函数递归
即函数在调用阶段,直接或间接的又调用自身。
补充
# 查看函数支持的递归上限 import sys print(sys.getrecursionlimit()) # 不是很精确 # 一般返回的是1000 sys.setrecursionlimit(2000) # 如果想要修改递归的上限,可以用这个方法改到2000
函数不应该无限制的递归下去
递归分为两个阶段
1.回溯:就是一次次重复的过程,这个重复的过程必须建立在每一次重复问题的复杂度都应该下降
到有一个最终的结束条件
2.递推:一次次往回推导的过程
age(n) = age(n-1) + 2 # n > 1 age(1) = 18 # n = 1 # 递归函数 def age(n): if n == 1: # 必须要有结束条件 return 18 return age(n-1) + 2 res = age(5) print(res) # 26
l = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,[11,[12,[13,]]]]]]]]]]]]] # 将列表中的数字依次打印出来(循环的层数是你必须要考虑的点) def get_num(l): for i in l: if type(i) is int: print(i) else: get_num(i) # 这里递归调用自己,就能达到循环的目的 get_num(l)
二分法
算法:解决问题的高效率方法
l = [1,2,4,65,76,123,156,157,235,256,278,301,324,786] target_num = 66 # 这两个是初始的参数 def get_num(l,target_num): print(l) # 有了这句,每次查找,拆分了列表,都会打印一下列表 middle_index = len(l)//2 # 这里的l之后会被l_left或者l_right替代 # 这样,每次的middle_index都是当前列表的中间的那个 if not l: # 这个写法代表判断如果target_num不在列表l里的话 print('这个表里没有') return # 如果执行到这句,那他的返回值就是None if target_num > l[middle_index]: l_right = l[middle_index+1:] # 这里注意既然target_num比l[middle_index]大了, # 那么,l[middel_index]就可以排除掉了,直接从l[middle_index+1]开始比较 get_num(l_right,target_num) # 这样就是把l_right当做原来的l传进去了。 # 这里就是递归调用 elif target_num < l[middle_index]: l_left = l[:middle_index] get_num(l_left,target_num) else: print('find it',l[middle_index]) get_num(l,target_num) # 调用这个函数 # 给这个函数传入两个参数,也就是最上面的两个


