线程拥有寄存器,用来保存当前的工作变量;线程有自己的栈堆,用来保存上下文,在同一个进程当中,允许拥有较大独立性多个线程,是对一个计算机上多个进程的模拟,在单核CPU中,每个线程分配的CPU速度的V/N。
线程实现方式
1. 用户级线程(多对一):
把线程表放在用户空间中,切换快。在用户空间中可以防止某些垃圾回收程序过早退出。
缺点:无法在系统级上实现调度,无法方便地实现阻塞型系统调用(因为如果当一个线程发起阻塞型调用而阻塞时,其他线程必定会阻塞,内核并不能看到用户线程,也就无法调度)。
->用户级线程的调度程序激活机制:
内核给每一个进程安排一定数量的虚拟处理器,让用户空间线程分配到这些处理器上,当一个线程被阻塞时,则内核通知该线程的运行时系统,并且在堆栈上以参数的形式传递有问题的线程编号和所发生的时间的描述(这种方法被称为是上型调用upcall),交给运行时系统自行判断。
如果发生系统调用,同样会引发上行调用,此时运行时系统决定调度哪个线程:被中断的线程,新的就绪线程或者还是第三个线程。
2. 内核级线程(一对一):
把线程表放在内核空间中,每撤销一个线程即执行一次系统调用。
缺点:开销很大。
3. 混合实现(多对多):
采用这种方法,内核只是别内核级线程并且对其进行调度,其中一些内核及县城会被多个用户级线程多路复用。而每个内核级线程都有一个可以轮流使用的用户级线程的集合。
缺点:难以实现。
Linux线程实现例子:LiunxThreads与NPTL(Native POSIX Threads Library)
一. LinuxThreads的线程机制
LinuxThreads是目前Linux平台上使用最为广泛的线程库,由Xavier Leroy (Xavier.Leroy@inria.fr)负责开发完成,并已绑定在GLIBC中发行。它所实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库中实现。(LinuxThreads的详细介绍https://www.ibm.com/developerworks/cn/linux/kernel/l-thread/。)
大体上说,LinuxThreads用一个数据结构体来描述线程,并且定义了两个全局系统线程__pthread_initial_thread和__pthread_manager_thread,并用__pthread_main_thread表征__pthread_manager_thread的父线程(初始为__pthread_initial_thread)。
__pthread_manager_thread顾名思义是来管理线程的,而且LinuxsThreads为每一个进程都构造了管理线程。管理线程与其他线程之间用管道进行通讯。在LinuxThreads中,管理线程的栈和用户线程的栈是分离的,管理线程在进程堆中通过malloc()分配一个THREAD_MANAGER_STACK_SIZE字节的区域作为自己的运行栈。并且每一个线程都同时具有线程ID好进程ID,其中进程ID就是内核所维护的进程号,而线程id则是由LinuxThreads分配和维护的。
LinuxThreads的不足
由于Linux内核的限制以及实现难度等等原因,LinuxThreads并不是完全POSIX兼容的,并且linux内核也不支持真正意义上的线程,LinuxThreads是用与普通进程具有同样内核调度视图的轻量级进程来实现线程支持的。无法实现所有线程应该共享一个进程id和父进程id。
由于异步信号是内核以进程为单位分发的,而LinuxThreads的每个线程对内核来说都是一个进程,且没有实现"线程组",如果核心没有提供实时信号,那么SIGUSR1和SIGUSR2这两个信号无法使用。(在Linux kernel 2.1.60以后的版本都支持扩展的实时信号(从_SIGRTMIN到_SIGRTMAX))。某些信号的缺省动作难以在现行体系上实现,比如SIGSTOP和SIGCONT,LinuxThreads只能将一个线程挂起,而无法挂起整个进程。正因为LinuxThreads是内核基于进程的模拟,所以它的兼容性也很差,而且不支持调度。
