占用的内存。在分段模型下,内存的分配是不定长的,所以IA-32处理器支分页功能,分页功能将物理内存空间划分成逻辑空间上的页,页的大小是固定的,一般为4KB,通过使用页,可以简化内存管理。(只有开启了页功能才能使用页),当页功能开启后,段部件产生的地址就不再是物理地址了,而是线性地址,线性地址还要经页部件转换后,才是物理地址。
线性地址的概念用来描述任务的地址空间,IA-32处理器上的每个任务都拥有4GB的虚拟内存空间,这是一段长4GB的平坦空间,就像一段平直的线段,因此叫线性地址空间,相应的,由段部件产生的地址,就对应着线性地址空间上的每一个点,这就是线性地址(也就是线性地址是段部件的一个对应,是物理地址的一个映射)。
4. 流水线(Pipe-Line)
在8086时期,处理器已经有了指令预取队列,当指令执行时,如果总线总是空闲的(没有访问内存的操作),就可以在指令执行的同时预取指令并提前译码,这种做法可以大大地提升程序的执行速度。(原理就是利用处理器的不同指令大多不会再一个时钟周期内完成)。可以把一个指令分解成若干个细小的步骤,并分配给相应的段元来完成。每个单元的执行时独立的,并行的。这么做以后,每个步骤的执行就会在时间上重叠起来,这种执行指令的方法就是流水线技术。根据贪婪算法,流水线的执行效率受执行时间最长的那一级的限制,要缩短各级的执行时间。如果要缩短各级的执行时间,那么就要让每一级的任务减少,与此同时,就需要把一些复杂的任务再进行分解,如此,在2000年的时候Intel推出的Pentium处理器(采用NetBurst微结构,进一步分解指令的执行过程,采用31级超深流水线)。
5. 高速缓存(Cache)
因为与处理器的寄存器相比,内存的访问速度(几十ns)和硬盘的访问速度(几十ms)都非常低慢,所以人们就弄了一个高速缓存的机制,高速缓存说白了就是一个存储器(也是一个静态存储器,容量较小,但速度可以与处理器匹配。),当然这只是简单来说的,事实上高速缓存的实现是很复杂的,里面有很多计算的原理,不同CPU的实现还可能不一样,高速缓存利用了程序运行的时候,总是局部性的(比如访问刚刚访问过的指令或者数据,这被称为程序运行的局部性规律。)每当处理器要访问内存,首先检索高速缓存。如果要访问的内容已经在高速缓存中了,那么直接从高速缓存中获得,这被称为命中(Hit);否则,称为不中(Miss),在不中的情况下,处理器灾区的需要的内容前必须重新装载高速缓存,而不只是直接到内存中去哪个内容,高速缓存的装载是以块为单位的,包括那个所需数据的邻近的内容,为此需要额外的时间来等待块从内存载入高速缓存,在这个过程中损失的时间称为不中惩罚(miss penalty)。
6. 乱序执行(Out-Of-Order Executive)
为了执行流水线技术,需要降至零拆分成更小的可独立执行部分,即拆分成微操作(micro operations),简写为μops。
有些简单指令只用一个微操作,比如:
![]()
有些指令可以拆分成两个微操作,一个从内存中读取数据并保存到临时寄存器,另一个用于将EAX寄存器和临时寄存器的数值相加。
![]()
再比如:
![]()
这个可以拆分成三个微操作一个从内存中读数据,一个执行相加的动作,第三个用于将相加的结果写回到内存中。一旦将指令拆分成为操作,处理器就可以在必要的时候乱序执行,比如:

这里,指令mov [mem2],eax可以拆分成两个微操作,如此,在执行逻辑左移指令的同时,处理器可以提前从内存中读取mem2的内容,典型的,如果数据不在高速缓存中,那么处理器在获取mem1的内容之后,会立即开始获取mem2的内容,于是同时,shl指令已经开始执行了。同理,乱序执行可以大大加快如push,call等指令的执行速度。
7. 寄存器重命名
书上有一个例子:
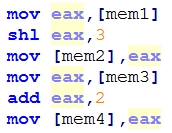
代码上做了两件事情,一个是将mem1的内容进行左移3个单位,另一个是将mem3的内容+2,如果将后面三个操作所用的寄存器名名称不同的名字,那么这个操作也不会被影响,所以处理器为最后三条指令使用了另一个不同的临时寄存器,因此左移和加法可以并行地进行。再比如:

