空洞卷积:
2020-02-15
1.偏置参数个数
2d卷积时,如果设置该层偏置有效,偏置参数个数= 输出通道数目。
2.2d卷积分组个数限定
分组个数一定要能被输入通道整除,并且要能被输出通道整除。
输入通道整除原因:因为 输入通道/ 分组数目 要=整数。不等于整数时会发生。余数通道怎么处理问题。
输出通道整除原因:不能整除会发生每个通道卷积次数不一致问题。
比如 输入通道是6,分组是3 ,卷积大小3.如果输出通道是7 。 单卷积核通道数6/3 = 2个通道。 输出通道是7。这时,每个输出通道相当于 卷(3*3)*2 的卷积核。总共需要14(7*2)个通道,但是原图是6通道。这时候同样发生 剩余通道归属问题。相反,当卷积数目能整除通道数目时,有如下公式 (卷积数目)*单卷积核通道数目= (x *分组数)*单卷积核通道数目= x*输入通道数目 。不会发生多余通道归属问题,对于输入通道的每个通道都是均衡的,不存在某些通道过重偏移。
2020-02-21
信息处理问题角度触发观点
1.信息瓶颈:https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%93%B6%E9%A2%88/22761215?fr=aladdin
信息从多到少,少到多。如自编码。
2.稠密信息转稀疏信息。
如猫狗识别,手写数字识别。 输入的图片(像素数目), 输出的是几个类别。
3.稀疏信息转稠密信息
如:生成网络。 输入长发,短发,生成图像。目前还不够火。
4.稠密转稠密信息
自编码。语音转文字;文字转语音
----------------------------------------------------------------------------------------------------------------
池化作用1:池化能快速的减少无用特征。适合稠密信息转稀疏信息过程。卷积大步长效果类似池化,但是池化更快。但是。
稀疏信息转稠密信息不适合使用池化。注意有反池化。但是反池化和池化不是一回事,一般反池化称为上采样。
最大池化:网络的中间及前面部分使用最大池化。最大池化一般用于提取前景信息,尽快的体现数据的(特征差异)。前景信息差异大。
平均池化:网络结尾一般使用平均池化或者不用。平均池化提取背景信息。类似概率论中,平均池化相对就是取均值,代表所有点的整体中心。
池化作用2:平移不变性。类似一副网格尺图像 ,直接最近邻缩小,可能出现线断断续续。 但是如果缩小的点在原图映射点,一定范围内做高斯滤波,然后决定值。就不易出现线断掉。
(1)邻域大小受限造成的估计值方差增大,mean能减小这种误差。
(2)卷积层参数误差造成估计均值的偏移,max能减小这种误差。
---------------------------------------------------------------------------------------------------------------------------------------------------
归一化
BatchNormal 2015年提出。之前是手动调参,手动去调参数的正态分布(期望,方差)来初始化参数,来控制输出值范围。
BatchNormal 用在权重相乘之后, 激活函数之前。虽然有relu(),但是BatchNormal,至少能保证梯度不会消失或爆炸。
https://www.sohu.com/a/256793035_100285715