因为LinuxThreads的管理线程方式,以及线程同步方式极大地制约了LinuxThreads的性能。管理线程这种结构本身效率不高,并且管理线程有一个巨大的缺陷:一旦管理线程死亡,线程将无法处理;在线程同步上,LinuxThreads中的线程同步基于信号,必须通过内核的复杂处理,效率一直是个问题。
二. Linux NPTL线程管理机制
上面所讲到的LinuxThreads由于性能比较差,所以现在高版本的内核已经不用LinuxThreads了,现在使用的是NPTL(Native POSIX Threads Library)的方式来实现线程,NPTL是一对一的内核态线程的实现。
NPTL相比于LinuxThreads有很大的性能提升。首先NPTL 没有使用管理线程,避免了创建管理线程所占用的线程,同时NPTL完全兼容POSIX,实现了在一个进程中所有的线程都是一样的UID和GID(需要信号支持,并且这些信号不能用在用户程序上,不过POSIX定义了一些包装函数防止误用。)
其次NPTL可以采用Futex(Fast Userspace Mutexes)来进行线程原子性同步,我们从这个东西的名字就可以知道,这种互斥锁是定义在用户空间的,避免了陷入内核带来的性能损耗问题。
在http://www.akkadia.org/drepper/nptl-design.pdf这份草安装,我们可以看到NPTL对于LinuxThreads有多大的提升
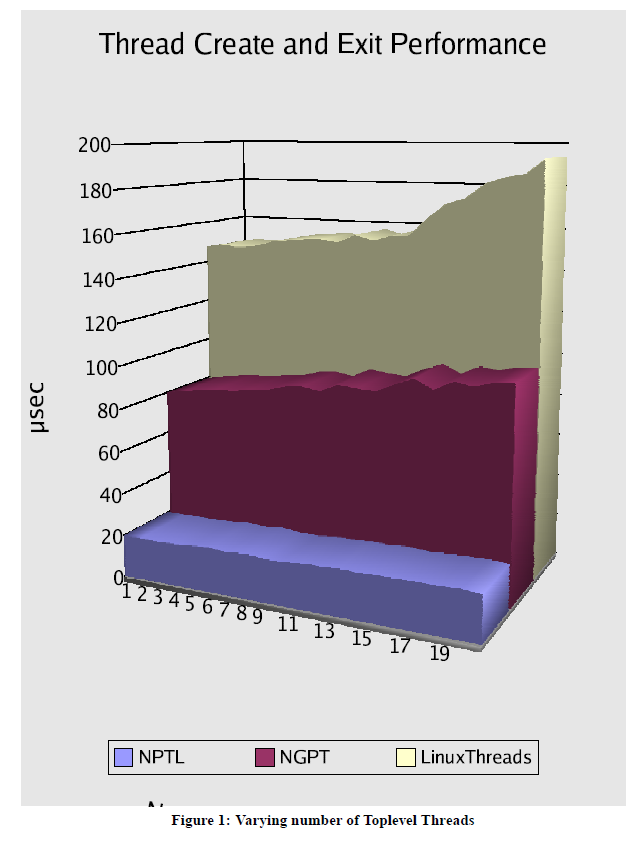
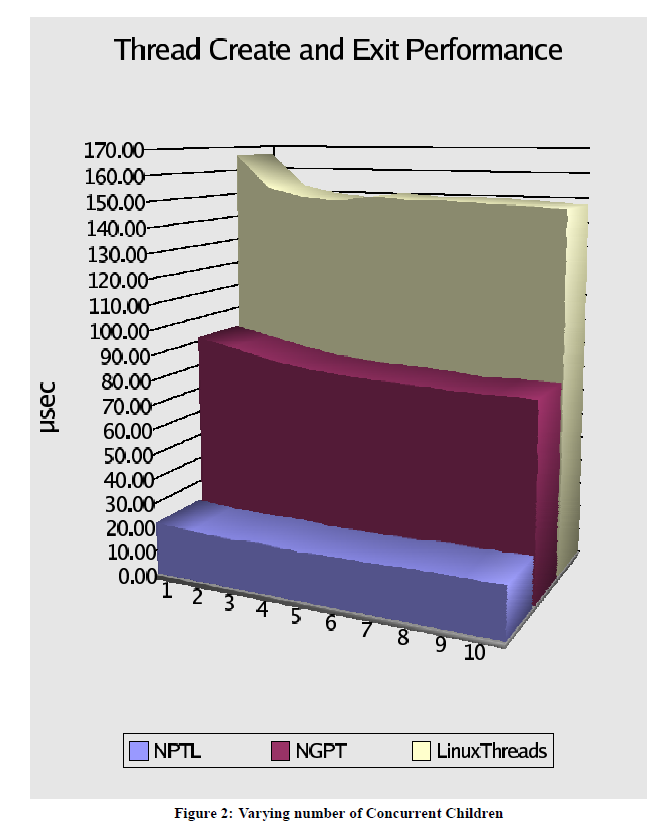

一些特别的线程
1. 弹出性线程
一个消息导致系统创建一个处理该消息的线程,这种线程被称为是弹出式线程,弹出式线程没有历史,没有必须存储的寄存器,栈堆等东西,执行非常快。一般在内核空间中实现弹出式线程,因为此时弹出式线程可以访问到所有的系统信息额I/O设备,在处理中断的时候很有用。
2. 纤程
在一个抢占式系统中,普通的线程可能会被打断,其一些信息会被保留下来(即使不是完整的),但是对于纤程,其启动和停止都是确定的,这就意味着他不需要历史,不需要上下文切换,避免了上下文切换带来性能损失。纤程一般在用户态空间实现。
3. 协程
协程当用户态线程需要自己调用某个方法来主动地交出控制权,我们就称为这样的线程是协作式的,即协程。注意协程不需要操作系统陷入内核开线程,协程的实现是在用户空间实现的,避免CPU以陷入内核的方式切换线程带来的性能损耗问题,有效减少线程数,而且同时降低内存的使用率,提高CPU命中率,也提高了系统整体效率。
协程可以实现异步代码(需要语言支持),比如.NET的异步编程(再也不用写callback了)
async void func() { ... await someAsyncfunction();//此处交出控制权异步执行代码 ...//异步执行代码返回点(与) }
一些特别的线程线程的临界区保护
当两个线程要访问同一个变量的时候,就会发生竞争,此时需要线程同步,线程同步的关键就是要解决临界区的问题。
解决竞争问题,要遵循下面的原则:
任何两个进程/线程不能同时处于临界区不应该对CPU的速度和数量进行假设临界区外执行的进程/线程不能被阻塞不得让进程无限制地等待进入临界区
1. Peterson解法解决竞争问题(忙等待方式,消耗CPU资源,但是很巧)
#define FALSE 0 #define TRUE 1 #define N 2 int turn; int interested[N]; void enter_region(int process) { int other; otehr = 1 - process; interested[process] = TRUE; turn = process; while (turn == process && interested[otehr] == TRUE); } void leave_region(int process) { interested[process] = FALSE; }
当两个进程/线程同时进入函数时,后进入的一方会覆盖掉先进入一方的turn值,导致后进入一方被阻塞,而先进入一方则不会被阻塞而进入临界区, 直到退出后,后进入一方便可进入临界区了。
2. TSL指令(原子锁,同样也是忙等待)
enter_region: TSL REGISTER,LOCK CMP REGISTER, #0 JNE enter_region RET leave_region: MOV LOCK, #0 RET