假定现在mem1的内容在高速缓存中,可以立即取得,但mem2的内容不在高速缓存中,也就是说,算术左移可以在add之前就进行了,所以我们为左移设定一个新的临时寄存器,那么这样eax的内容认识以前的,他将一直保存着这个值,直到ebx的内容就绪,然后和它一同做加法运算。如果没有寄存器重命名机制,左移操作将不得不等待从内从中读取mem2的内容到EBX寄存器中以及加法操作。
在所有操作都完成后,那个代表EAX寄存器的最终结果的临时寄存器的内容被写入真实的EAX寄存中,该处理过程被称为引退(Retirement)。所有通用寄存器,栈指针,标志,浮点寄存器,甚至段寄存器都有可能被重命名。
8. 分支目标预测
如果遇到转移指令,那么后面那些进入流水线的指令将会无效,所以我们要清空流水线,那么为了解决这个问题,Intel引入了分支预测技术,因为程序中可能出现大量的循环,所以遇到转移指令(条件转移指令,loop等),处理器将会预测他下一次还会转移到某个标号处而不是往下执行,在处理器内部,有一个小容量的高速缓存器,叫做分支目标缓存器(Branch Target Buffer,BTB)。当处理器执行了一条分支语句后,它会在BTB中记录当前指令的地址,分支目标的地址,以及本次分支预测的结果,下一次,在转移指令实际执行前,处理器会查看BTB,看看有没有最近转移的记录,如果能找到对应的条目,则推测和上一次相同的分支,把改分支的指令送入流水线。如果预测失败,再清空流水线,刷新BTB。
★PART2:32位的x86系统的指令系统
1. 32位处理器的寻址方式
如果处理器在16位模式下,没有指令前缀0x66,则认为指令是传统的16位寻址方式,如果有指令前缀0x66,则是32位寻址方式,在32位模式下,没有指令前缀0x66,则认为指令是传统的32位寻址方式,如果有指令前缀0x66,则是16位寻址方式。指令默认使用32位宽度的寄存器和32位的立即数,如果存在内存寻址,则偏移量也是32位的。
32位模式下,内存寻址可以使用全部的32位通用寄存器作为基址寄存器,还可以加上一个除了ESP的32位通用寄存器作为变址寄存器,变址寄存器还可以允许乘以1,2,4和8作为比例因子。最后还可以在加上一个8位或者32位的偏移量。比如

2. 操纵数大小的指令前缀
每一条指令都可以拥有前缀,比如重复前缀(rep/repe/repne)、超越前缀指令(如ES:),总线封锁前缀(LOCK)等。前缀是可选得,每个前缀的长度是1个字节,每个指令都可以拥有0-4个前缀。

16位模式下的编码格式和32位的编码格式是一样的,但是解释是不同的,所以编写的时候就要考虑指令的运行环境,为了指明程序的默认运行环境,编译器提供了伪指令bits,用于指明其后的指令应该被编译成16位的,还是32位的(16位模式是默认的编译模式,如果没头指定指令的编译模式,则默认是16bits的)。
3. 一般指令的拓展
32位处理器拥有32位寄存器和算术逻辑部件。而且系统内存芯片之间的数据通路至少是32位的,所有寄存器或者内存单元为操作数的指令都被扩充,这些拓展操作即使是在16位模式下(实模式或者保护模式)都是可以用的,比如最简单的加法指令。

压栈出栈的操作比较特殊。
压入一个字节立即数,则无论是在16位模式下或者是32位模式下,一定要使用byte,关键字byte在push和pop操作上是不会给机器码加上指令前缀的,但是执行的时候,无论什么时候,push(pop)都不会压入(弹出)一个字节的数据,在16为模式下,这两个指令使用SP指针,按照有符号数的规则填充到字节的高八位,然后压栈(弹出),32位使用ESP,按照有符号数的规则填充到高24位再压栈(弹出)。
如果要压入一个字立即数,则无论是在16位模式下或者是32位模式下,一定要使用前缀word,在16位模式下,执行push操作,SP先-2,然后直接压入该字;在32位模式下,会填充字的高16位(按照有符号数的规则),ESP相应-4,然后压入双字,pop操作类似。
如果要压入一个双字立即数,则无论是在16位模式下或者是32位模式下,一定要使用dword,而且栈指针寄存器(SP或者ESP)都要-4。pop类似。
(压入(弹出)通用寄存器可以不用关键字byte,word,dword修饰,内存单元一定要关键字byte,word,dword修饰,处理器压入内存操作行为和压入立即数的行为是一样的)。
压入段寄存器的时候,在16位模式下,先将SP的内容-2,然后直接压入;如果是在32位模式下,则会先将段寄存器的内容用0拓展到32位(高16位全是0),然后,将ESP的内容减去4,然后再压入拓展后的32位的值。(段寄存器能用的只有16位)。