[1, 2, 4, 65, 76, 123, 156, 157, 235, 256, 278, 301, 324, 786] [1, 2, 4, 65, 76, 123, 156] [76, 123, 156] [76] [] 这个表里没有
[1, 2, 4, 65, 76, 123, 156, 157, 235, 256, 278, 301, 324, 786] [1, 2, 4, 65, 76, 123, 156] [76, 123, 156] [76] find it 76
以上就是二分法的简单应用,二分法可以说是算法里最简单的一种了。
使用恰当的算法,无疑是可以提高工作效率的。
三元表达式
三元表达式的应用场景比如在以下情况:
要输出两个数里比较大的那个,平常我们需要这么写:
def my_max(x,y): if x > y: return x else: return y
但是,如果你使用了三元表达式,就可以精简成这样:
def my_max(x,y): res = x if x > y else y # 如果if后面的条件成立返回if前面的值 否则返回else后面的值 print(res)
三元表达式固定表达式 值1 if 条件 else 值2 条件成立 值1 条件不成立 值2
# 三元表达式的应用场景只推荐只有两种的情况的可能下 is_free = input('请输入是否免费(y/n)>>>:') is_free = '免费' if is_free == 'y' else '收费' print(is_free) username = input('username>>>:') res = 'NB' if username == 'jackMa' else 'normal' print(res)
列表生成式
当你想对列表里的字符做统一处理(比如统一加上一些字符)
常规的做法是利用for循环
l = ['bike','car','olen','gulu'] l1 = [] for i in l: l1.append('%s_new'%i) # 这里append里如果用语句(name + '_sb')也能达到一样的效果 # 但不推荐这么做,因为python执行字符串加法的效率太低了 print(l1) >>> ['bike_new', 'car_new', 'olen_new', 'gulu_new']
而如果使用列表生成式的方法