不过intel CPU的底层同步并不用TSL指令,而是直接用的交换:
enter_region: MOV REGISTER,#1 XCHG REGISTER, LOCK CMP REGISTER, #0 JNE enter_region RET leave_region: MOV LOCK, #0 RET
3. 信号量
信号量是相当经典的线程同步的部件了,信号量有两个操作
down操作:使信号量计数-1,当信号量为0时则阻塞当前线程,直到信号量大于0为止。
up操作:使信号量计数+1,永远不会阻塞线程。
4. 互斥量与条件变量
互斥量是信号量的简化版,互斥量只有上锁和解锁两个状态,互斥量可以用TSL指令实现
mutex_lock: TSL REGISTER,MUTEX ;将互斥量复制到寄存器,并且将互斥量置1 CMP REGISTER,#0 JZE ok ;如果互斥量是0,那么直接跳出(顺便还锁上了) CALL thread_yield ;否则进行调度 JMP mutex_lock ;返回调用者,进入临界区 ok: RET mutex_lock: MOV MUTEX, #0 RET
通常互斥量和条件变量一起使用,条件变量用于绑定一个互斥量,并且当条件满足时,发出信号,让被锁住的线程继续执行(看下面生产者与消费者的例子)。
5. 管程
管程其实就是简化了互斥量的使用的工具,需要语言支持,在Java里面使用的是synchronized的方法,而在C#中,也可以像Java一样,使用[MethodImpl(MethodImplOptions.Synchronized)]。
6. 消息传递
这是Unix的经典方法了,在Unix网络编程的卷二里面又讲到,有点类似于TCP之间的传递信号,一个线程send,另一个receive。
7. 屏障
其实屏障我觉得不是严格的线程同步,比如有一个多线程的矩阵乘法操作,当屏障开启时,只有当所有的线程/进程完成工作后,才会执行下一次工作。
经典线程同步问题
1. 生产者消费者问题
生产者消费者问题:假设有一个生产者生产产品,有一个消费者消费产品,如何做到线程同步? 其实这个问题在所有的编程书上,只要涉及到多线程都会有的题目。
用信号量解决
typedef int semaphore; semaphore mutex = 1; semaphore empty = N; semaphore full = 0; void product(void) { int item; while(1) { item = product_item(); down (&empty); down (&mutex); insert_item(item); up(&mutex); up(&full); } } void cosumer(void) { int item; while(1) { down(&full); down(&mutex); item = remove_item(); up(&mutex); up(&empty); comsume_item(item); } }
注意上锁和解锁的顺序,一定要按照先入后出的方法,不然会造成死锁
用条件变量和信号量解决
#define MAX 1000; pthread_mutex_t mutex; pthread_cond_t condc, condp; int buffer = 0; void *producer(void *ptr) { int i; for (i = 0; i < MAX;i++) { pthread_mutex_lock(&mutex); while(buffer != 0) pthread_cond_wait(&condp, &mutex); //此时阻塞线程 buffer = i; pthread_cond_signal(&condc); //唤醒消费者线程 pthread_mutex_unlock(&mutex); } pthread_exit(0); } void *consumer(void *ptr) { int i; for (i = 0; i < MAX;i++) { pthread_mutex_lock(&mutex); while( buffer == 0) pthread_cond_wait(&condc, &mutex); buffer = 0; pthread_cond_signal(&condp); pthread_mutex_unlock(&mutex); } pthread_exit(0); }