解决梯度弥散方式:1)残差;2)批量归一化。解决梯度爆炸方式:1)批量归一化
延缓梯度弥散方式:除了上面还有 relu()。 延缓梯度爆炸方式:减少学习率,初始化权重
(1) 首先减去均值,除方差,归一化(0,1)的正太分布。 分母+一个系数,是防止分母为零,接近0的数(比如期望和x全部一致)
(2) γ,β是因为 归一化后的分布,不一定和激活函数一致。并且数据分布也和期望的分布有差别。注意这俩个参数在训练过程中是要训练的。
注意,γ,β大多数情况下需要。他们起到的作用是将数据分布推进到真实的概率分布。
注意:训练的时候,网络会自动调用"train()"。 评估的时候需要手动调用“eval()” 。才能正确使用。
batchNormal 在批次上,对(N,H,W)上做归一化。一般用在训练的时候,保证系数的稳定性,加速网络找特征的不同点。帮助网络提取特征。因此特征点要比较多,归一化效果才好。批次太少的话,相当于每次采样点少,不足于每次接近体现真实概率。可能是局部,反倒引起震荡。(此时可能用组归一化Group Normalization)
InstanceNormal 在图像像素上,对HW做归一化。控制每个通道之间的差异。控制的全局特征,大体风格。对整体风格进行转换。如秋天变冬天。
LayerNormal 是在通道方向上,对C,H,W做归一化。控制的是细节(形状细节)。如:瘦脸 …… 。在RNN上做自然语义时,提示明显。
参考资料:https://blog.csdn.net/liuxiao214/article/details/81037416
2020-02-24
欠拟合:欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
过拟合:为了得到一致假设而使假设变得过度严格称为过拟合。
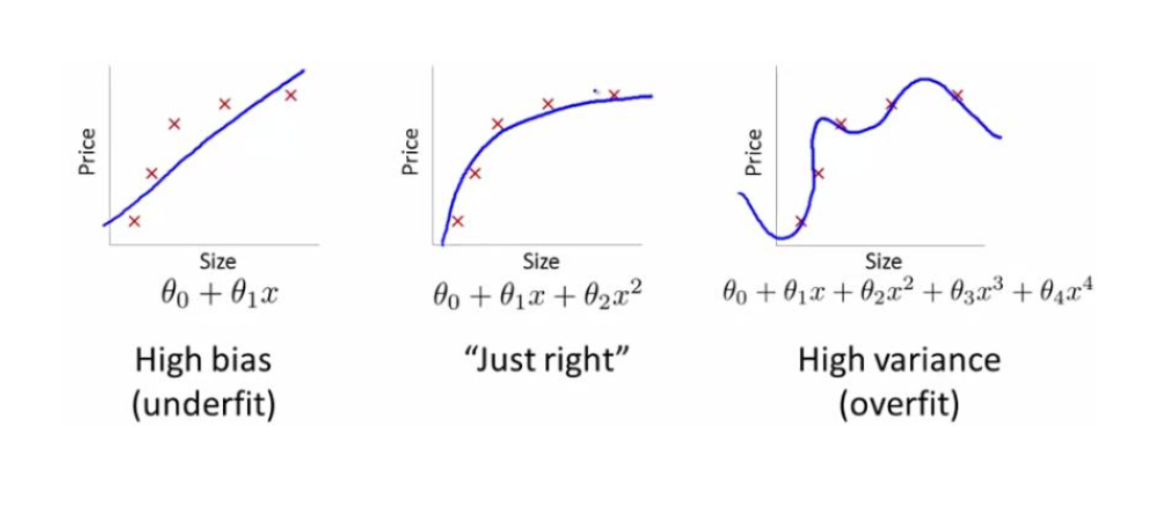
欠拟合:数据和训练次数,相对于特征参数来说不足。
过拟合:解决方法,L1,L2正则化,dropout。丰富样本多样性。
3)用先验知识,比如侦测无人机,要检测无人机,框一个框,yolo就提出一个“建议框”,通过先给约束,来极大提升训练速度。
另一种加入大量数据量(类似抛硬币,抛的次数多了就接近主要)。这时候可以理解数据独立同分布。这时候加数据,其实是独立同分布增加抛硬币次数,加入数据和之前数据相对于已经学习到的特征共同特征减少。注意这种方法,有时候不可行。因为样本采集有成本。
4)把网络变笨:减少参数量?正则化
设计好一个神经网络,这个网络大概需要多少的数据量?
至少来说 1个权重对应1个特征
IID独立同分布问题:一般
一般情况下 数据量至少是网络参数的10倍。才能有比较好的效果。数据与数据之间存在大量重叠的信息,所以不是简单的1:1关系。
数据量过大,网络过少,容易出现欠拟合。
L2正则化:w平方。导数是2W。 整个变化过程是比较平滑的。很难降到0。
L1正则化:|W|。导数是1,到最后会震荡。L1会把权重压到0 。到0会导致权重不会再更新。,避免梯度消失。
所以深度学习,几乎都用L2正则化
Dropout:是在当前批次中,随机的抑制神经元,让其不参与训练。
之所以在测试的时候要显示调用“eval”是为了告诉网络,这时候所有神经元都要参与计算。
Dropout一般放在激活前面。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2020-03-06
变分自动编码器(VAE):13年出现 。缺点边缘信息比较模糊。换脸比较成功