l = ['bike','car','olen','gulu'] res = ['%s_new'%name for name in l] # 只需要这一行就能完成功能 print(res)
列表生产式应用2
取出以下列表中以‘_old’结尾的函数
l = ['bike_old', 'car_new', 'olen_old', 'gulu_new'] res = [name for name in l if name.endswith('_old')] # 后面不支持再加else的情况 # 先for循环依次取出列表里面的每一个元素 # 然后交由if判断 条件成立才会交给for前面的代码 # 如果条件不成立 当前的元素 直接舍弃 print(res) >>> ['bike_old', 'olen_old']
字典生成式
需求:将l1 的值作为key,l2 的值作为value,生成一个字典
如果用enumerate方法:
l1 = ['name', 'password', 'hobby'] l2 = ['bitten', '123', 'cook', 'hikiiiiiing'] d = {} for index, element in enumerate(l1): # 这一步是把l1的索引和元素都取出来 print(index,element) # 这一步只是演示,把取出的索引和元素打印出来 # 并且注意,这里将l1的索引也取出来了,接下来要和l2一一对应的话, # l1里的值的个数(l1的索引)必须<=l2里值的个数(l2的索引) d[element] = l2[index] # 这里运用的是字典赋值的方法,将l1中取出的元素作为key传入字典d, # 并将l2里的值按照l1中取出的索引的顺序,传入字典d中与d中传入的key一一对应 print(d)
0 name # 演示那一步的结果 1 password 2 hobby {'name': 'jason', 'password': '123', 'hobby': 'DBJ'} # 最后结果,(再次强调,当key的那个列表的值的个数要小于当value的那个列表里值的个数)
或者这么写:
l1 = ['name', 'password', 'hobby'] l2 = ['bitten', '123', 'cook'] dict0={} for i,j in enumerate(l1): for k,z in enumerate(l2): dict0[j]=l2[i] print(dict0)
#################思考(没解决):为什么这么写不行?#####################