用消息传递解决
下面的例子,用的是信箱法,当线程试图向一个满的信箱发信息时,它将会被阻塞,直到有消息被取走
#define N 100 void producer(void) { int item; messgae m; while(1) { item= produce_item(); recieve(comsumer, &m); build_message(&m,item); send(comsumer, &m); } } void comsumer(void) { int item,i; message m; for (i = 0; i < N; i++) send (producer, &m); //发N条空信息给生产者填充,如果不使用缓冲,发一条信息则会被阻塞,如果使用缓冲,则不会被阻塞,而发出去的信号会被缓冲区接受。 while (1) { recieve(producer, &m); item = extract_item(&m); send (producer, &m); comsume_item(item); } }
2. 哲学家就餐问题
哲学家思考问题解决的是互斥访问有限资源的问题:有N个哲学家坐在一张圆桌子旁边,只有N个叉子,当哲学家觉得他饥饿了,就会拿起他旁边的两个叉子,且不分次序,成功拿起叉子后就会吃饭,吃完后就会放下叉子进行思考。如果旁边的叉子被拿起,则哲学家就等待叉子被放下后再拿起。
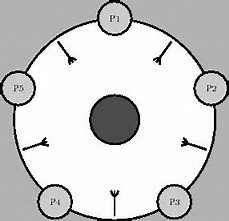
这是个很经典的IPC问题,一个很好的解法如下(而且有很好的并行度)
#define N MAX #define LEFT (i + N - 1)%N #define RIGHT (i + 1)%N #define THINKING 0 #define HUNGRY 1 #define EATING 2 typedef int semaphore int state[N]; //哲学家状态 semaphore mutex = 1; semaphore s[N]; //哲学家 void take_forks(int i) { down(&mutex); state[i] = HUNGRY; test(i); up(&mutex); down(&s[i]); //哲学家得不到叉子阻塞,如果得到了就不会阻塞(up过了) } void put_forks(int i) { down(&mutex); state[i] = THINKING; test(LEFT); test(RIGHT); up(&mutex); } void test(int i) { if (state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] != EATING) { state[i] = EATING; up(&s[i]); } }
3. 读写锁问题
读写锁的经典例子就是数据库的访问,《现代操作系统》里面就有一段这样的例子代码,但是这种读写锁的实现方式效率非常低下,而且是读者优先的解法。
typedef int semaphore semaphore mutex = 1; semaphore db = 1; int rc = 0; //由mutex保护 void writer(void) { while(1) { think_up_data(); down(&db); write_data(); up(&db); } } void reader(void) { while(1) { down(&mutex); rc = rc + 1; if (rc == 1) down(&db); //这里就体现读者优先了 up(&mutex); read_data(); down(&mutex); rc = rc - 1; if (rc == 0) up(&db); up(&mutex); use_data_read(); } }
《现代操作系统 第三版》 -Andrew S. Tanenbaum