# 需求:将l1中的元素作为key,将l2中的元素作为value,输出为字典 l1 = ['name', 'password', 'hobby'] l2 = ['bitten', '123', 'cook'] dict1 = {element1:element2 for index1,element1 in enumerate(l1) for index2,element2 in enumerate(l2) if True} print(dict1)
使用字典生成式:
需求:将列表转换成字典,并且去掉元素等于123的情况
l1 = ['bitten','123','cook'] d = {i:j for i,j in enumerate(l1) if j != '123'} print(d) >>> {0: 'bitten', 2: 'cook'}
元组生成式
res1 = (i for i in range(10) if i != 4) # 这样写不是元组生成式 而是生成器表达式 print(res1) # <generator object <genexpr> at 0x1069205c8> for i in res1: print(i) # 输出的是一行一个元素的0-9 #说明res1里面是有元素的
匿名函数
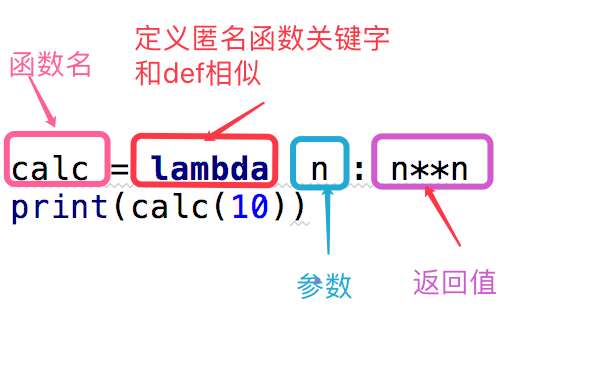
即没有名字的函数
特点:临时存在,用完就没了
需求:定义一个函数,将传入的两个参数,相加后输出
普通(有名字的)函数:
def my_sum(x,y): return x + y
匿名函数:
res = (lambda x,y:x+y)(1,2) print(res) # 或者 func = lambda x,y:x+y print(func(1,2)) # :左边的相当于函数的形参 # :右边的相当于函数的返回值 # 匿名函数通常不会单独使用,是配合内置函数一起使用
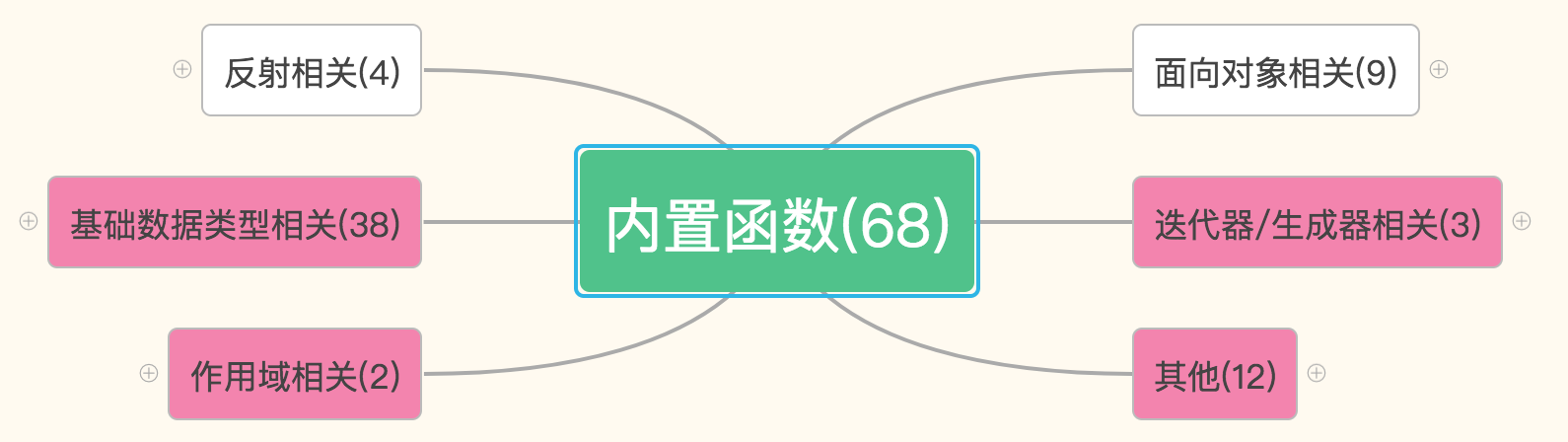
常用的内置函数
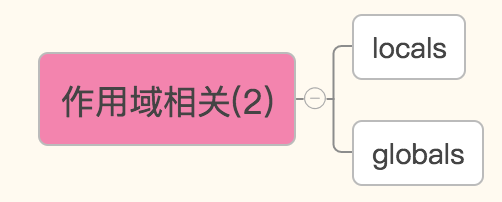
作用域相关
# 这是我们在前面的作用域中介绍过的
https://www.cnblogs.com/PowerTips/p/11165933.html
基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典
其他
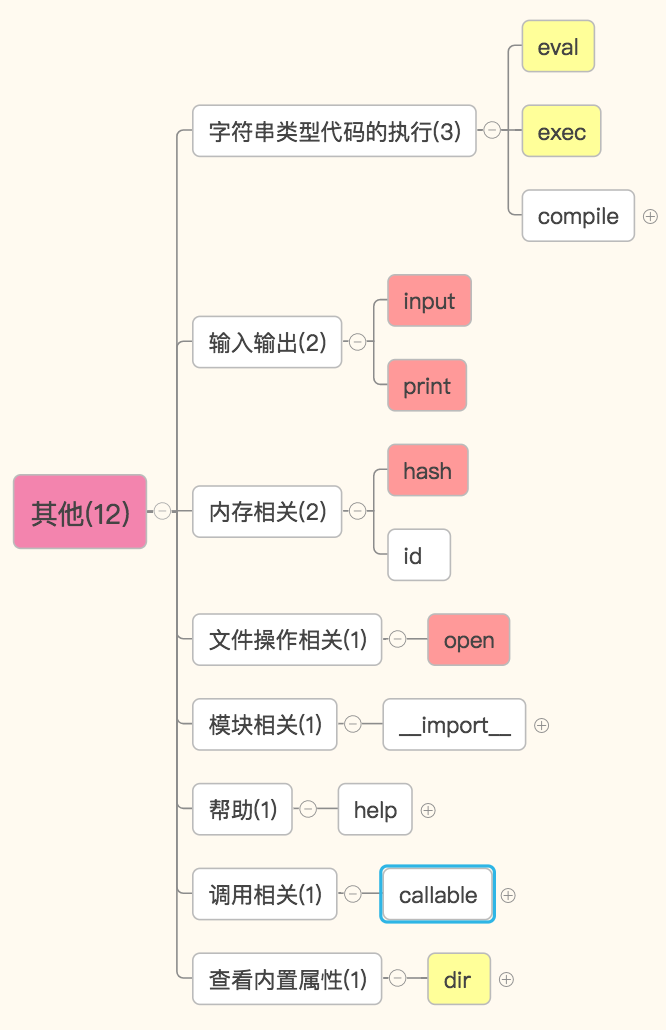
和数字相关
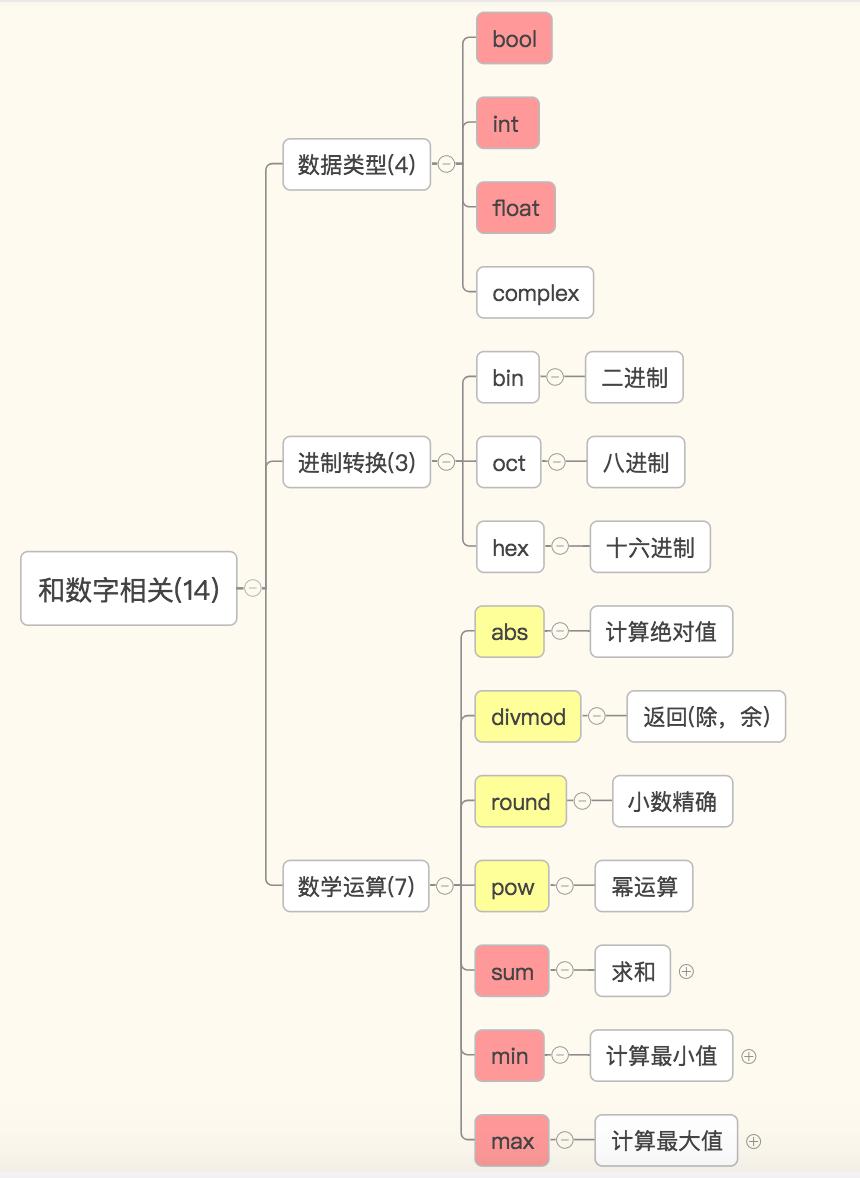
max函数
# 即取最大的值 l = [1,2,3,4,5] print(max(l)) # 内部是基于for循环的
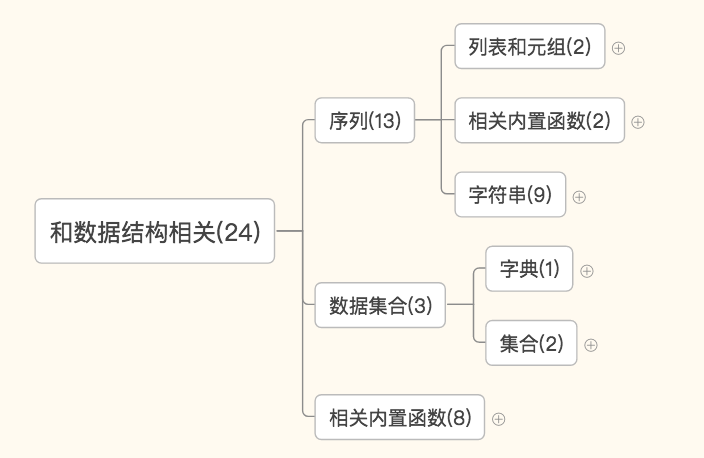
和数据结构相关